Elasticsearch之cur查询索引
前提,
Elasticsearch之curl创建索引库
Elasticsearch之curl创建索引
Elasticsearch之curl创建索引库和索引时注意事项
Elasticsearch之cur查询索引
1、根据员工id查询
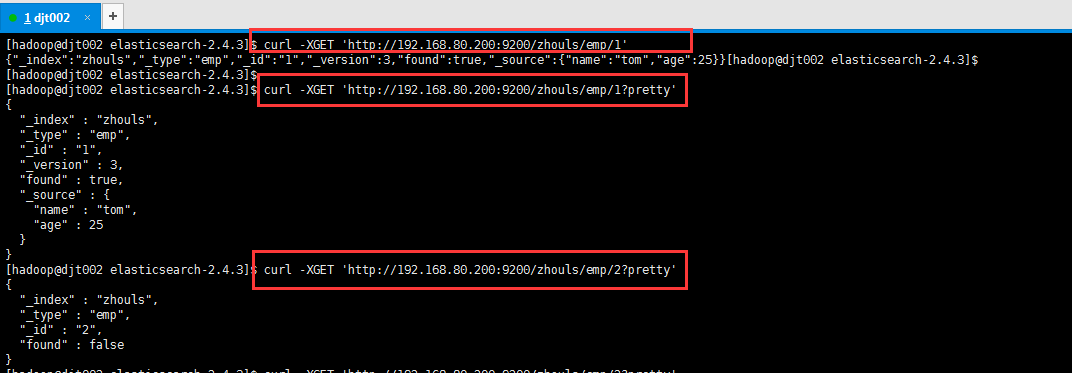
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/1'
{"_index":"zhouls","_type":"emp","_id":"1","_version":3,"found":true,"_source":{"name":"tom","age":25}}[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/1?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"_version" : 3,
"found" : true,
"_source" : {
"name" : "tom",
"age" : 25
}
}
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/2?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "2",
"found" : false
}
在任意的查询字符串中添加pretty参数,es可以得到易于识别的json结果。查得到的结果,是在source里。
2、检索文档中的一部分,如果只需要显示指定字段
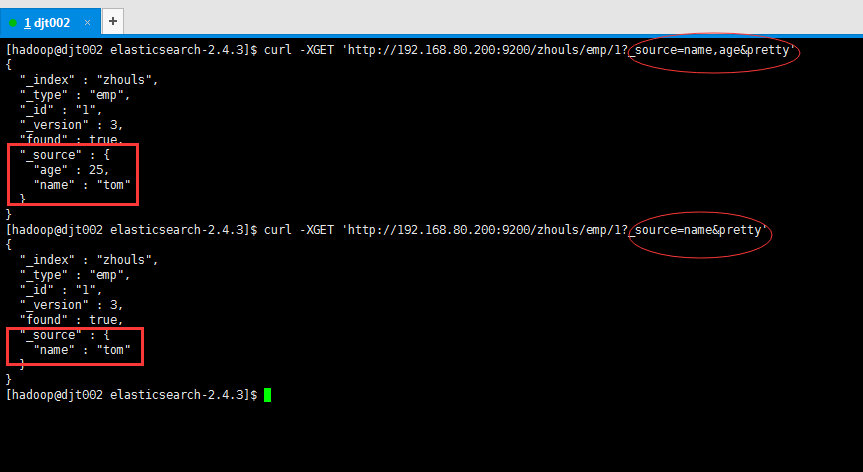
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/1?_source=name,age&pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"_version" : 3,
"found" : true,
"_source" : {
"age" : 25,
"name" : "tom"
}
}
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/1?_source=name&pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"_version" : 3,
"found" : true,
"_source" : {
"name" : "tom"
}
}
[hadoop@djt002 elasticsearch-2.4.3]$
3、查询指定索引库指定类型所有数据
这里,指定emp类型。查询它下的所有数据

[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/_search?pretty'
{
"took" : 206, 代表消耗的时间,是206毫秒
"timed_out" : false, 代表是否超时,false代表没有超时
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : { 是hits
"total" : 4,
"max_score" : 1.0, 打分,是1分
"hits" : [ { hits里面,还有hits,在这里面是一个数组
"_index" : "zhouls",
"_type" : "emp",
"_id" : "AVpdBaixcJQ8qYq5I_Es",
"_score" : 1.0,
"_source" : {
"name" : "tom",
"age" : 25
}
}, {
"_index" : "zhouls",
"_type" : "emp",
"_id" : "AVpdAus-cJQ8qYq5I_Er",
"_score" : 1.0,
"_source" : {
"name" : "tom",
"age" : 25
}
}, {
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "tom",
"age" : 25
}
}, {
"_index" : "zhouls",
"_type" : "emp",
"_id" : "2_create",
"_score" : 1.0,
"_source" : {
"name" : "tom",
"age" : 25
}
} ] 一共是4条数据
}
}
4、查询指定索引库所有数据
这里,指定zhouls索引库。查询它下的所有数据。一个索引库下有很多种类型,我这里仅emp一种。自己可以新建多种出来进行测验

[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/_search?pretty'
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 4,
"max_score" : 1.0,
"hits" : [ {
"_index" : "zhouls",
"_type" : "emp",
"_id" : "AVpdBaixcJQ8qYq5I_Es",
"_score" : 1.0,
"_source" : {
"name" : "tom",
"age" : 25
}
}, {
"_index" : "zhouls",
"_type" : "emp",
"_id" : "AVpdAus-cJQ8qYq5I_Er",
"_score" : 1.0,
"_source" : {
"name" : "tom",
"age" : 25
}
}, {
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "tom",
"age" : 25
}
}, {
"_index" : "zhouls",
"_type" : "emp",
"_id" : "2_create",
"_score" : 1.0,
"_source" : {
"name" : "tom",
"age" : 25
}
} ]
}
}
总结:
结合自己的经验,一般对于es的简单查询,用crul,对于es的复杂查询,用java代码去实现。
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号