HUE配置文件hue.ini 的mapred_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货!
我的集群机器情况是 bigdatamaster(192.168.80.10)、bigdataslave1(192.168.80.11)和bigdataslave2(192.168.80.12)
然后,安装目录是在/home/hadoop/app下。
官方建议在master机器上安装Hue,我这里也不例外。安装在bigdatamaster机器上。
Hue版本:hue-3.9.0-cdh5.5.4
需要编译才能使用(联网)
说给大家的话:大家电脑的配置好的话,一定要安装cloudera manager。毕竟是一家人的。
同时,我也亲身经历过,会有部分组件版本出现问题安装起来要个大半天时间去排除,做好心里准备。废话不多说,因为我目前读研,自己笔记本电脑最大8G,只能玩手动来练手。
纯粹是为了给身边没高配且条件有限的学生党看的! 但我已经在实验室机器群里搭建好cloudera manager 以及 ambari都有。
大数据领域两大最主流集群管理工具Ambari和Cloudera Manger
Cloudera安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
对于这个模块,其实可以跳过,毕竟有了yarn_clusters。现在都是用YARN。至于Hue官网为什么还要写出这一模块,是综合考虑把!

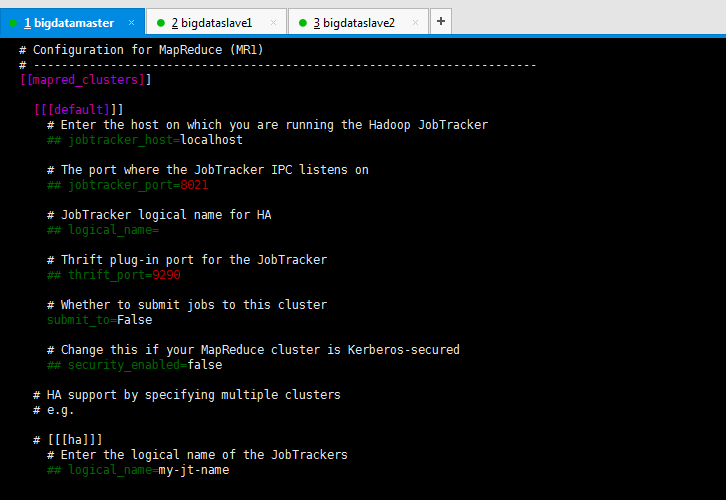
# Configuration for MapReduce (MR1) # ------------------------------------------------------------------------ [[mapred_clusters]] [[[default]]] # Enter the host on which you are running the Hadoop JobTracker ## jobtracker_host=localhost # The port where the JobTracker IPC listens on ## jobtracker_port=8021 # JobTracker logical name for HA ## logical_name= # Thrift plug-in port for the JobTracker ## thrift_port=9290 # Whether to submit jobs to this cluster submit_to=False # Change this if your MapReduce cluster is Kerberos-secured ## security_enabled=false # HA support by specifying multiple clusters # e.g. # [[[ha]]] # Enter the logical name of the JobTrackers ## logical_name=my-jt-name
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号