3 weekend110的job提交的逻辑及YARN框架的技术机制 + MR程序的几种提交运行模式
途径1:
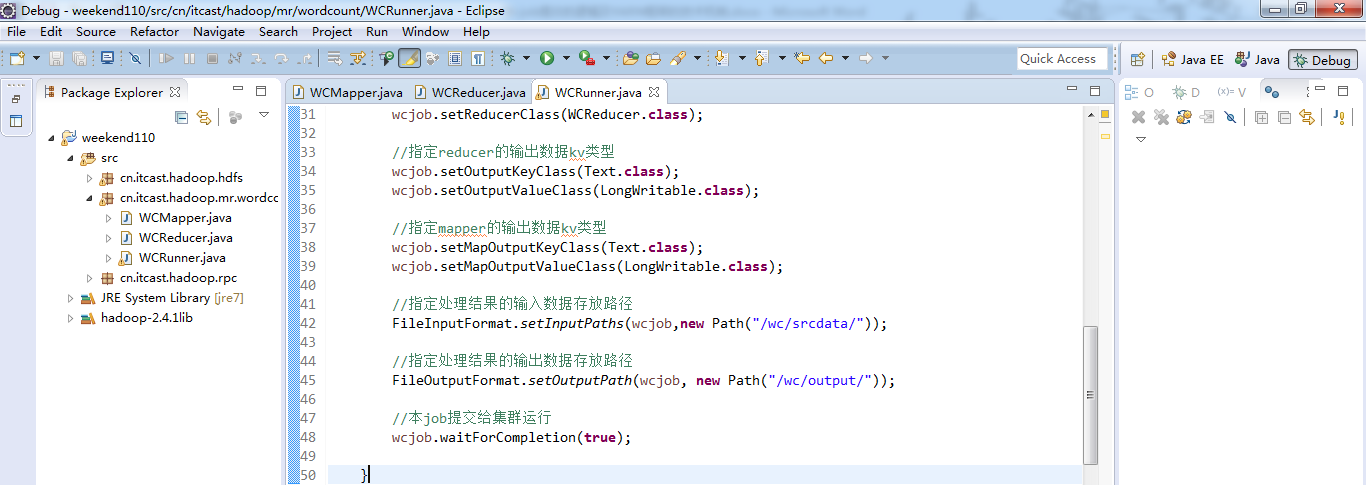
途径2:

途径3:







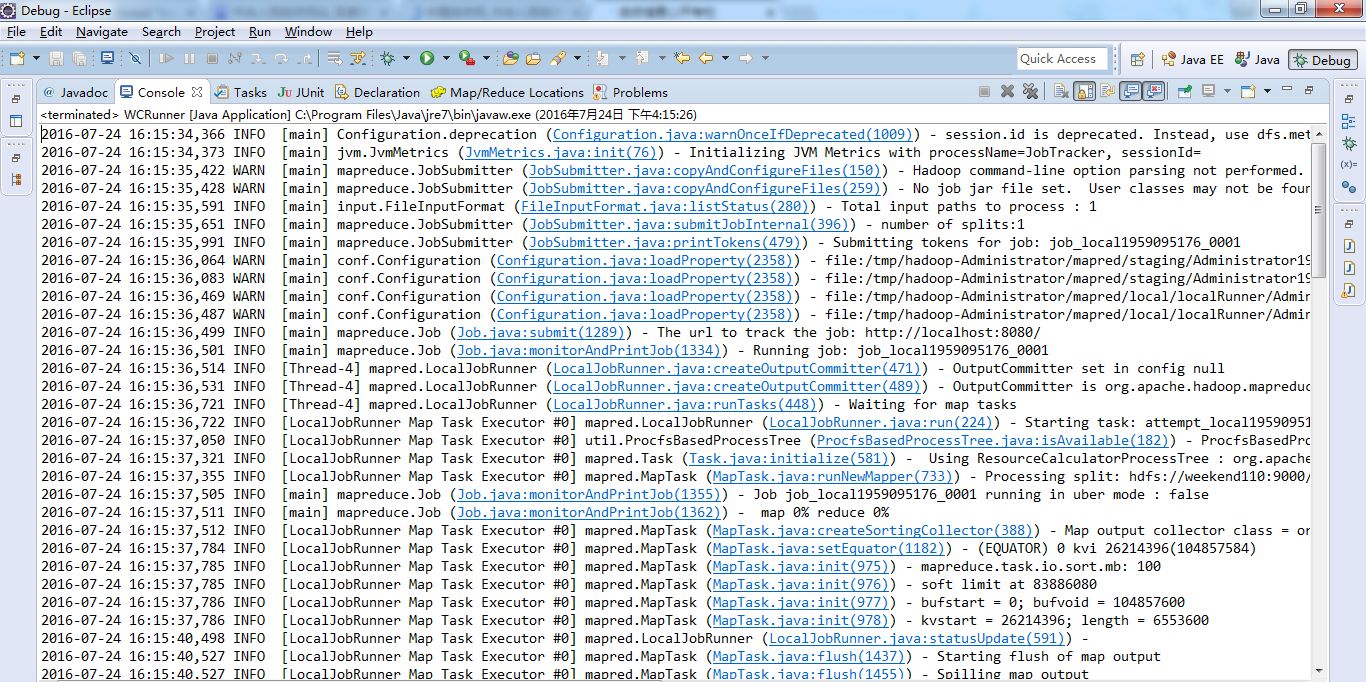
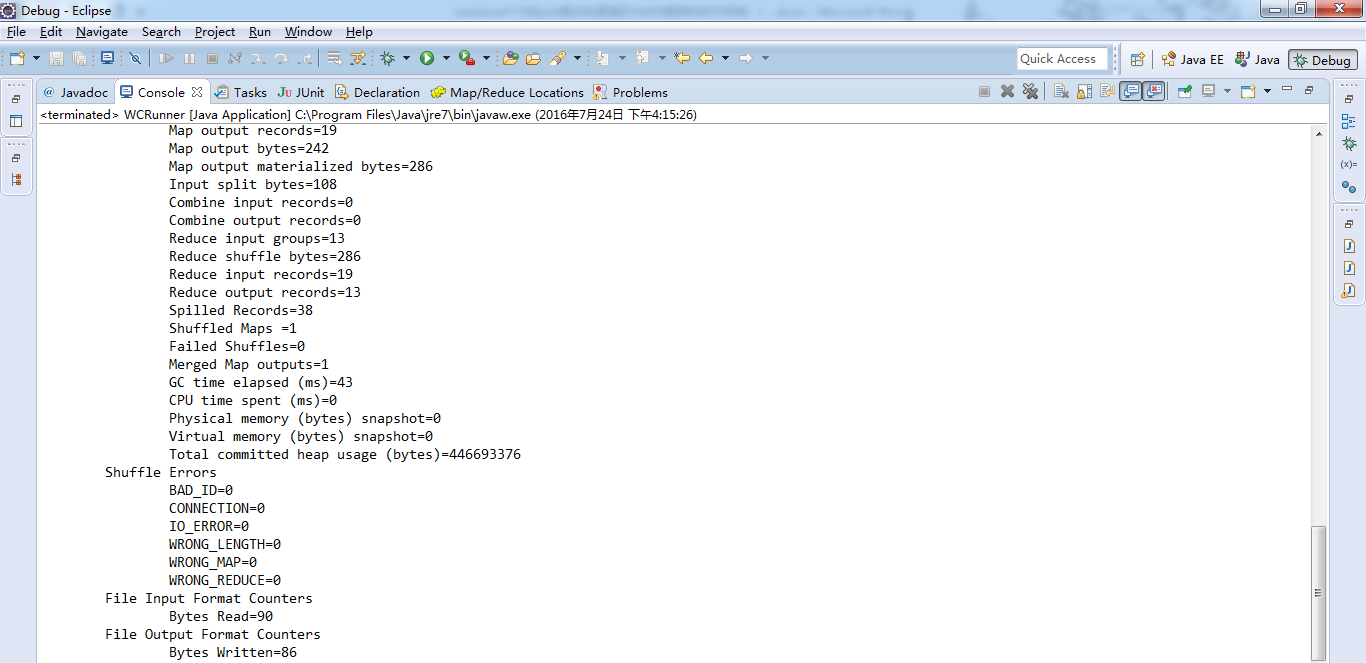
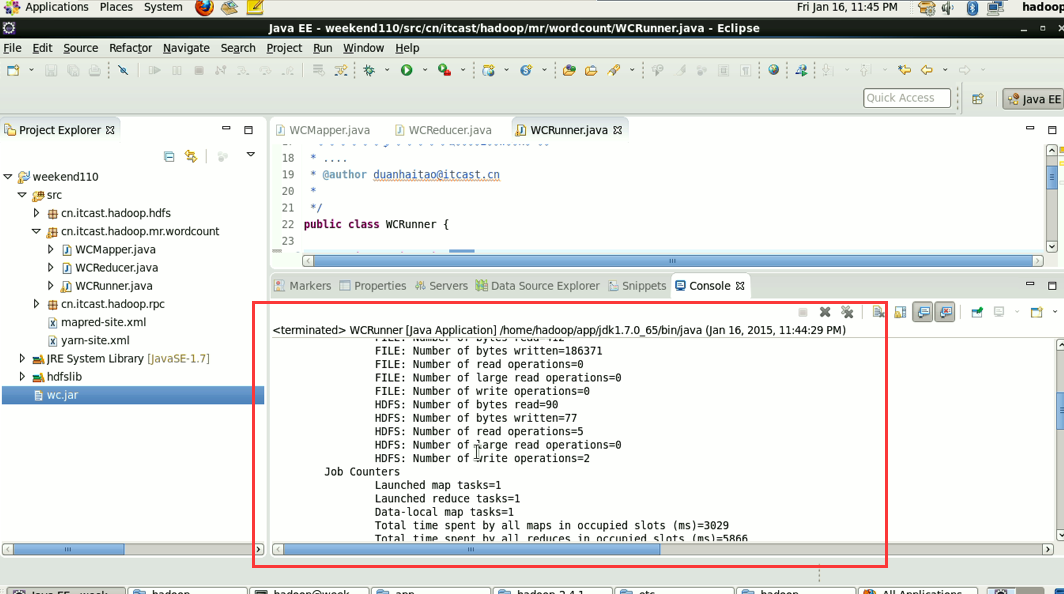
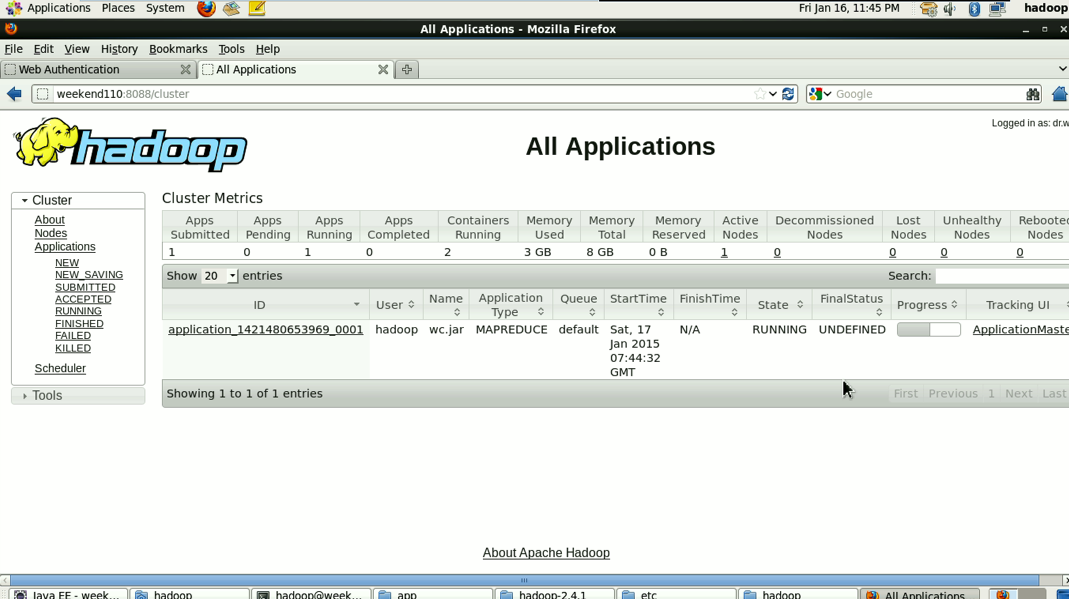
成功!
