kafka的server.properties配置文件参考示范(图文详解)(多种方式)
简单点的,就是
kafka_2.11-0.8.2.2.tgz的3节点集群的下载、安装和配置(图文详解)
但是呢,大家在实际工作中,会一定要去牵扯到调参数和调优问题的。以下,是我给大家分享的kafka的server.properties配置文件参考示范。
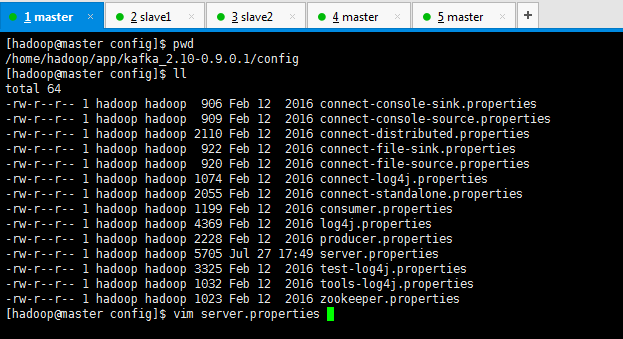
[hadoop@master config]$ pwd
/home/hadoop/app/kafka_2.10-0.9.0.1/config
[hadoop@master config]$ ll
total 64
-rw-r--r-- 1 hadoop hadoop 906 Feb 12 2016 connect-console-sink.properties
-rw-r--r-- 1 hadoop hadoop 909 Feb 12 2016 connect-console-source.properties
-rw-r--r-- 1 hadoop hadoop 2110 Feb 12 2016 connect-distributed.properties
-rw-r--r-- 1 hadoop hadoop 922 Feb 12 2016 connect-file-sink.properties
-rw-r--r-- 1 hadoop hadoop 920 Feb 12 2016 connect-file-source.properties
-rw-r--r-- 1 hadoop hadoop 1074 Feb 12 2016 connect-log4j.properties
-rw-r--r-- 1 hadoop hadoop 2055 Feb 12 2016 connect-standalone.properties
-rw-r--r-- 1 hadoop hadoop 1199 Feb 12 2016 consumer.properties
-rw-r--r-- 1 hadoop hadoop 4369 Feb 12 2016 log4j.properties
-rw-r--r-- 1 hadoop hadoop 2228 Feb 12 2016 producer.properties
-rw-r--r-- 1 hadoop hadoop 5705 Jul 27 17:49 server.properties
-rw-r--r-- 1 hadoop hadoop 3325 Feb 12 2016 test-log4j.properties
-rw-r--r-- 1 hadoop hadoop 1032 Feb 12 2016 tools-log4j.properties
-rw-r--r-- 1 hadoop hadoop 1023 Feb 12 2016 zookeeper.properties
[hadoop@master config]$ vim server.properties
master节点上
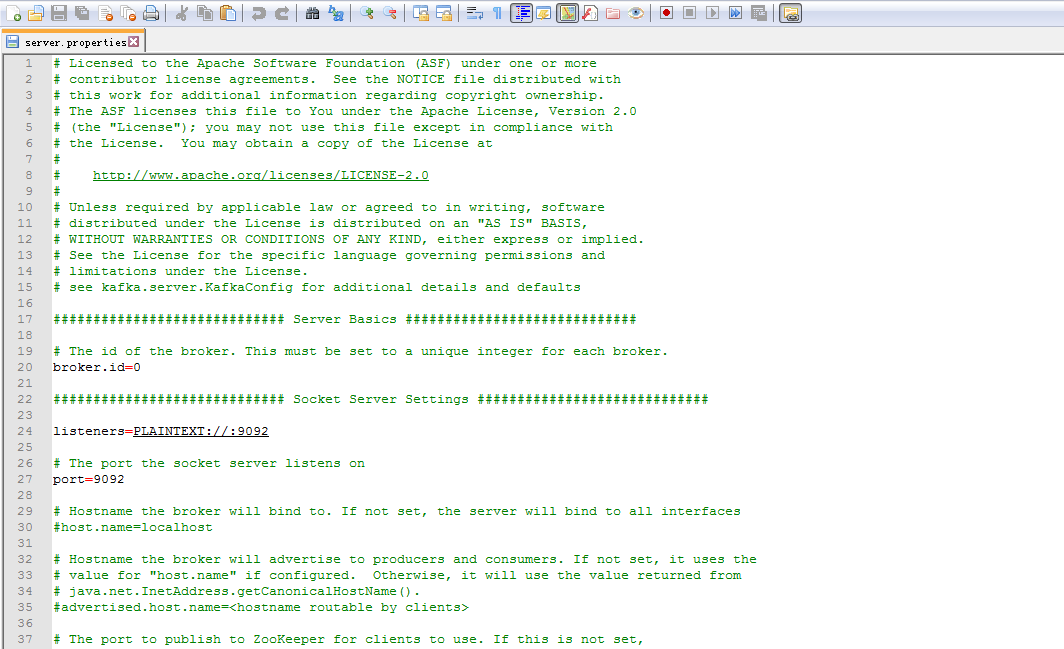
# Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # see kafka.server.KafkaConfig for additional details and defaults ############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker. broker.id=0
############################# Socket Server Settings ############################# listeners=PLAINTEXT://:9092 # The port the socket server listens on port=9092 # Hostname the broker will bind to. If not set, the server will bind to all interfaces host.name=master # Hostname the broker will advertise to producers and consumers. If not set, it uses the # value for "host.name" if configured. Otherwise, it will use the value returned from # java.net.InetAddress.getCanonicalHostName(). #advertised.host.name=<hostname routable by clients> # The port to publish to ZooKeeper for clients to use. If this is not set, # it will publish the same port that the broker binds to. #advertised.port=<port accessible by clients> # The number of threads handling network requests #num.network.threads=10 # The number of threads doing disk I/O #num.io.threads=12 # The send buffer (SO_SNDBUF) used by the socket server #socket.send.buffer.bytes=204800 # The receive buffer (SO_RCVBUF) used by the socket server #socket.receive.buffer.bytes=204800 # The maximum size of a request that the socket server will accept (protection against OOM) #socket.request.max.bytes=104857600 # 是否允许自动创建topic ,若是false,就需要通过命令创建topic auto.create.topics.enable =false
############################# Log Basics ############################# # A comma seperated list of directories under which to store log files log.dirs=/data/kafka-log/log/9092 # The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=2 # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. # This value is recommended to be increased for installations with data dirs located in RAID array. num.recovery.threads.per.data.dir=1
