3 hql语法及自定义函数(含array、map讲解) + hive的java api
本博文的主要内容如下:
.hive的详细官方手册
.hive支持的数据类型
.Hive Shell
.Hive工程所需依赖的jar包
.hive自定义函数
.分桶4
.附PPT
hive的详细官方手册
https://cwiki.apache.org/confluence/display/Hive/LanguageManual
标准的SQL,hive都支持。
这就是,为什么目前hive占有市场这么多,因为,太丰富了,当然,Spark那边的Spark SQL,也在不断地进步。
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types

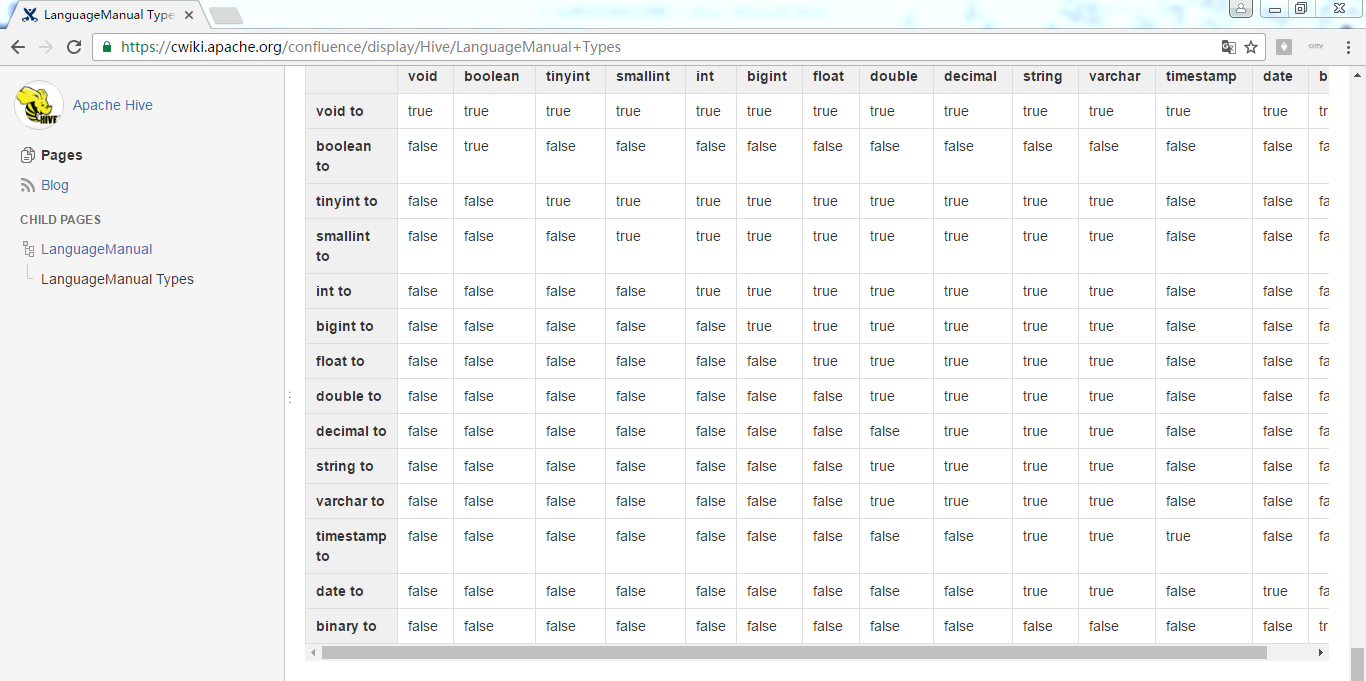
非常多,自行去研究,这里不多赘述。
将查询结果,写到本地文件或hdfs里的文件
//write to hdfs
insert overwrite local directory '/home/hadoop/hivetemp/test.txt' select * from tab_ip_part where part_flag='part1'; //路径可以是Linux本地的 insert overwrite directory '/hiveout.txt' select * from tab_ip_part where part_flag='part1'; //路径也可以是hdfs里的
这里,不演示
//array
create table tab_array(a array<int>,b array<string>) row format delimited fields terminated by '\t' collection items terminated by ',';
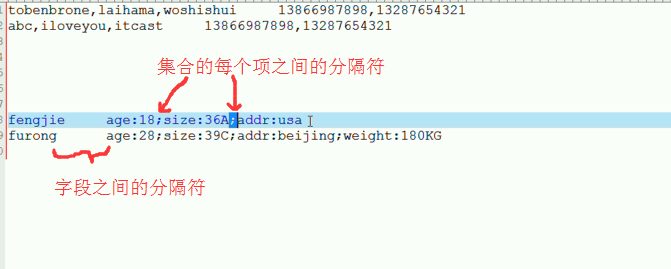
示例数据
tobenbrone, laihama,woshishui 13866987898,13287654321 abc,iloveyou,itcast 13866987898,13287654321
select a[0] from tab_array; select * from tab_array where array_contains(b,'word'); insert into table tab_array select array(0),array(name,ip) from tab_ext t;