由此,可以好好比较下,途径1和途径2 和途径3 的区别。

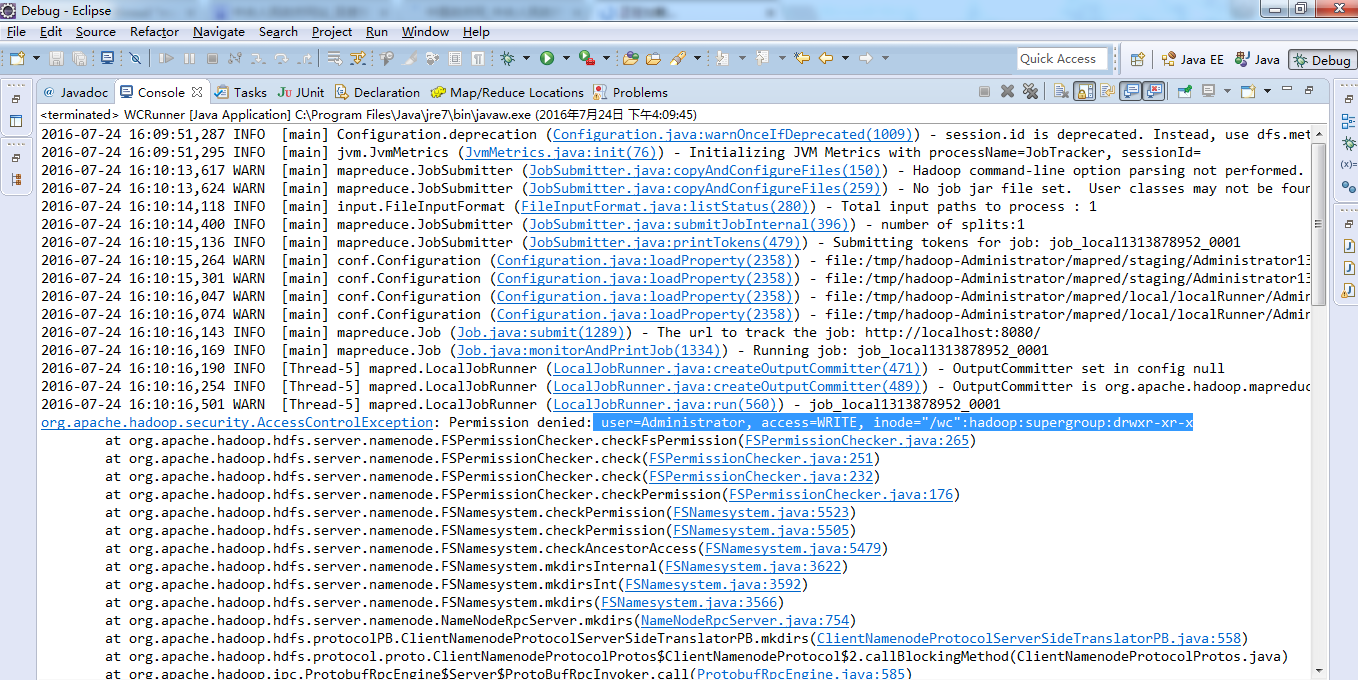
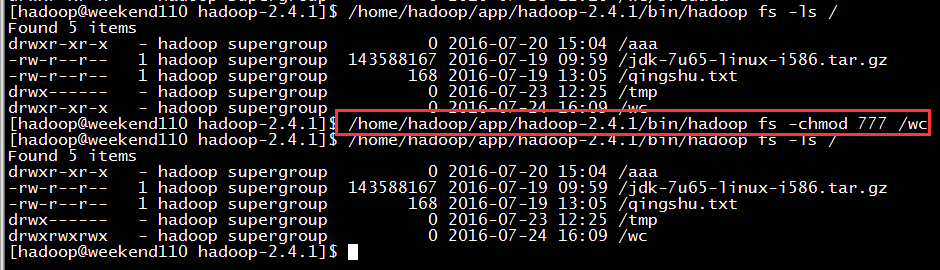
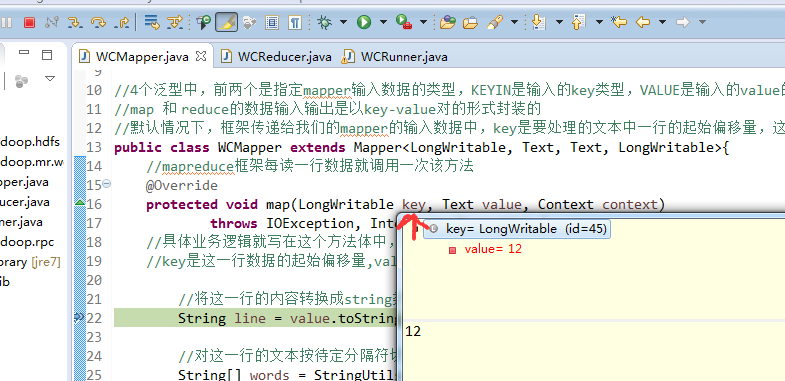
现在,来玩玩weekend110的joba提交的逻辑之源码跟踪
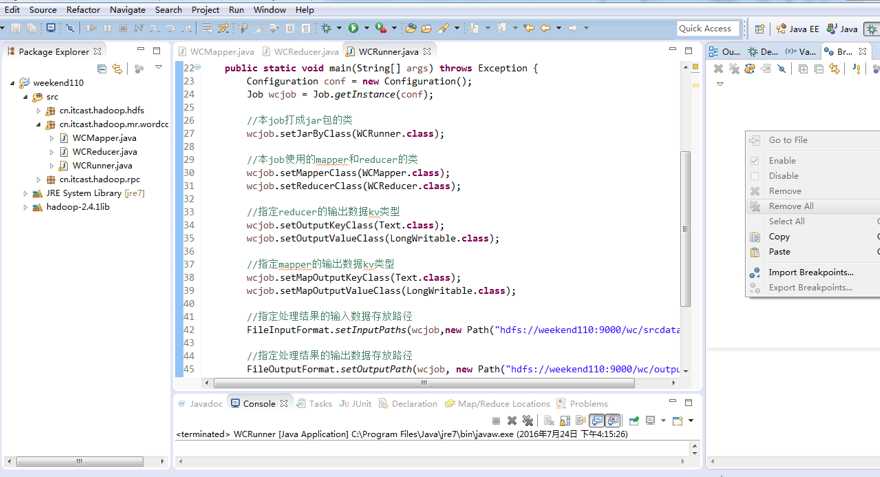


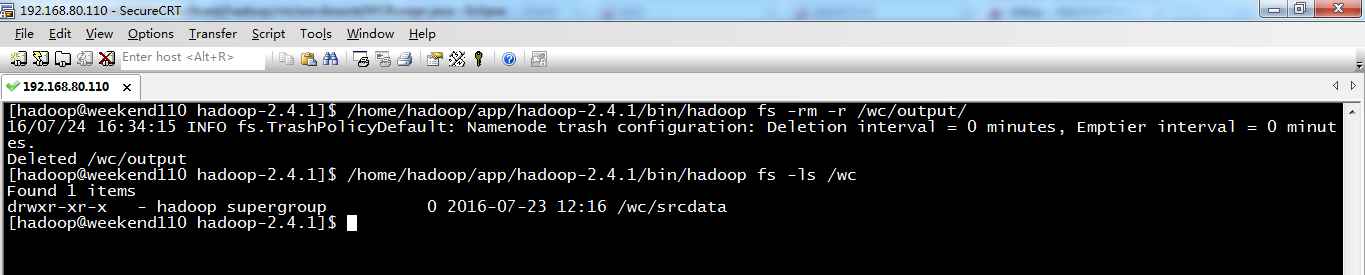
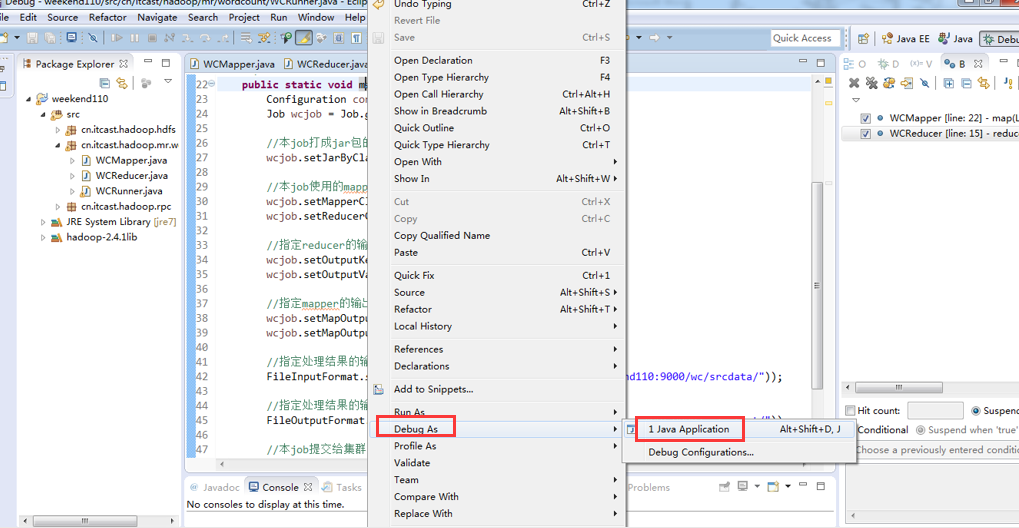
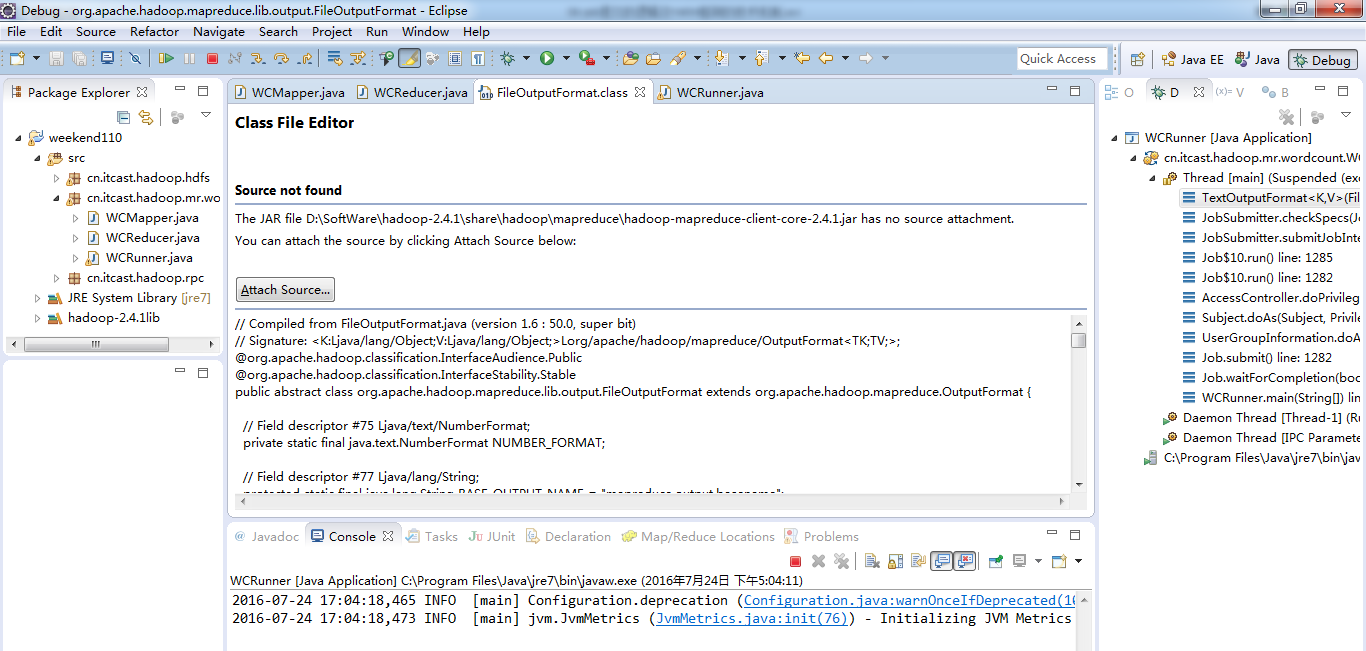