############################# Log Flush Policy ############################# # Messages are immediately written to the filesystem but by default we only fsync() to sync # the OS cache lazily. The following configurations control the flush of data to disk. # There are a few important trade-offs here: # 1. Durability: Unflushed data may be lost if you are not using replication. # 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush # 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to ex ceessive seeks. # The settings below allow one to configure the flush policy to flush data after a period of time or # every N messages (or both). This can be done globally and overridden on a per-topic basis. # The number of messages to accept before forcing a flush of data to disk log.flush.interval.messages=10000 # The maximum amount of time a message can sit in a log before we force a flush log.flush.interval.ms=1000
############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log. # The minimum age of a log file to be eligible for deletion log.retention.hours=72 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining # segments don't drop below log.retention.bytes. log.retention.bytes=4294967296 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=536870912 # The interval at which log segments are checked to see if they can be deleted according # to the retention policies log.retention.check.interval.ms=600000 log.cleaner.enable=false
############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=master:2181,slave1:2181,slave2:2181 # Timeout in ms for connecting to zookeeper offsets.commit.timeout.ms=500000 request.timeout.ms=500000 zookeeper.connection.timeout.ms=300000
export HBASE_MANAGES_ZK=false
############################# zhouls add ############################# num.replica.fetchers=4 replica.fetch.max.bytes=1048576 replica.fetch.wait.max.ms=1000 replica.high.watermark.checkpoint.interval.ms=5000 replica.socket.timeout.ms=50000 replica.socket.receive.buffer.bytes=65536 replica.lag.time.max.ms=300000 controller.socket.timeout.ms=300000 controller.message.queue.size=50 message.max.bytes=1000000 num.io.threads=8 num.network.threads=8 socket.request.max.bytes=104857600 socket.receive.buffer.bytes=1048576 socket.send.buffer.bytes=1048576 queued.max.requests=16 fetch.purgatory.purge.interval.requests=100 producer.purgatory.purge.interval.requests=100 group.max.session.timeout.ms=500000
slave1上

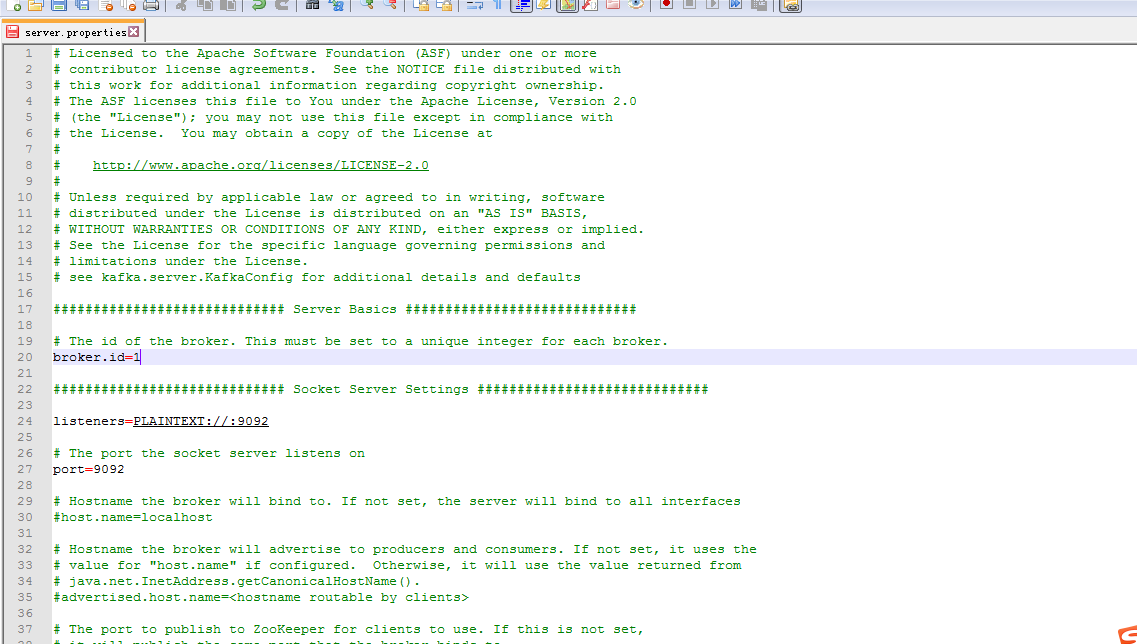
# Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # see kafka.server.KafkaConfig for additional details and defaults ############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker. broker.id=1
############################# Socket Server Settings ############################# listeners=PLAINTEXT://:9092 # The port the socket server listens on port=9092 # Hostname the broker will bind to. If not set, the server will bind to all interfaces #host.name=localhost # Hostname the broker will advertise to producers and consumers. If not set, it uses the # value for "host.name" if configured. Otherwise, it will use the value returned from # java.net.InetAddress.getCanonicalHostName(). #advertised.host.name=<hostname routable by clients> # The port to publish to ZooKeeper for clients to use. If this is not set, # it will publish the same port that the broker binds to. #advertised.port=<port accessible by clients> # The number of threads handling network requests #num.network.threads=10 # The number of threads doing disk I/O #num.io.threads=12 # The send buffer (SO_SNDBUF) used by the socket server #socket.send.buffer.bytes=204800 # The receive buffer (SO_RCVBUF) used by the socket server #socket.receive.buffer.bytes=204800 # The maximum size of a request that the socket server will accept (protection against OOM) #socket.request.max.bytes=104857600 # 是否允许自动创建topic ,若是false,就需要通过命令创建topic auto.create.topics.enable =false