//map
create table tab_map(name string,info map<string,string>) row format delimited fields terminated by '\t' collection items terminated by ';' map keys terminated by ':';
示例数据:
fengjie age:18;size:36A;addr:usa furong age:28;size:39C;addr:beijing;weight:180KG
load data local inpath '/home/hadoop/hivetemp/tab_map.txt' overwrite into table tab_map;
insert into table tab_map select name,map('name',name,'ip',ip) from tab_ext;
这里,不多赘述。
//struct
create table tab_struct(name string,info struct<age:int,tel:string,addr:string>) row format delimited fields terminated by '\t' collection items terminated by ','
load data local inpath '/home/hadoop/hivetemp/tab_st.txt' overwrite into table tab_struct;
insert into table tab_struct select name,named_struct('age',id,'tel',name,'addr',country) from tab_ext;
这里,不多赘述。
Hive Shell
//cli shell
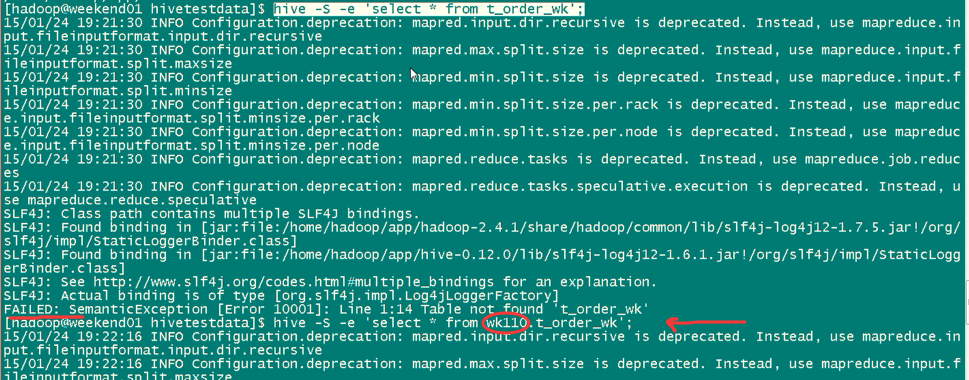
hive -S -e 'select country,count(*) from tab_ext' > /home/hadoop/hivetemp/e.txt
有了这种执行机制,就使得我们可以利用脚本语言(bash shell,python)进行hql语句的批量执行
select * from tab_ext sort by id desc limit 5;
select a.ip,b.book from tab_ext a join tab_ip_book b on(a.name=b.name);
思考一个问题:就说,一个业务场景里面,写sql语句去分析作统计,往往不是一句sql语句能搞定的,sql对一些字段或函数或自定义函数处理会得出一些中间结果,中间结果存在中间表里,然后,才可进入下一步的处理。可能,你需写好多条sql语句,按照批量,流程去走,以前在关系型数据库里,是按照流程处理过程做的。
hive里,不支持存储过程的语法,那若有一个模型,这个模型里有十几个sql语句,一条一条写很麻烦,那么,hive在想,能不能组织成批量去运行呢?则借外部的工作(如写一个shell脚本,执行十几个sql语句)。
可以参照
Sqoop 脚本开发规范(实例手把手带你写sqoop export和sqoop import)
在shell下,接收。
//cli shell
hive -S -e 'select country,count(*) from tab_ext' > /home/hadoop/hivetemp/e.txt
有了这种执行机制,就使得我们可以利用脚本语言(bash shell,python)进行hql语句的批量执行
select * from tab_ext sort by id desc limit 5;
select a.ip,b.book from tab_ext a join tab_ip_book b on(a.name=b.name);