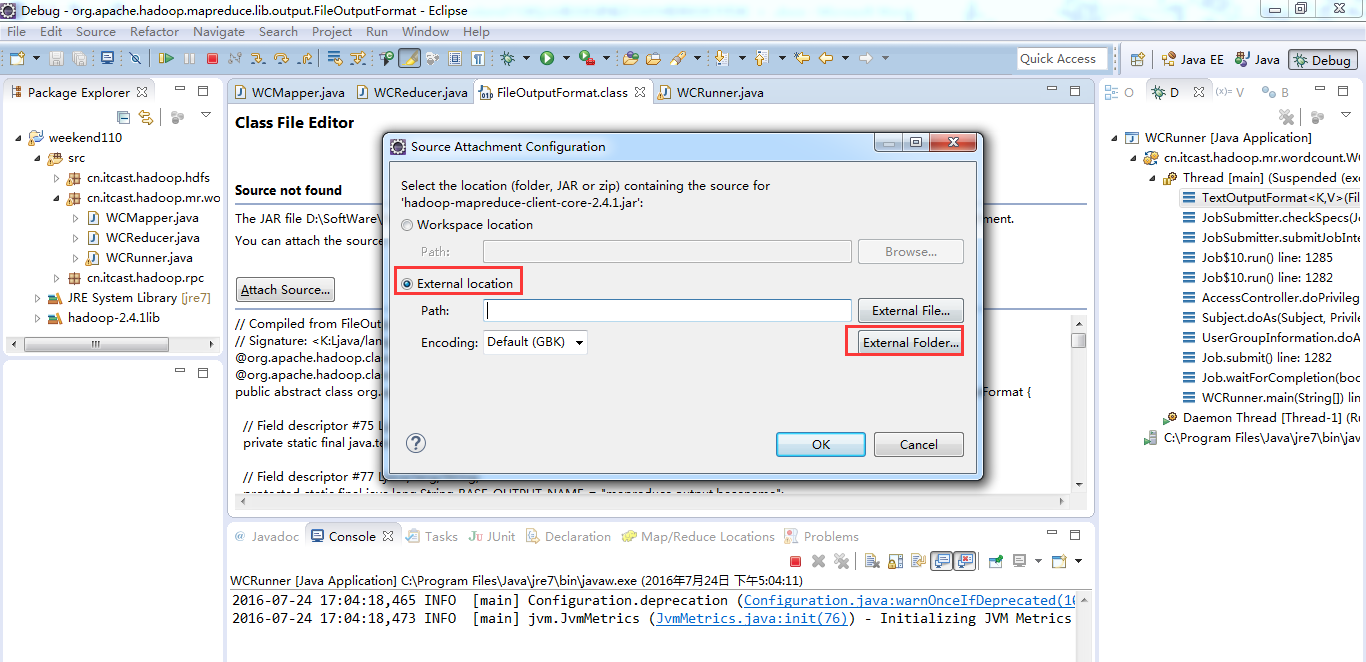
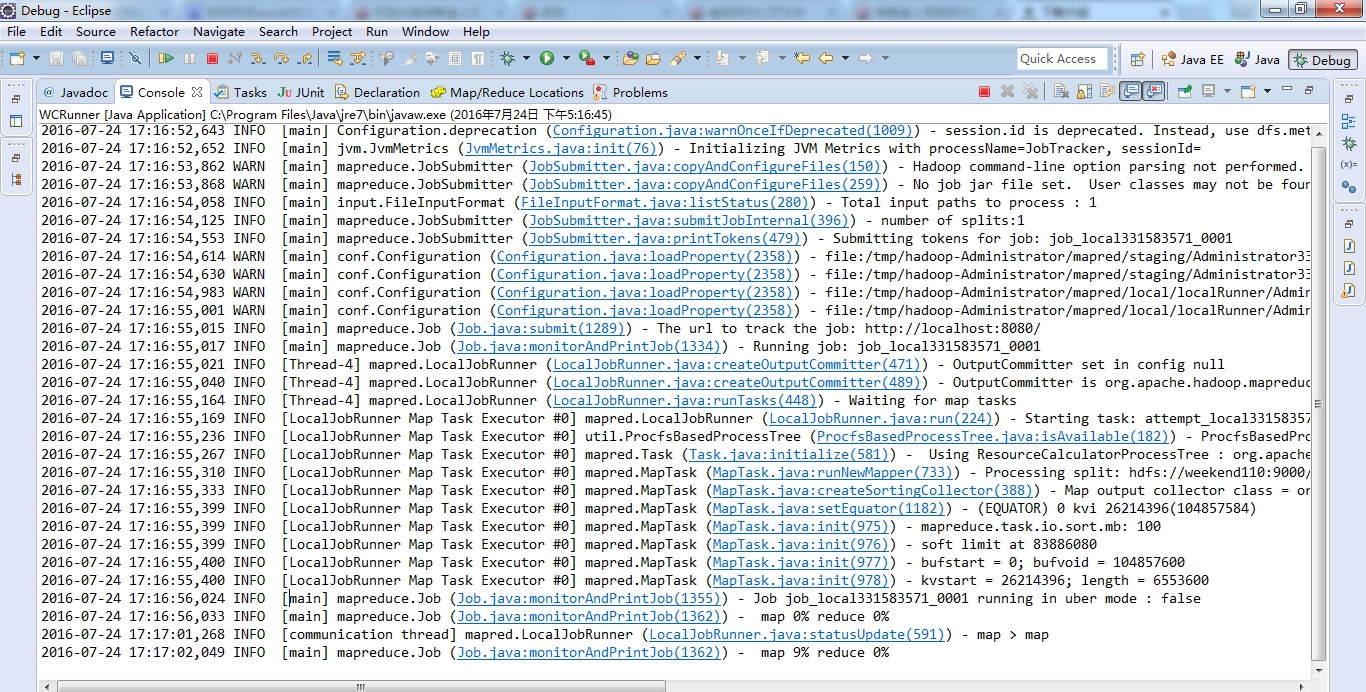
原来如此,weekend110的job提交的逻辑源码,停在这了
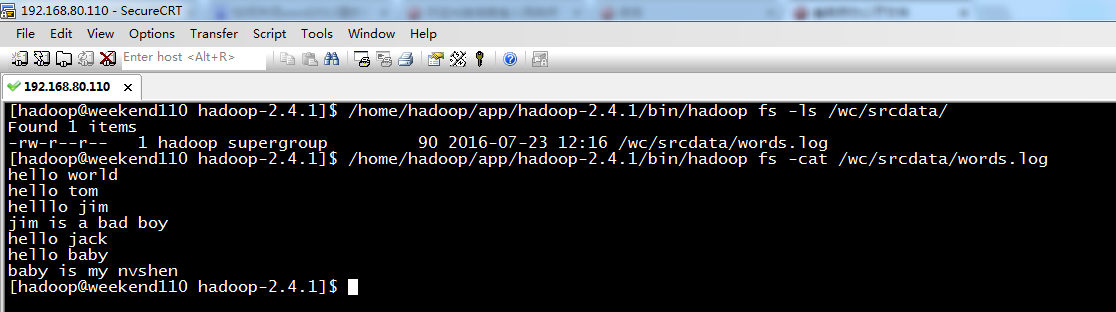
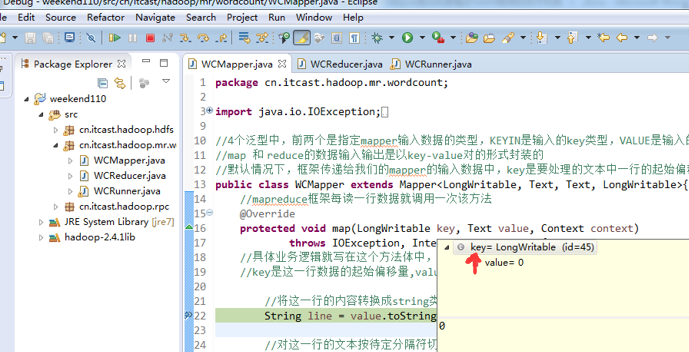
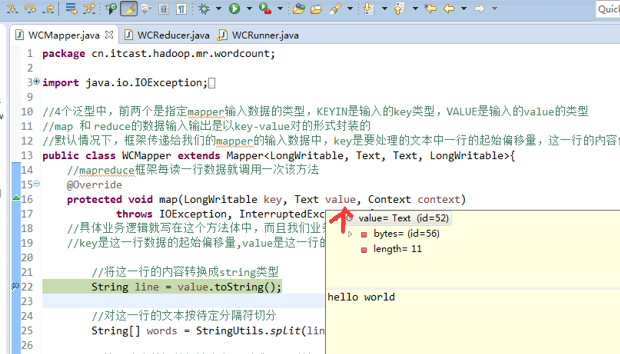
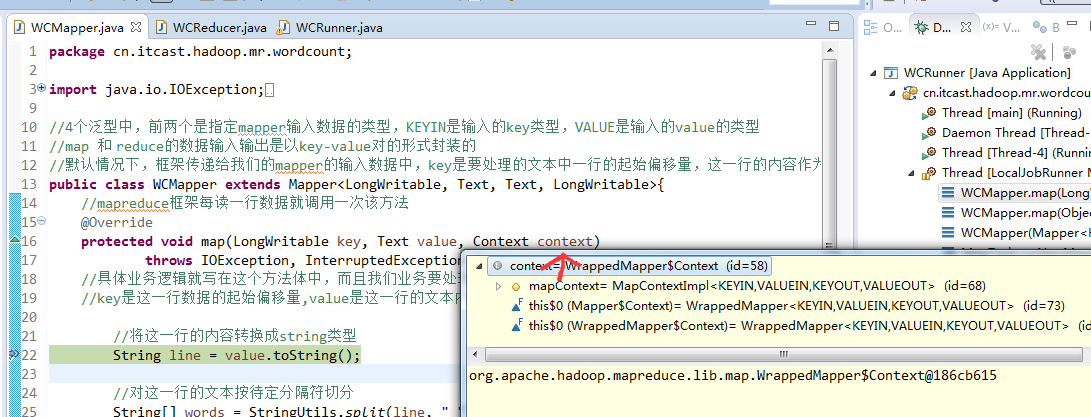
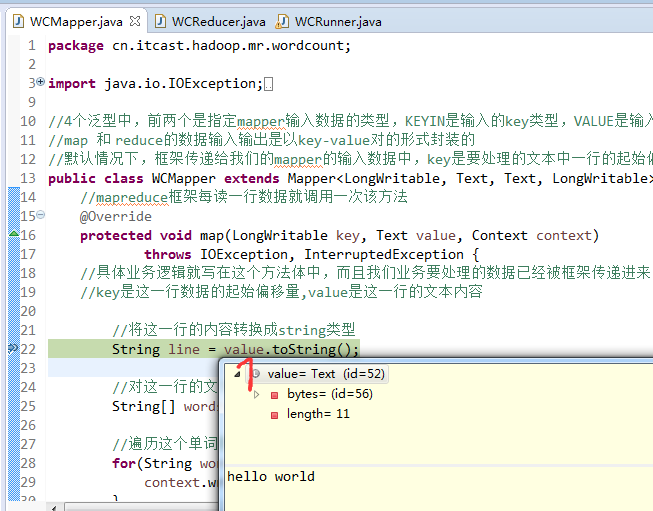










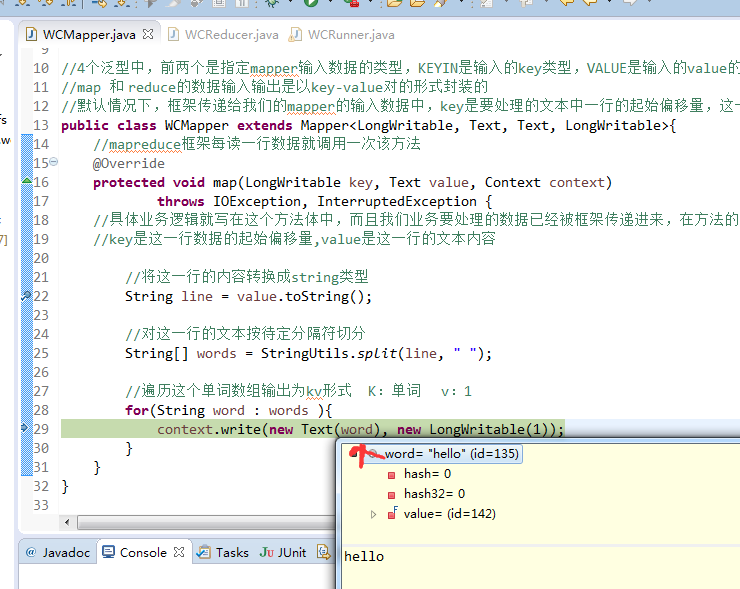
