Storm概念学习系列之Tuple元组(数据载体)
不多说,直接上干货!
Tuple元组
Tuple 是 Storm 的主要数据结构,并且是 Storm 中使用的最基本单元、数据模型和元组。
Tuple 描述
Tuple 就是一个值列表, Tuple 中的值可以是任何类型的,动态类型的Tuple的fields可以不用声明;默认情况下,Storm中的Tuple支持私有类型、字符串、字节数组等作为它的字段值,如果使用其他类型,就需要序列化该类型。
Tuple的字段默认类型有 : integer、 float、 double、 long、short、 string、 byte、 binary(byte[])。
Tuple元组,是消息传递的基本单元,是一个命名的值列表,元组中的字段可以是任何类型的对象。Storm使用元组作为其数据模型,元组支持所有的基本类型、字符串和字节数组作为字段值,只要实现类型的序列化接口就可以使用该类型的对象。
元组本来应该是一个key-value的Map,但是由于各个组件间传递的元组的字段名称已经事先定义好,所以只要按序把元组填入各个value即可,所以元组是一个vlue的List。
Tuple是Storm采用的数据表示模型,所有的数据都以Tuple的形式在各个组件之间流动。Tuple是一组字段列表,每个字段由一个字段名和字段值组成,每个Tuple类似于数据库中的一行记录。在默认的情况下,Tuple的字段类型可以是integer、long、short、byte、string、double、float、boolean和byte array。当然,你也可以通过实现序列化器自定义类型。
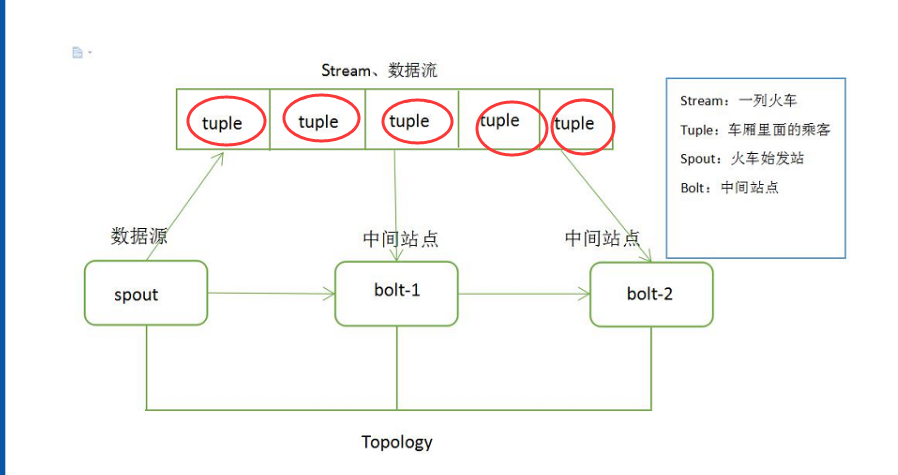
Tuple 数据结构如图 1 所示。

图 1 Tuple 数据结构
Tuple 可以理解成键值对。例如,创建一个Bolt 要发送两个字段(命名为 double 和 triple),其中键就是定义在declareOutputFields 方法中的 Fields 对象,值就是在 emit 方法中发送的 Values 对象。
以下是一个简单例子
public class DoubleAndTripleBolt extends BaseRichBolt { OutputCollectorBase _collector;
@Override public void prepare(Map conf, TopologyContext context, OutputCollectorBase collector) { _collector = collector; }
@Override public void execute(Tuple input) { int val = input.getInteger(0); _collector.emit(input, new Values(val*2, val*3)); _collector.ack(input); }
@Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("double", "triple")); }}
此外,在使用的 Storm Java 包中, backtype.storm.tuple 主要有以下几个类:
Fileds.class MessageId.class Tuple.class TupleImpl.class Values.class
列出以上内容是为了更好地理解 Tuple,这样能够从本质上理解 Tuple,在使用时更加得心应手。
Tuple 的生命周期
了解一个 Tuple 的生命周期就需要查看源码,如下的 Java 代码展示了 Spout(消息源)接口发出 Tuple(消息)的整个过程。
public interface ISpout extends Serializable { void open(Map conf, TopologyContext context, SpoutOutputCollector collector); void nextTuple(); void ack(Object msgId); void fail(Object msgId); void close(); }
首 先, Storm 调 用 Spout(消息源)的nextTuple 方法来获取下一个Tuple, Spout通过Open 方法的参数提供的SpoutOutputCollector将新Tuple发射到其中一个输出消息流。
注意:发射Tuple 时, Spout提供一个message-id,通过这个ID 来追踪该Tuple。
接下来, Storm跟踪该Tuple的树形结构是否成功创建,并根据 messageid调用Spout中的ack函数,以确认Tuple是否被完全处理。如果Tuple超时,则调用 Spout 的 fail 方法。
由此看出,同一个Tuple不管是acked,还是failed都是由创建它的Spout发出并维护的,所以,即使Spout 在集群环境中同时执行很多的任务,该Tuple 也不会被其他任务调用或生成 acked或 failed 状态。总之, Storm会利用内部的 Acker 机制保证每个Tuple 被可靠地处理。最后,在任务完成后,Spout调用Close方法结束 Tuple 的使命。
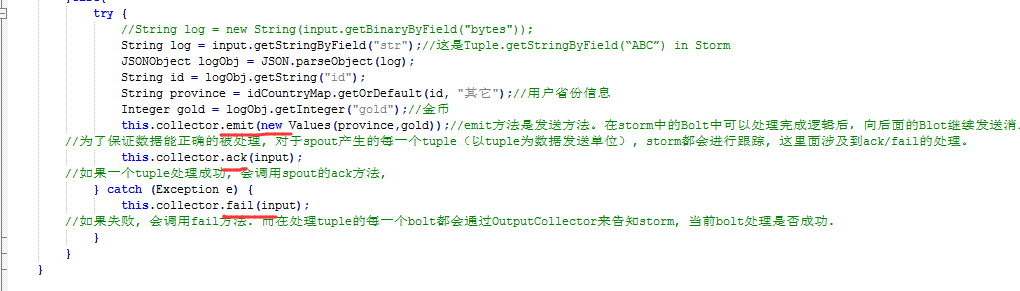
比如
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号