如业务场景里,


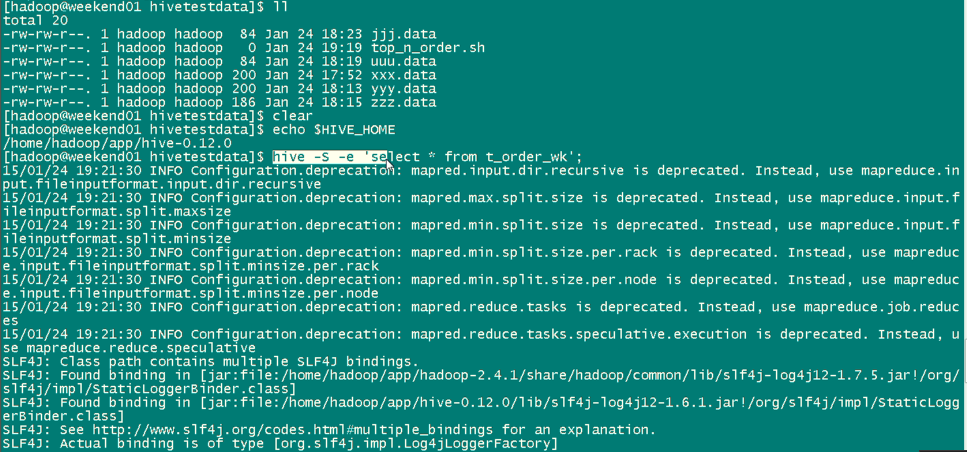
有了这种执行机制,就使得我们可以利用脚本语言(bash shell,python)进行hql语句的批量执行。
bash shell和python是最常用的两种脚本语言。
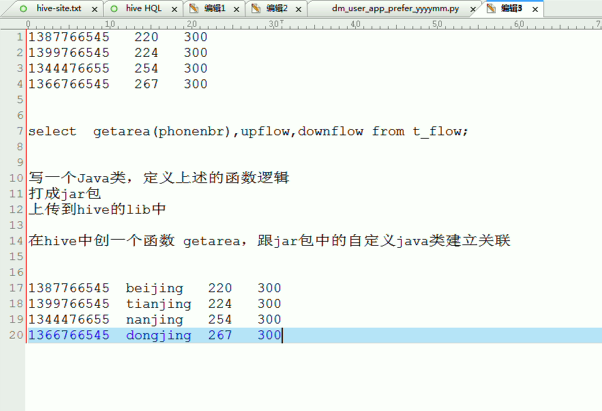
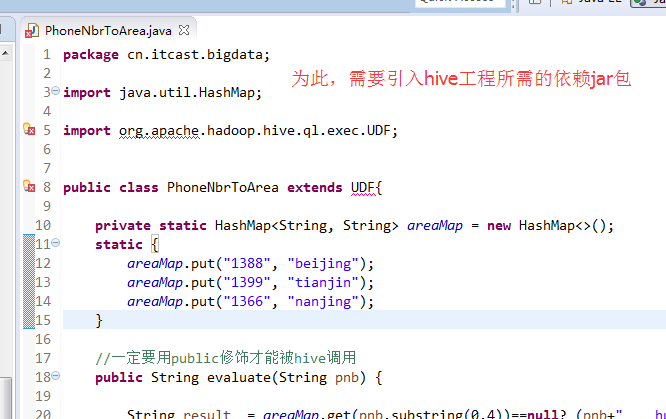
新建包,cn.itcast.bigdata

新建,PhoneNbrToArea.java
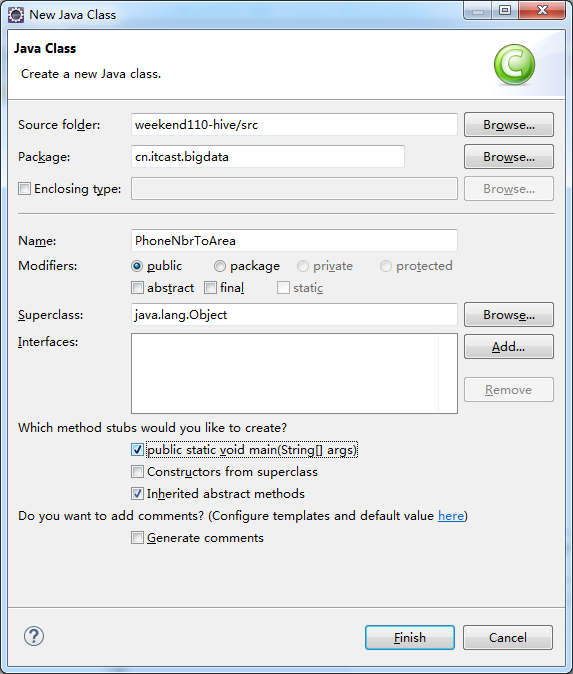
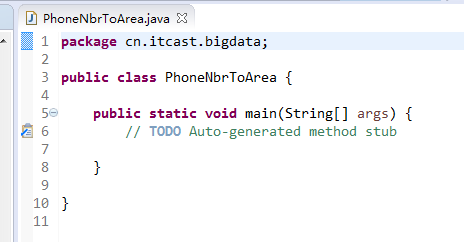
编写代码