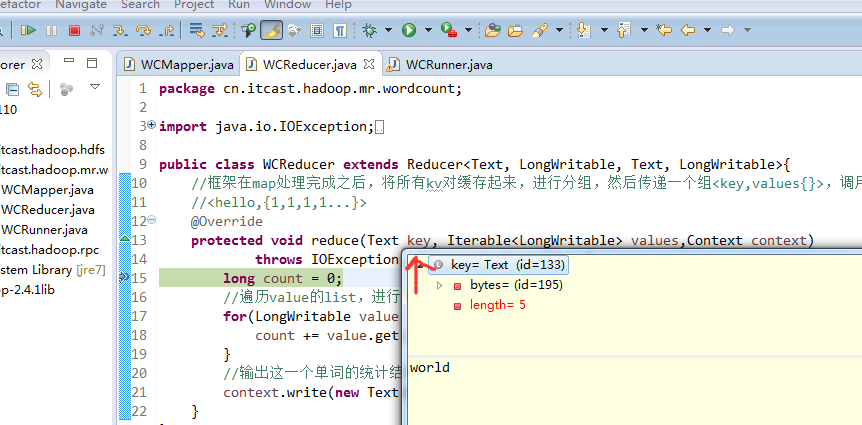
hello world
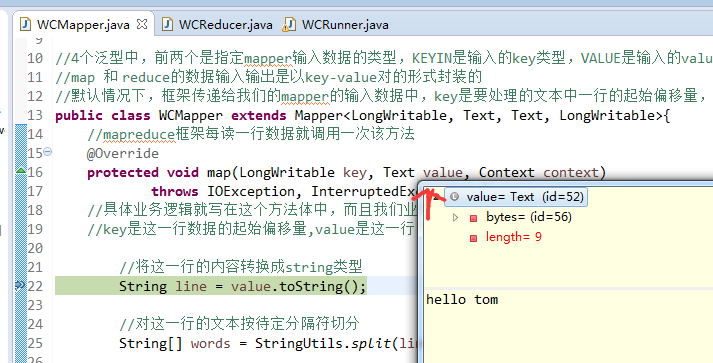
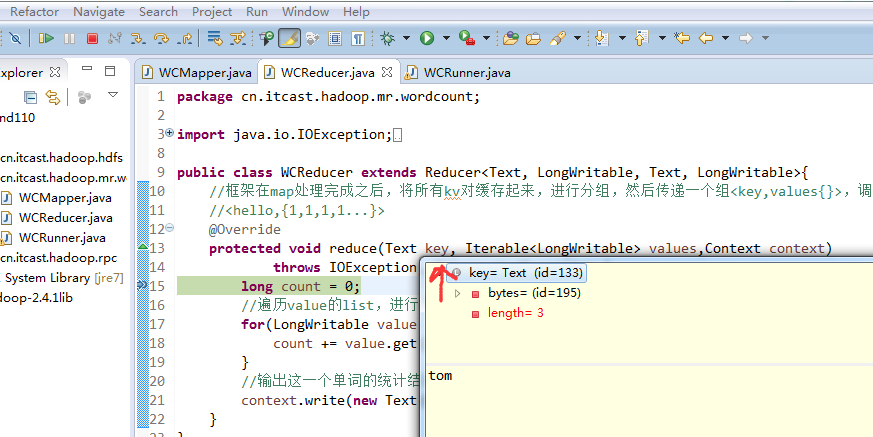
hello tom
helllo jim
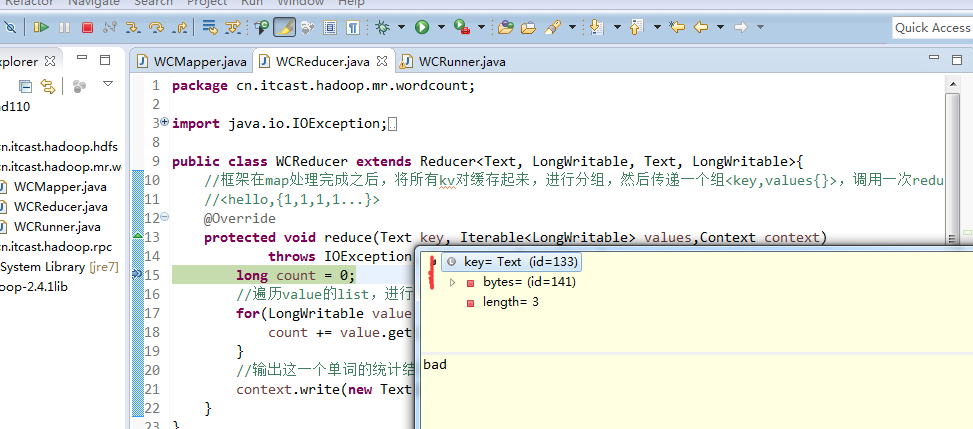
jim is a bad boy
hello jack
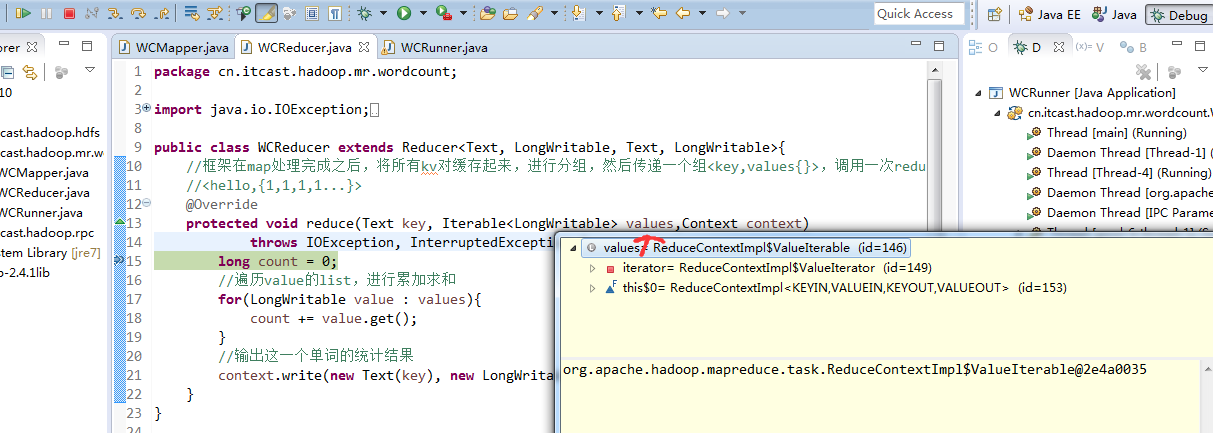
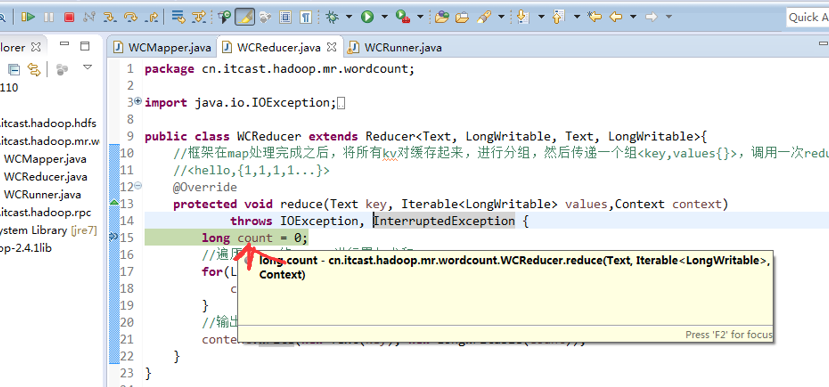
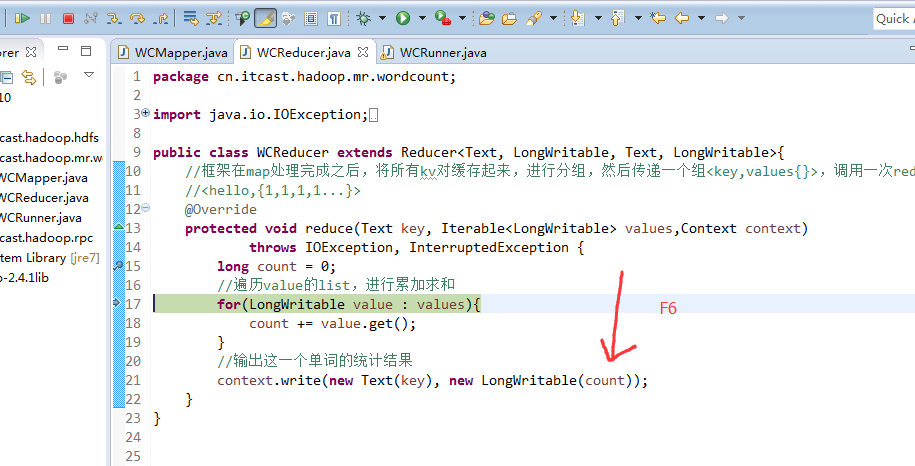
