Impala是什么?
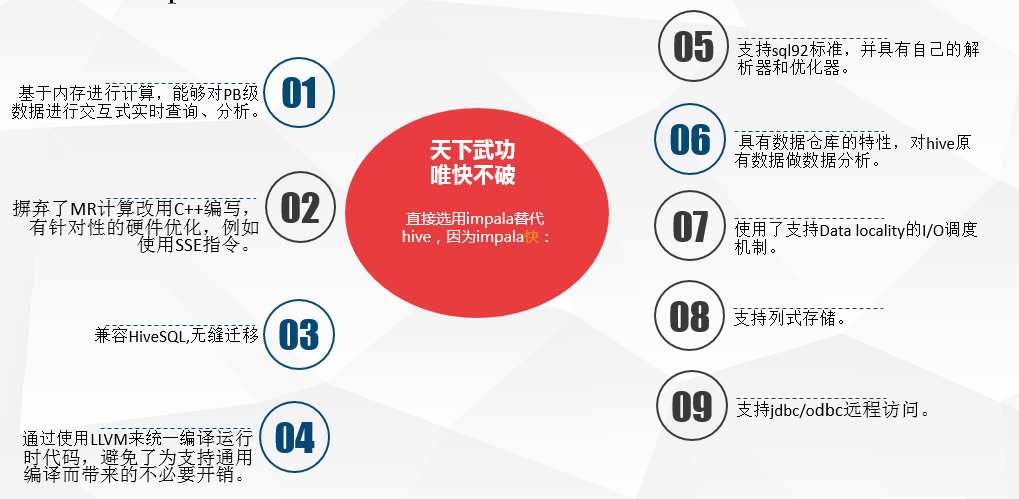
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
Impala是参照谷歌新三篇论文Dremel的开源实现,和Shark、Drill功能相似。Impala是Cloudera公司主导开发并开源。基于Hive并使用内存进行计算,兼顾数据仓库,具有实时、批处理、多并发等优点。是使用CDH的首选PB级大数据实时查询分析引擎。
谷歌旧三篇论文:mapreduce(mapreduce) 、 bigtable(HBase) 、 gfs(HDFS)
谷歌新三篇论文:Dremel(Impala)、Caffeine、Pergel。
同时,Impala由Cloudera公司开发,可以对存储在HDFS、HBase的海量数据提供交互式查询的SQL接口。除了和Hive使用相同的统一存储平台,Impala还提供了一个熟悉的面向批量或实时查询的统一平台。Impala的特点是查询非常迅速,其性能大幅领先于Hive。
注意:Impala并没有基于MapReduce的计算框架,这也是Impala可以大幅领先Hive的原因,Impala是定位是OLAP。
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号