解压

为了方便,把D:\SoftWare\hive-0.12.0\lib的jar包,全导入进去,但是,还要导入hadoop-core-***.Jar。(初学,还是手动吧!)
查阅了一些资料。在hive工程,所依赖的jar包,一般都是有如下就好了。12个jar包。
http://xiaofengge315.blog.51cto.com/405835/1408512
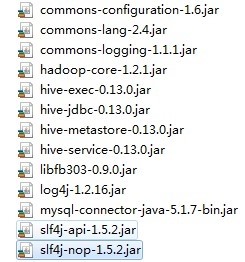
http://blog.csdn.net/haison_first/article/details/41051143

commons-lang-***.jar
commons-logging-***.jar
commons-logging-api-***.jar
hadoop-core-***.jar
hive-exec-***.jar
hive-jdbc-***.jar
hive-metastore-***.jar
hive-service-***.jar
libfb***.jar
log4j-***.jar
slf4j-api-***.jar
sl4j-log4j-***.jar
说明,注意了,在hadoop-2.X版本之后,hadoop-core-***.jar,没有了,被分散成其他的jar包了。以前,是放在hadoop压缩包下的share目录下的
2.x系列已经没有hadoop-core的jar包了,变成一个个散的了,像下面这样
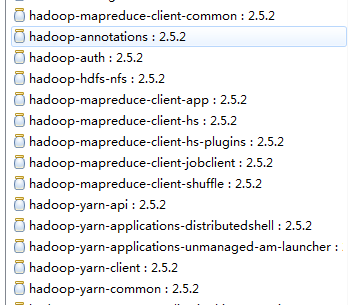
鉴于此,因为,hive工程依赖于hive jar依赖包,日志jar包。
由于hive的很多操作依赖于mapreduce程序,因此,hive工程中还需引入hadoop包。
udf和jdbc连接hive需要的jar包,基本是最简的了。
在这一步,各有说法,但是确实,是不需要全部导入,当然,若是图个方便,可全部导入。
我这里,hadoop的版本是,hadoop-2.4.1,hive的版本是,hive-0.12.0。(因为,这个是自带的)
再谈hive-1.0.0与hive-1.2.1到JDBC编程忽略细节问题
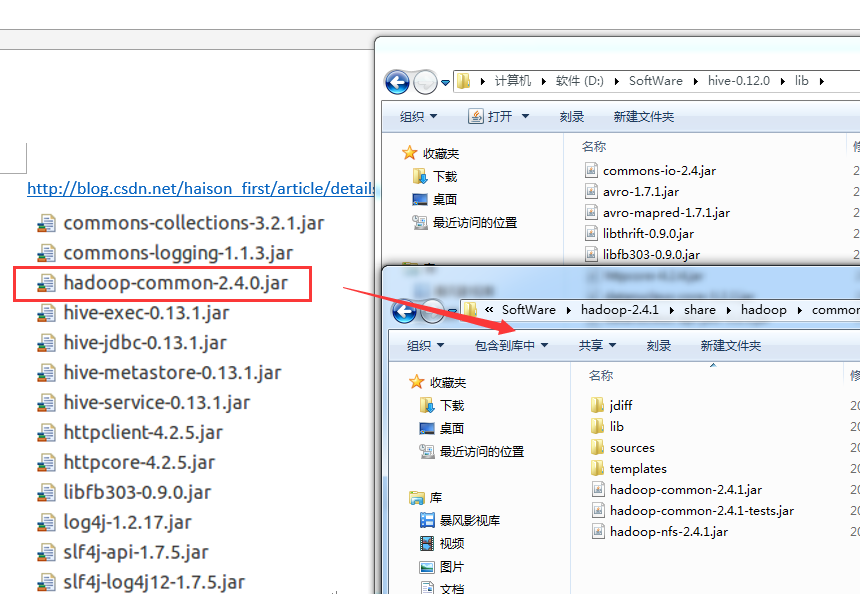
Hive工程所需依赖的jar包
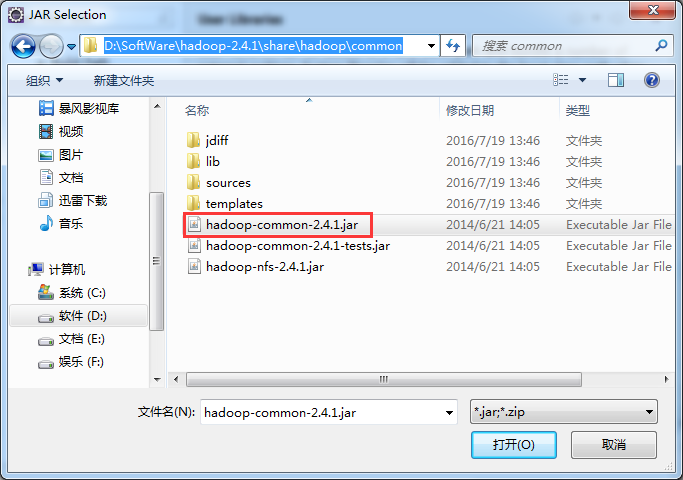
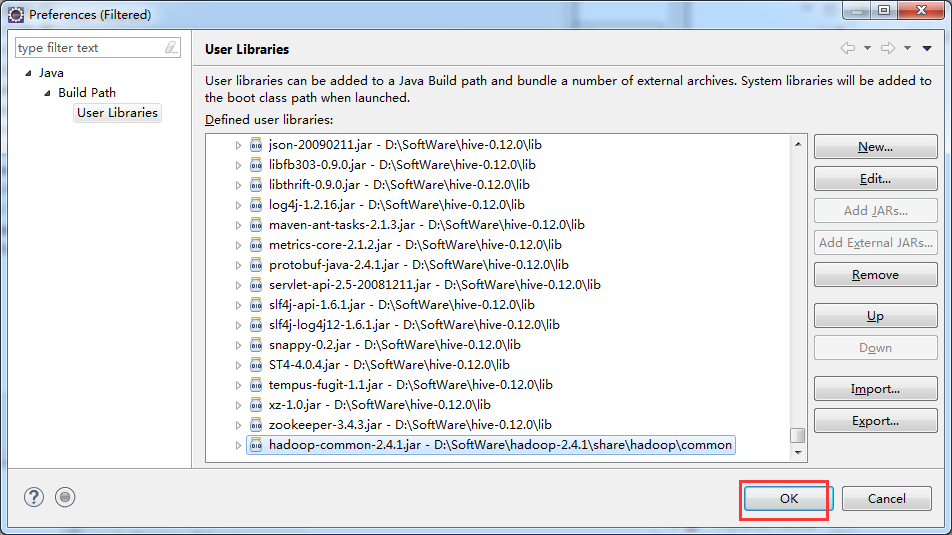
总结:就是将D:\SoftWare\hadoop-2.4.1\share\hadoop\common下的hadoop-common-2.4.1.jar
,以及D:\SoftWare\hive-0.12.0\lib\下的所有。即可。(图个方便)!
当然,生产里,不建议这么做。
也参考了网上一些博客资料说,不需这么多。此外,程序可能包含一些间接引用,以后再逐步逐个,下载,添加就是。复制粘贴到hive-0.12.0lib 里。
参考我的博客
Eclipse下新建Maven项目、自动打依赖jar包
2 weekend110的HDFS的JAVA客户端编写 + filesystem设计思想总结
weekend110-hive -> Build Path -> Configure Build Path