############################# Log Basics ############################# # A comma seperated list of directories under which to store log files log.dirs=/data/kafka-log/log/9092 # The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=2 # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. # This value is recommended to be increased for installations with data dirs located in RAID array. num.recovery.threads.per.data.dir=1
############################# Log Flush Policy ############################# # Messages are immediately written to the filesystem but by default we only fsync() to sync # the OS cache lazily. The following configurations control the flush of data to disk. # There are a few important trade-offs here: # 1. Durability: Unflushed data may be lost if you are not using replication. # 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush # 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to ex ceessive seeks. # The settings below allow one to configure the flush policy to flush data after a period of time or # every N messages (or both). This can be done globally and overridden on a per-topic basis. # The number of messages to accept before forcing a flush of data to disk log.flush.interval.messages=10000 # The maximum amount of time a message can sit in a log before we force a flush log.flush.interval.ms=1000
############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log. # The minimum age of a log file to be eligible for deletion log.retention.hours=72 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining # segments don't drop below log.retention.bytes. log.retention.bytes=4294967296 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=536870912 # The interval at which log segments are checked to see if they can be deleted according # to the retention policies log.retention.check.interval.ms=600000 log.cleaner.enable=false
############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=master:2181,slave1:2181,slave2:2181 # Timeout in ms for connecting to zookeeper offsets.commit.timeout.ms=500000 request.timeout.ms=500000 zookeeper.connection.timeout.ms=300000
export HBASE_MANAGES_ZK=false
############################# zhouls add ############################# num.replica.fetchers=4 replica.fetch.max.bytes=1048576 replica.fetch.wait.max.ms=1000 replica.high.watermark.checkpoint.interval.ms=5000 replica.socket.timeout.ms=50000 replica.socket.receive.buffer.bytes=65536 replica.lag.time.max.ms=300000 controller.socket.timeout.ms=300000 controller.message.queue.size=50 message.max.bytes=1000000 num.io.threads=8 num.network.threads=8 socket.request.max.bytes=104857600 socket.receive.buffer.bytes=1048576 socket.send.buffer.bytes=1048576 queued.max.requests=16 fetch.purgatory.purge.interval.requests=100 producer.purgatory.purge.interval.requests=100 group.max.session.timeout.ms=500000
slave2上

# Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # see kafka.server.KafkaConfig for additional details and defaults ############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker. broker.id=1 ############################# Socket Server Settings ############################# listeners=PLAINTEXT://:9092 # The port the socket server listens on port=9092 # Hostname the broker will bind to. If not set, the server will bind to all interfaces #host.name=localhost # Hostname the broker will advertise to producers and consumers. If not set, it uses the # value for "host.name" if configured. Otherwise, it will use the value returned from # java.net.InetAddress.getCanonicalHostName(). #advertised.host.name=<hostname routable by clients> # The port to publish to ZooKeeper for clients to use. If this is not set, # it will publish the same port that the broker