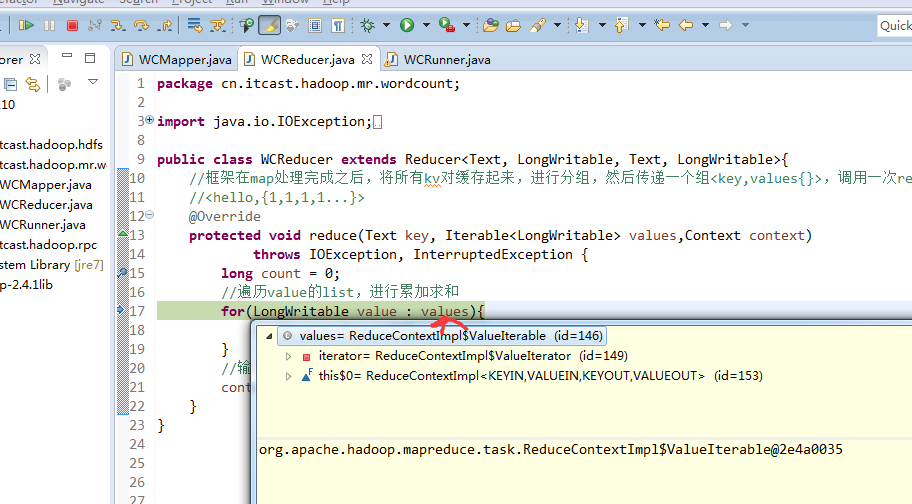
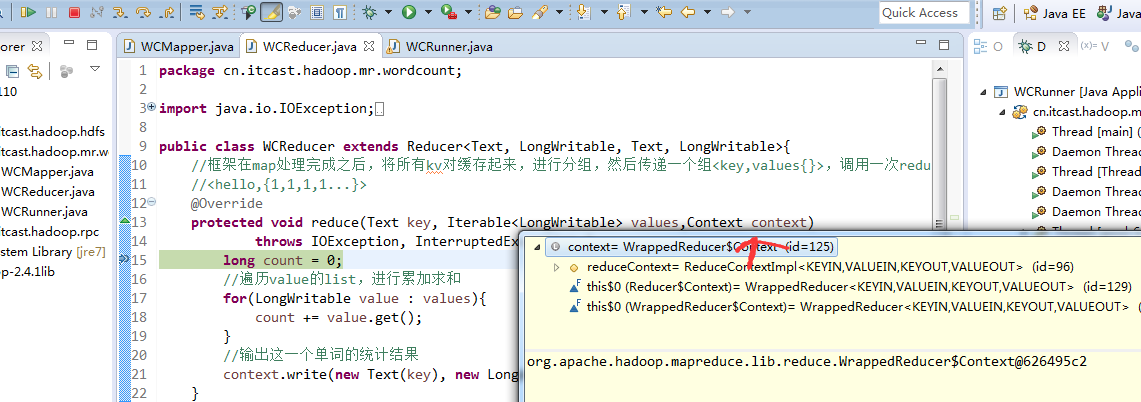
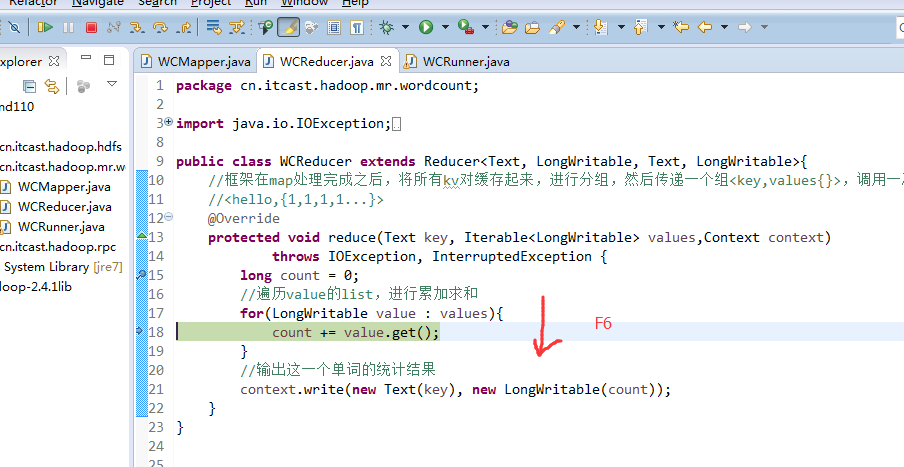
hello baby
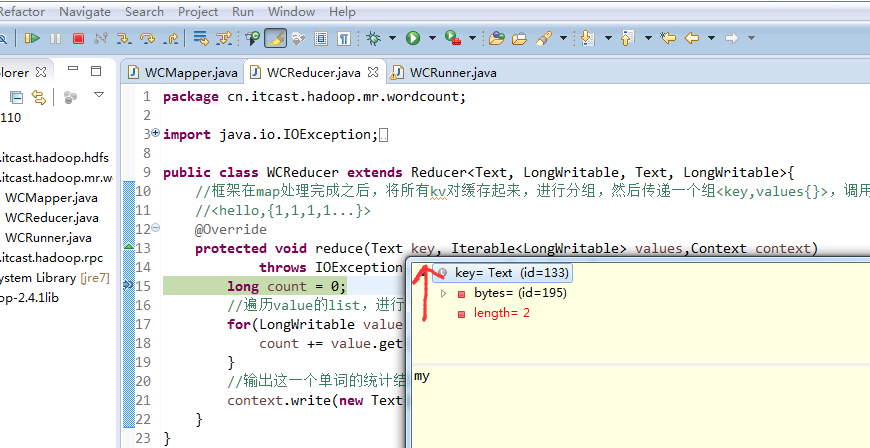
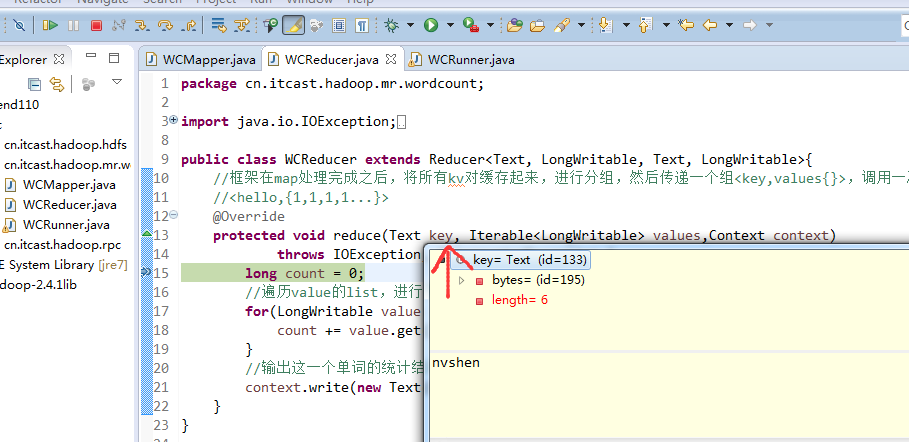
baby is my nvshen

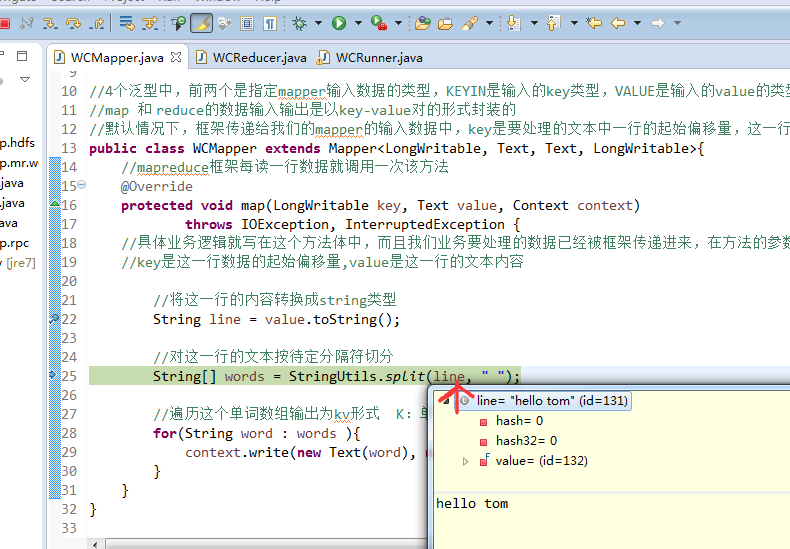
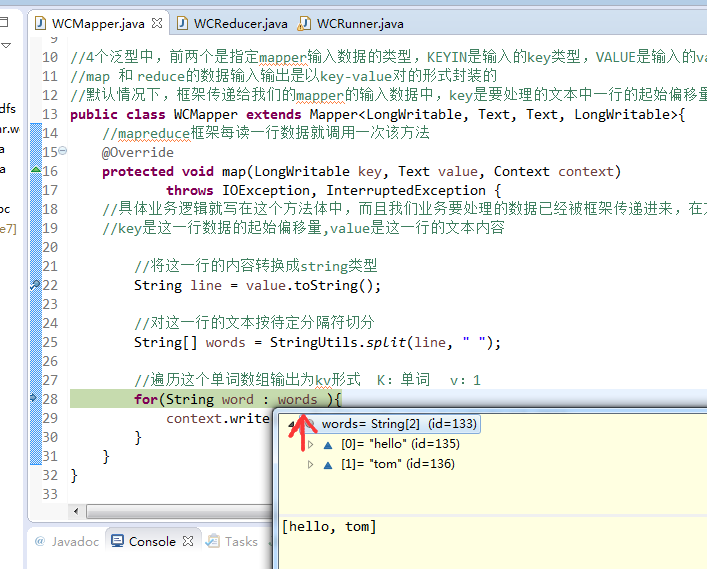


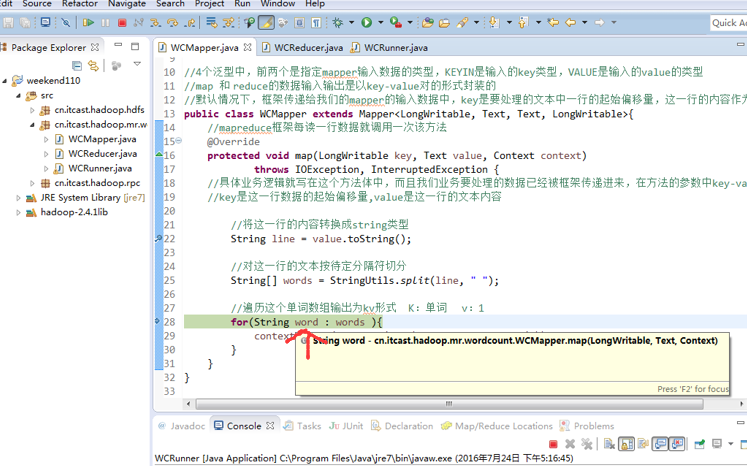
