


ElasticSearch 架构图
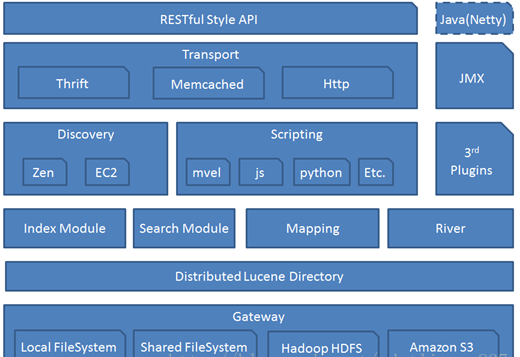
ElasticSearch 架构图
从下往上来分析ElasticSearch 架构图
Gateway代表ElasticSearch索引的持久化存储方式。
在Gateway中,ElasticSearch默认先把索引存储在内存中,然后当内存满的时候,再持久化到Gateway里。当ES集群关闭或重启的时候,它就会从Gateway里去读取索引数据。比如LocalFileSystem和HDFS、AS3等。
DistributedLucene Directory,它是Lucene里的一些列索引文件组成的目录。它负责管理这些索引文件。包括数据的读取、写入,以及索引的添加和合并等。
River,代表是数据源。是以插件的形式存在于ElasticSearch中。
Mapping,映射的意思,非常类似于静态语言中的数据类型。比如我们声明一个int类型的变量,那以后这个变量只能存储int类型的数据。
比如我们声明一个double类型的mapping字段,则只能存储double类型的数据。
Mapping不仅是告诉ElasticSearch,哪个字段是哪种类型。还能告诉ElasticSearch如何来索引数据,以及数据是否被索引到等。
Search Moudle,这个很简单
Index Moudle,这个很简单
Disvcovery,主要是负责集群的master节点发现。比如某个节点突然离开或进来的情况,进行一个分片重新分片等。这里有个发现机制。
发现机制默认的实现方式是单播和多播的形式,即Zen,同时也支持点对点的实现。另外一种是以插件的形式,即EC2。
Scripting,即脚本语言。包括很多,这里不多赘述。如mvel、js、python等。
Transport,代表ElasticSearch内部节点,代表跟集群的客户端交互。包括 Thrift、Memcached、Http等协议
RESTful Style API,通过RESTful方式来实现API编程。
3rd plugins,代表第三方插件。
Java(Netty),是开发框架。
JMX,是监控。
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