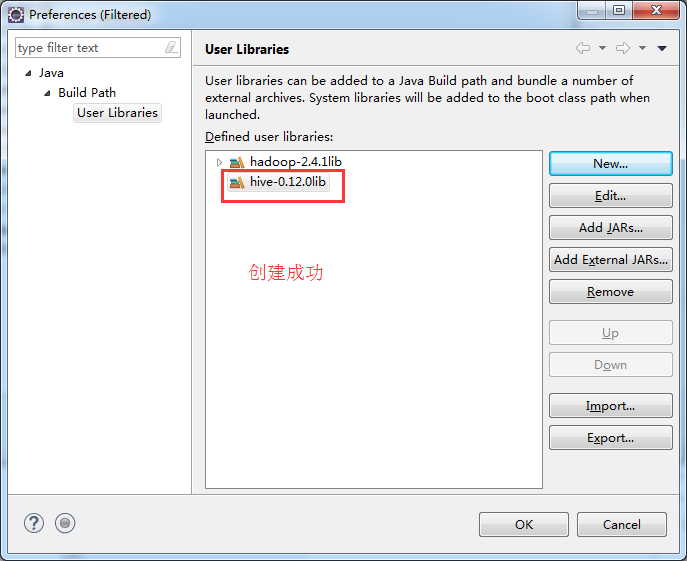
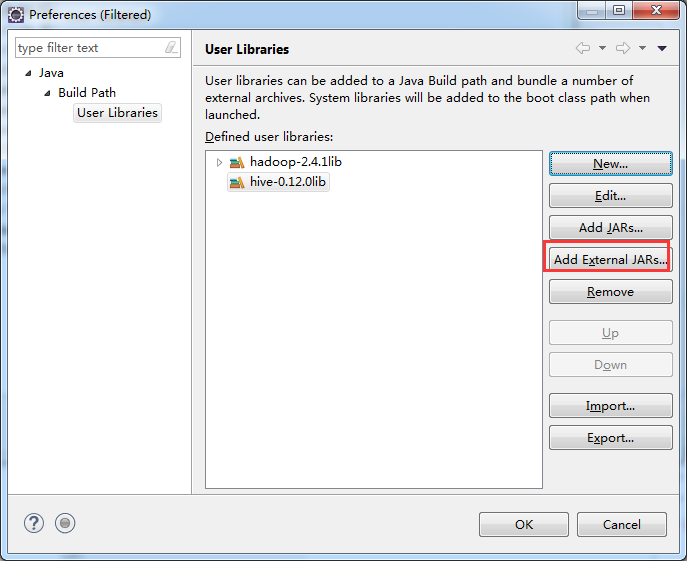
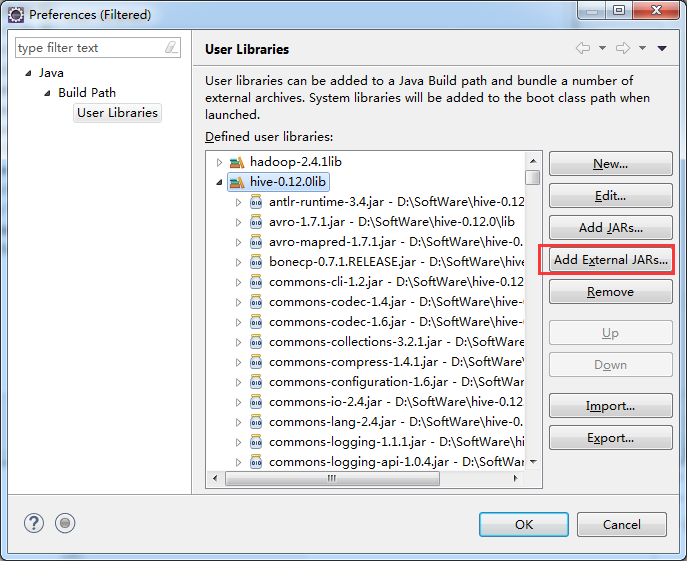
总结:就是将D:\SoftWare\hadoop-2.4.1\share\hadoop\common下的hadoop-common-2.4.1.jar
,以及D:\SoftWare\hive-0.12.0\lib\下的所有。即可。(图个方便)!
D:\SoftWare\hive-0.12.0\lib\下的所有