binds to. #advertised.port=<port accessible by clients> # The number of threads handling network requests #num.network.threads=10 # The number of threads doing disk I/O #num.io.threads=12 # The send buffer (SO_SNDBUF) used by the socket server #socket.send.buffer.bytes=204800 # The receive buffer (SO_RCVBUF) used by the socket server #socket.receive.buffer.bytes=204800 # The maximum size of a request that the socket server will accept (protection against OOM) #socket.request.max.bytes=104857600 # 是否允许自动创建topic ,若是false,就需要通过命令创建topic auto.create.topics.enable =false ############################# Log Basics ############################# # A comma seperated list of directories under which to store log files log.dirs=/data/kafka-log/log/9092 # The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=2 # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. # This value is recommended to be increased for installations with data dirs located in RAID array. num.recovery.threads.per.data.dir=1 ############################# Log Flush Policy ############################# # Messages are immediately written to the filesystem but by default we only fsync() to sync # the OS cache lazily. The following configurations control the flush of data to disk. # There are a few important trade-offs here: # 1. Durability: Unflushed data may be lost if you are not using replication. # 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush # 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to ex ceessive seeks. # The settings below allow one to configure the flush policy to flush data after a period of time or # every N messages (or both). This can be done globally and overridden on a per-topic basis. # The number of messages to accept before forcing a flush of data to disk log.flush.interval.messages=10000 # The maximum amount of time a message can sit in a log before we force a flush log.flush.interval.ms=1000 ############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log. # The minimum age of a log file to be eligible for deletion log.retention.hours=72 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining # segments don't drop below log.retention.bytes. log.retention.bytes=4294967296 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=536870912 # The interval at which log segments are checked to see if they can be deleted according # to the retention policies log.retention.check.interval.ms=600000 log.cleaner.enable=false ############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=master:2181,slave1:2181,slave2:2181 # Timeout in ms for connecting to zookeeper offsets.commit.timeout.ms=500000 request.timeout.ms=500000 zookeeper.connection.timeout.ms=300000 export HBASE_MANAGES_ZK=false ############################# zhouls add ############################# num.replica.fetchers=4 replica.fetch.max.bytes=1048576 replica.fetch.wait.max.ms=1000 replica.high.watermark.checkpoint.interval.ms=5000 replica.socket.timeout.ms=50000 replica.socket.receive.buffer.bytes=65536 replica.lag.time.max.ms=300000 controller.socket.timeout.ms=300000 controller.message.queue.size=50 message.max.bytes=1000000 num.io.threads=8 num.network.threads=8 socket.request.max.bytes=104857600 socket.receive.buffer.bytes=1048576 socket.send.buffer.bytes=1048576 queued.max.requests=16 fetch.purgatory.purge.interval.requests=100 producer.purgatory.purge.interval.requests=100 group.max.session.timeout.ms=500000
当然,大家也可以把master的broker.id=1开始。这个随意!
master的broker.id=0 slave1的broker.id=0 slave2的broker.id=0
master的broker.id=1 slave1的broker.id=2 slave2的broker.id=3
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号