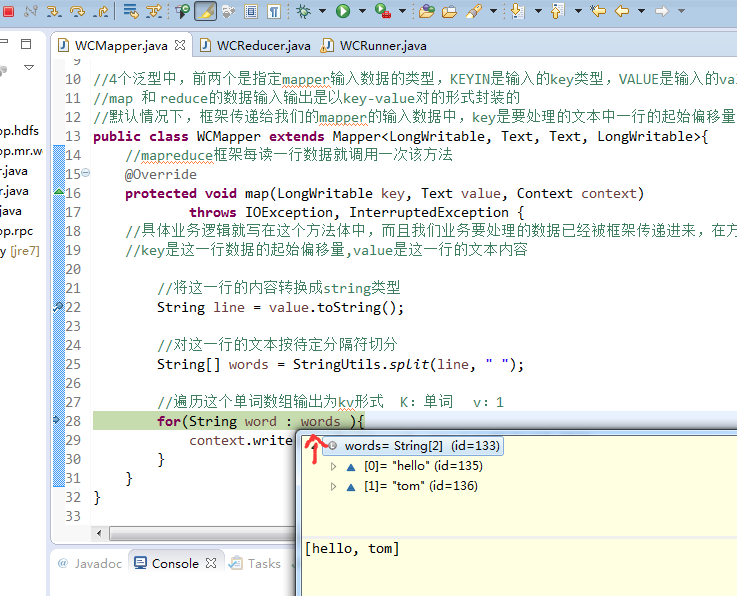
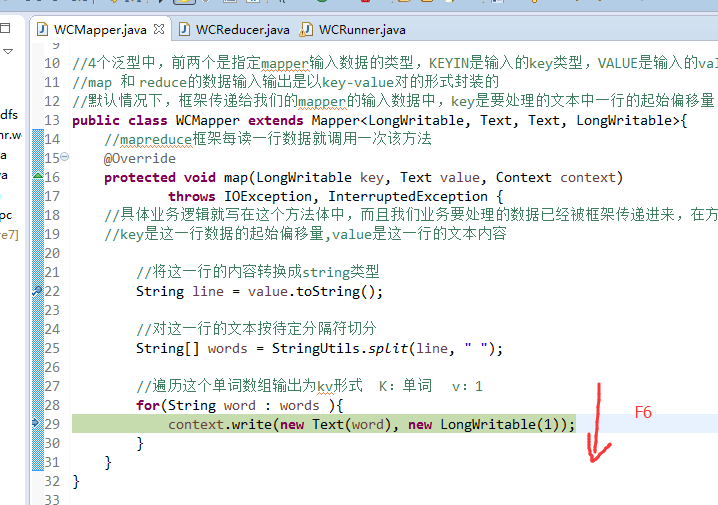

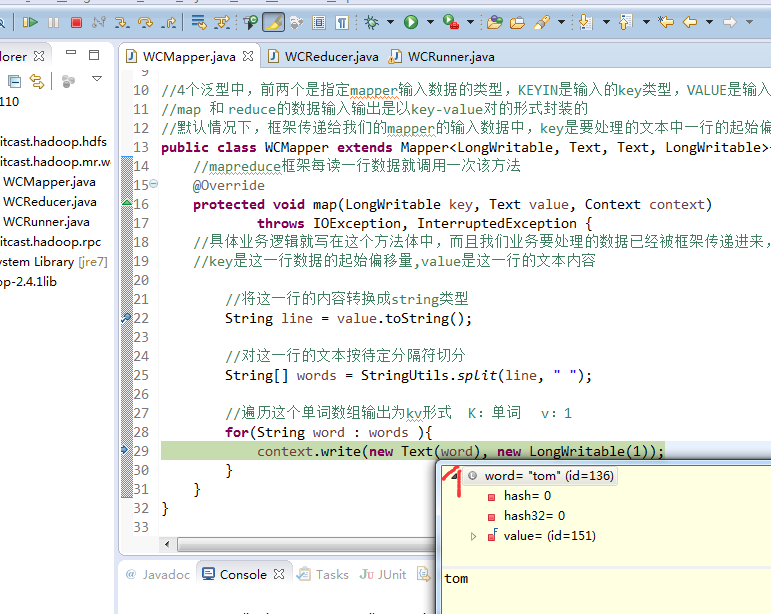




hello world
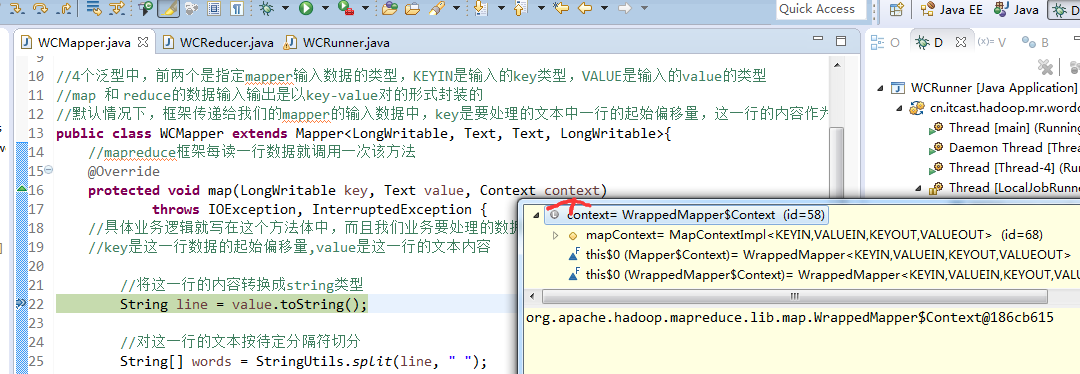
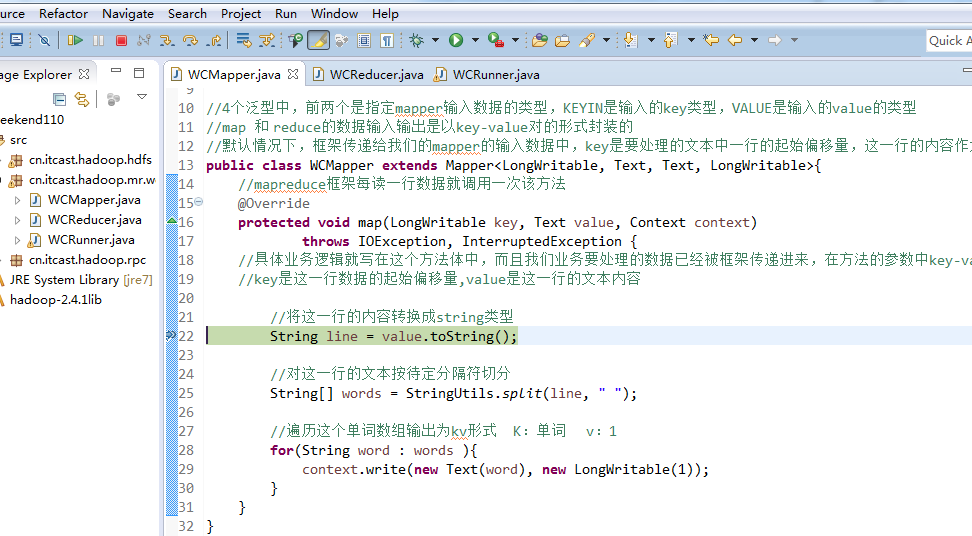
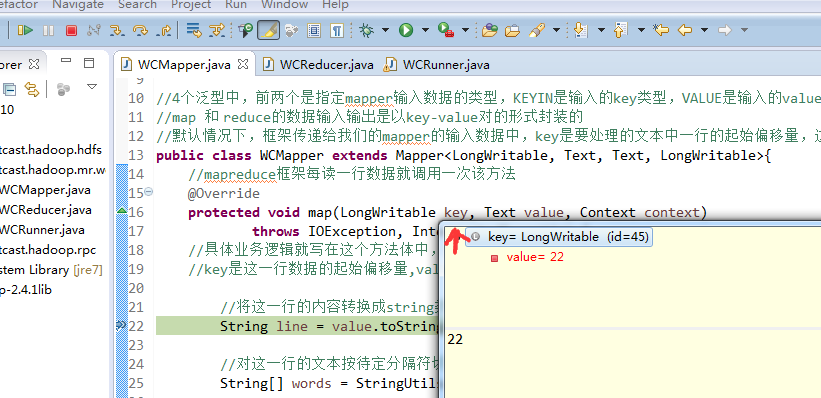
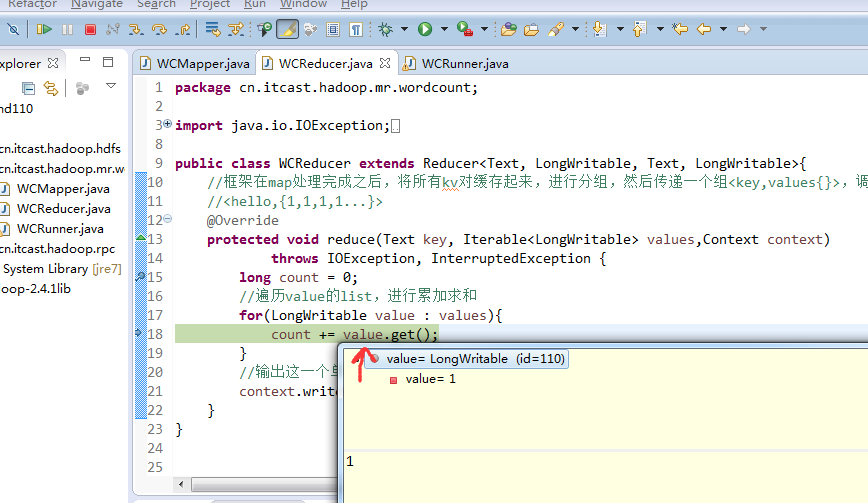
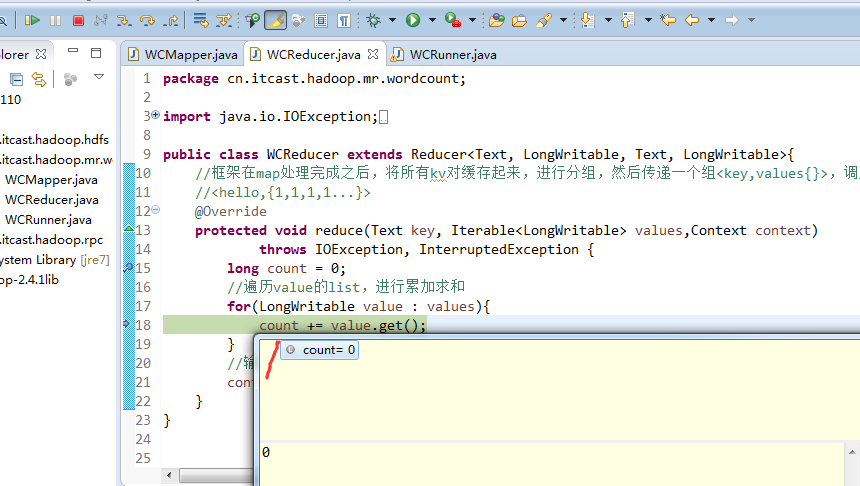