D:\SoftWare\hadoop-2.4.1\share\hadoop\common下的hadoop-common-2.4.1.jar
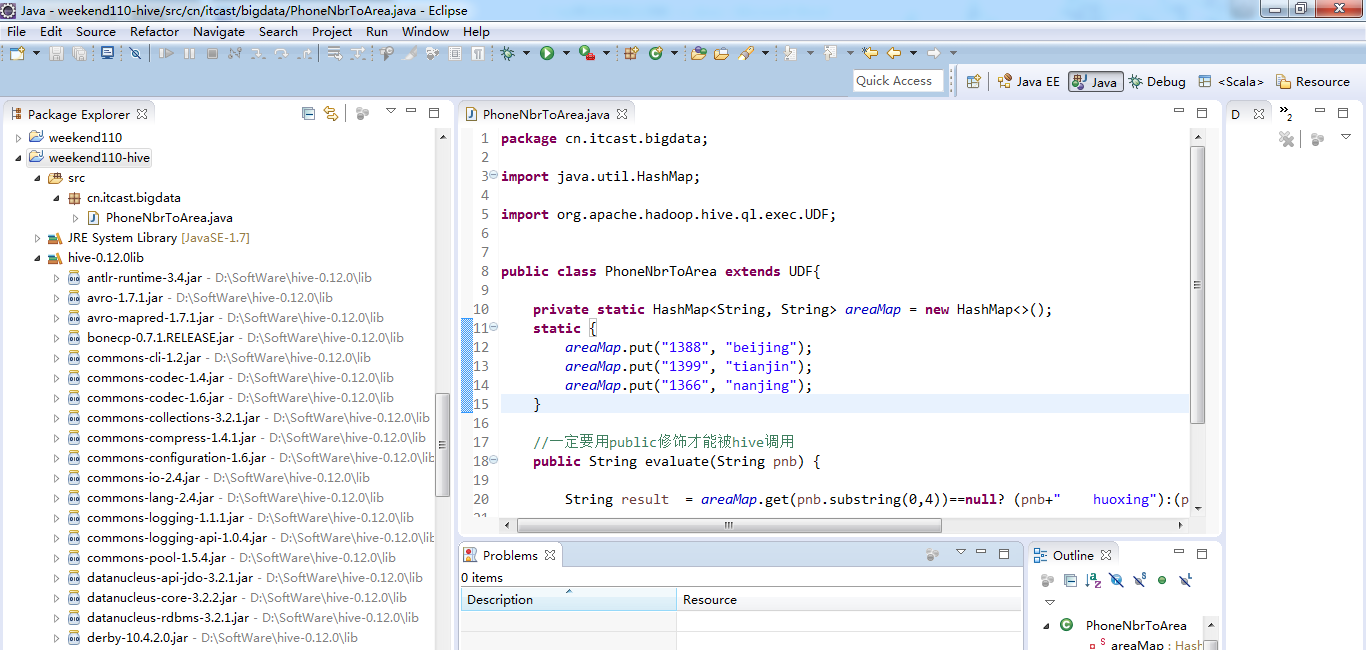
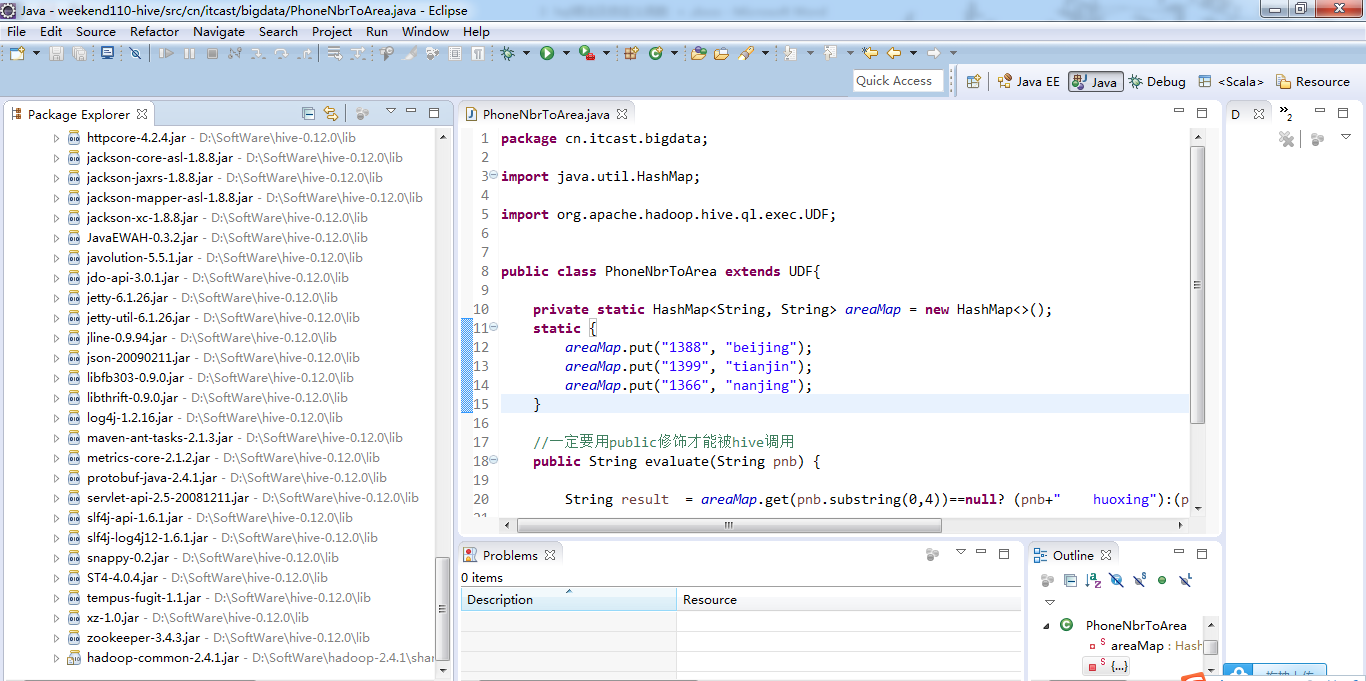
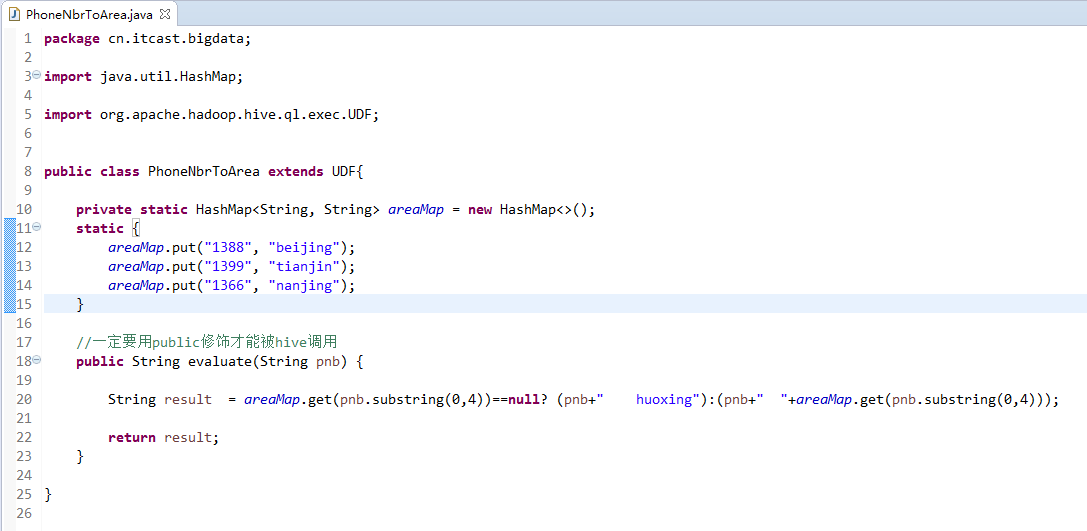
package cn.itcast.bigdata; import java.util.HashMap; import org.apache.hadoop.hive.ql.exec.UDF; public class PhoneNbrToArea extends UDF{ private static HashMap<String, String> areaMap = new HashMap<>(); static { areaMap.put("1388", "beijing"); areaMap.put("1399", "tianjin"); areaMap.put("1366", "nanjing"); } //一定要用public修饰才能被hive调用 public String evaluate(String pnb) { String result = areaMap.get(pnb.substring(0,4))==null? (pnb+" huoxing"):(pnb+" "+areaMap.get(pnb.substring(0,4))); return result; } }




默认是/root/下,
这里,我改下到/home/hadoop/下

//UDF
select if(id=1,first,no-first),name from tab_ext;

hive>add jar /home/hadoop/myudf.jar; hive>CREATE TEMPORARY FUNCTION my_lower AS 'org.dht.Lower'; select my_upper(name) from tab_ext;
hive自定义函数
接下来,创建hive自定义函数,来与它关联。Hive自带的函数是永久,我们自定义的函数是TEMPORARY。


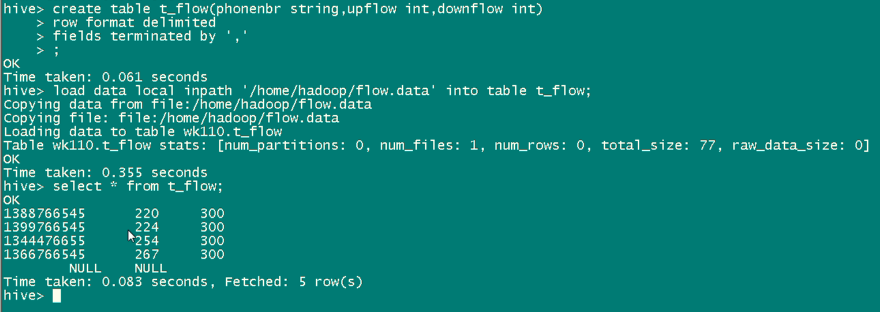

得要去掉, 不然后续处理,会出现问题。

在企业里,使用hive是有规范步骤的,一般在采用元数据,自动用mapreduce程序,清洗之后,再给hive。
数据采集 -》 数据清洗 -> 数据归整 -> 再交给hive
分桶
注意:普通表(外部表、内部表)、分区表这三个都是对应HDFS上的目录,桶表对应是目录里的文件
//CLUSTER <--相对高级一点,你可以放在有精力的时候才去学习>
create table tab_ip_cluster(id int,name string,ip string,country string) clustered by(id) into 3 buckets; //根据id来分桶,分3桶
load data local inpath '/home/hadoop/ip.txt' overwrite into table tab_ip_cluster;
set hive.enforce.bucketing=true;
insert into table tab_ip_cluster select * from tab_ip;
select * from tab_ip_cluster tablesample(bucket 2 out of 3 on id);
分桶是细粒度的,分桶是不同的文件。
分区是粗粒度的,即相当于,表下建立文件夹。分区是不同的文件夹。
桶在对指定列进行哈希计算时,会根据哈希值切分数据,使每个桶对应一个文件。
里面的id是哈希值,分过来的。
分桶,一般用作数据倾斜和数据抽样方面。由此,可看出是细粒度。
附PPT






































作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号