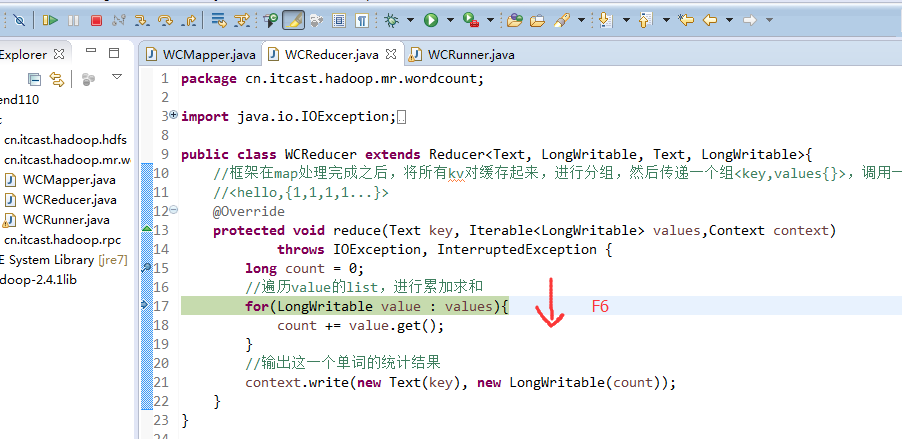
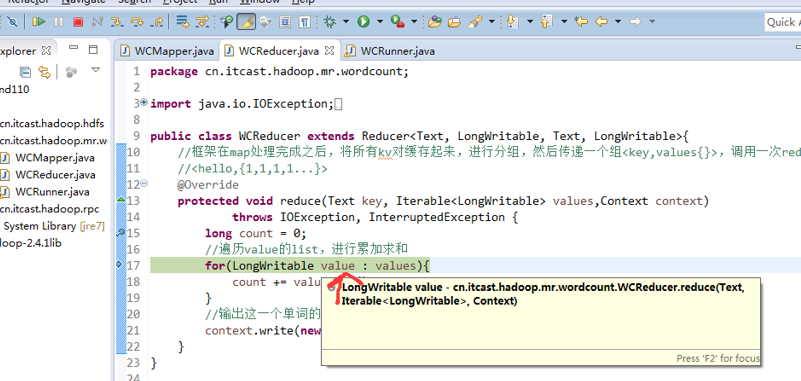
hello tom
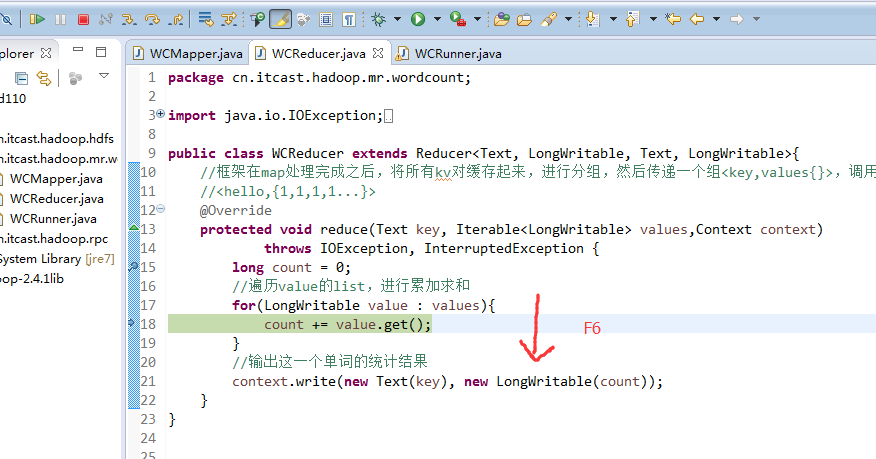
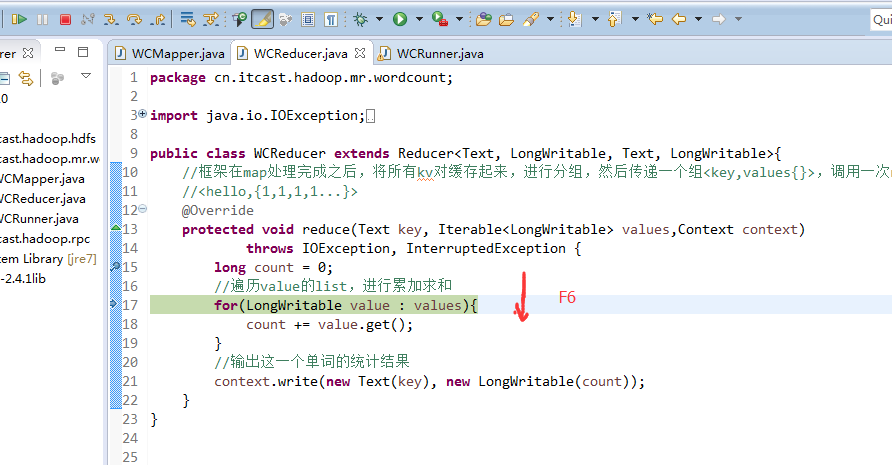
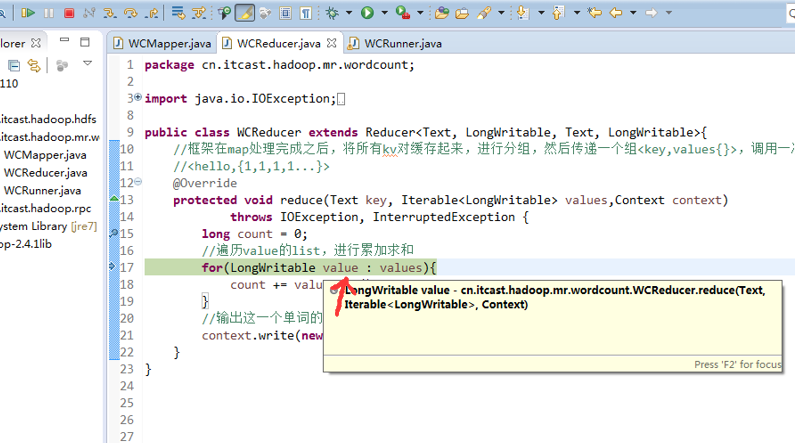
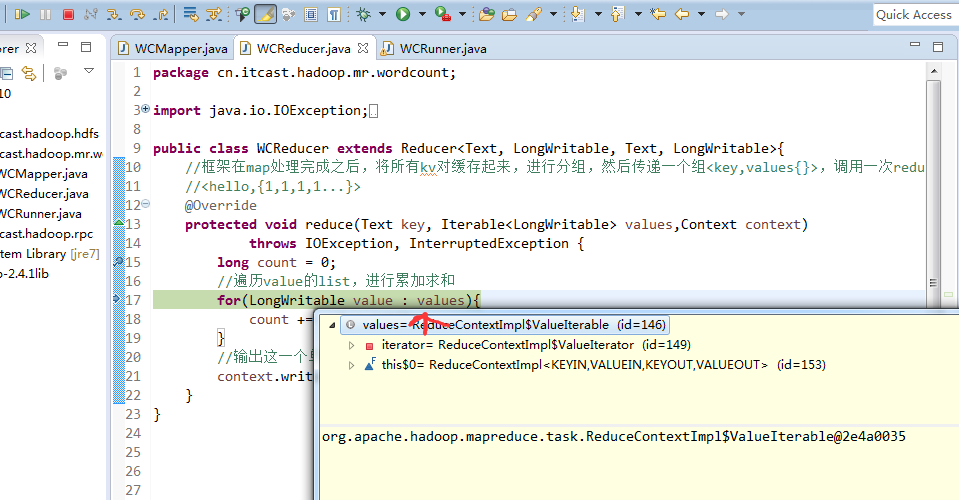
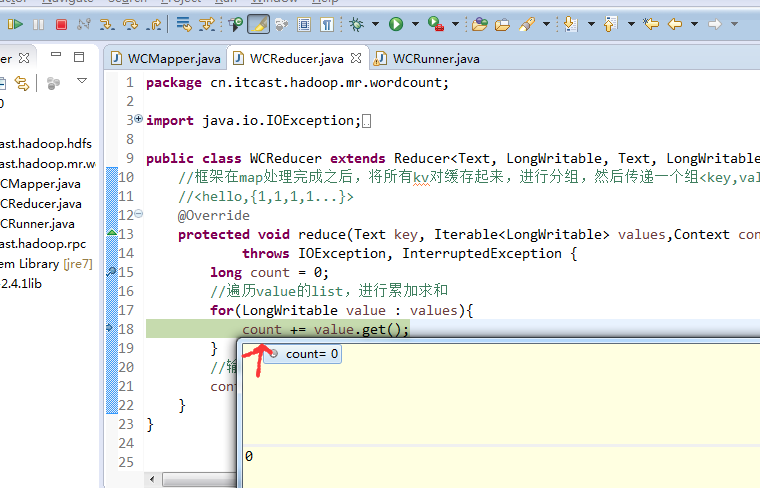
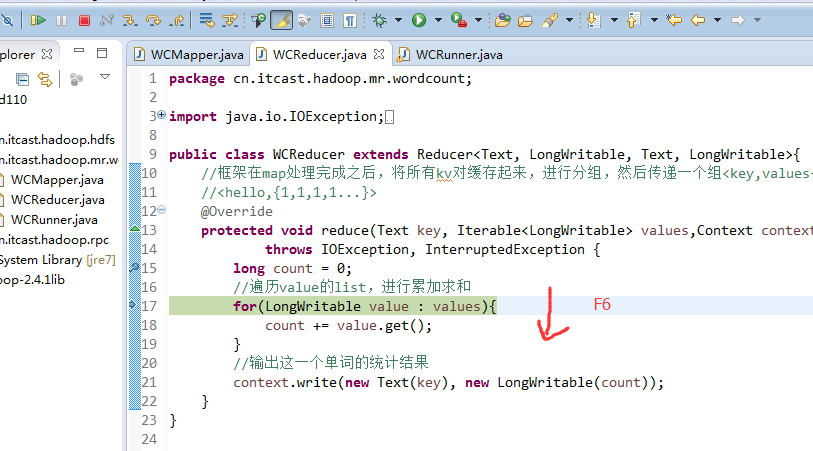
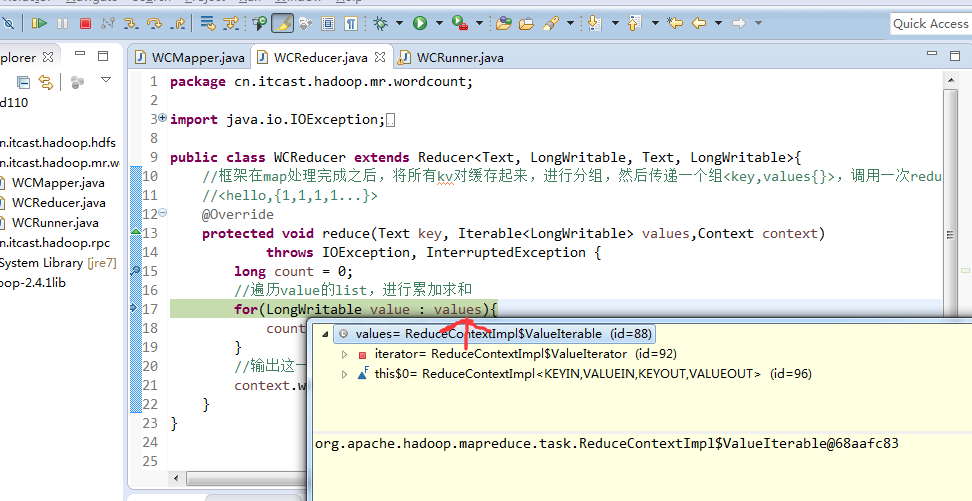
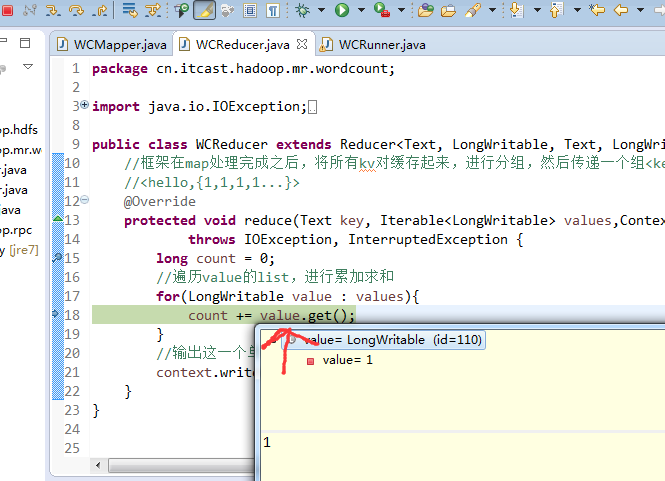
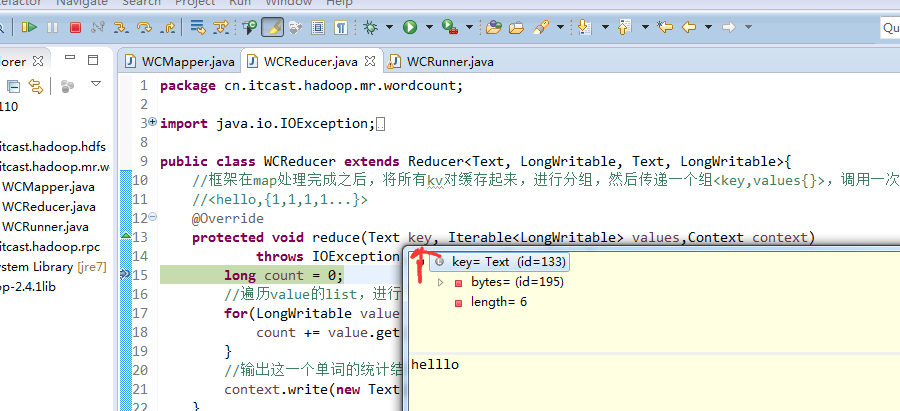
helllo jim
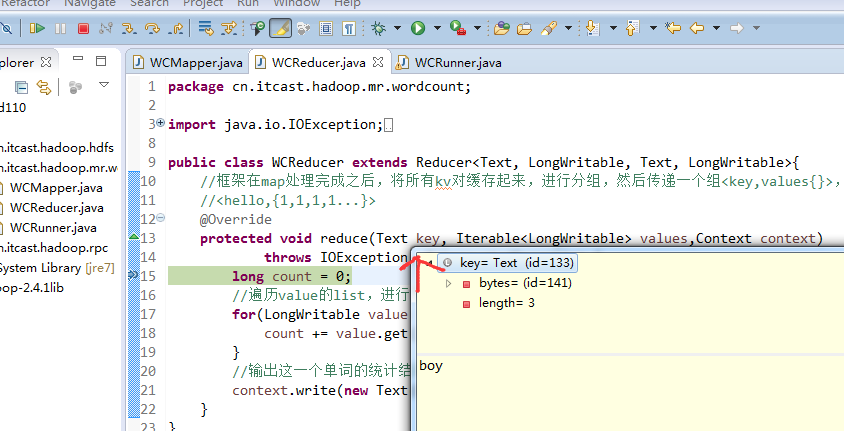
jim is a bad boy
hello jack
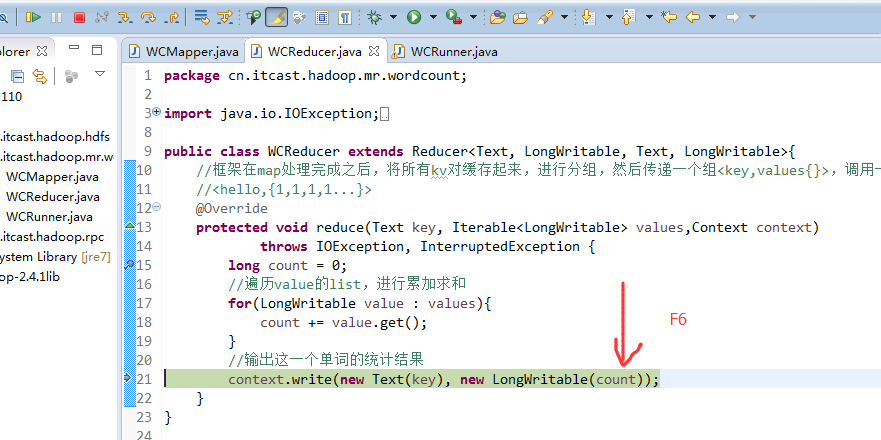
hello baby
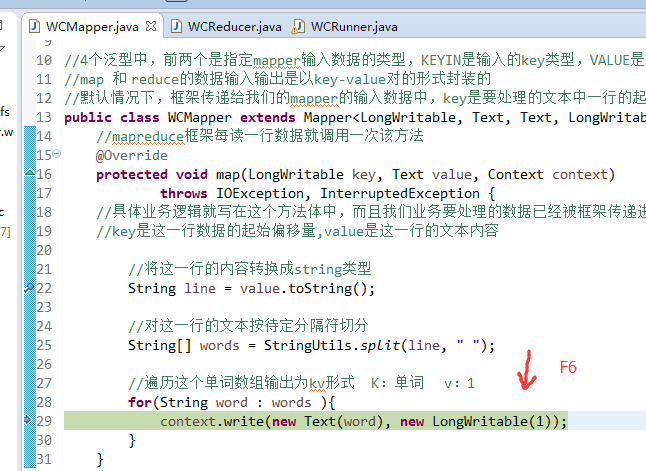
baby is my nvshen
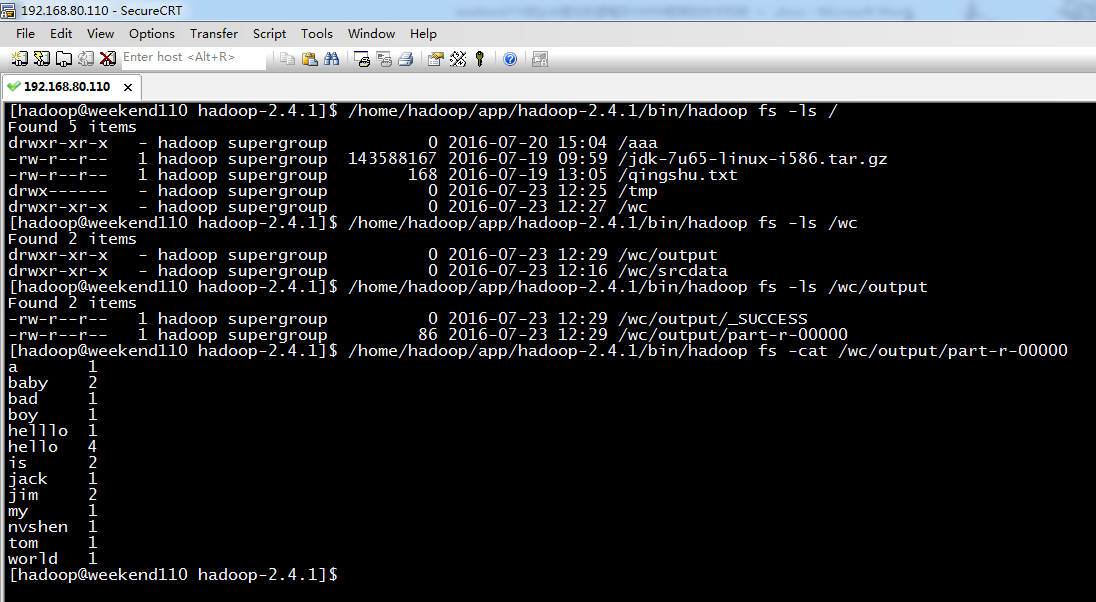
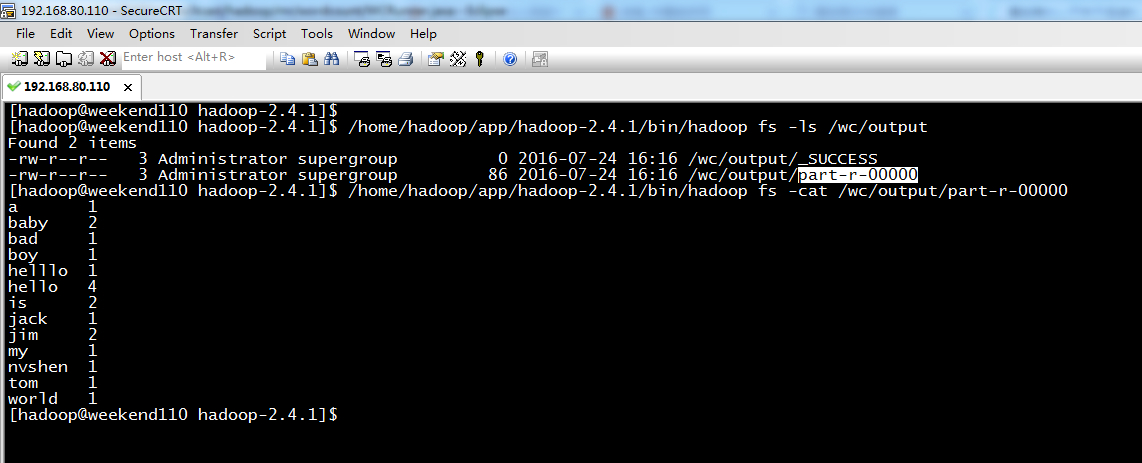
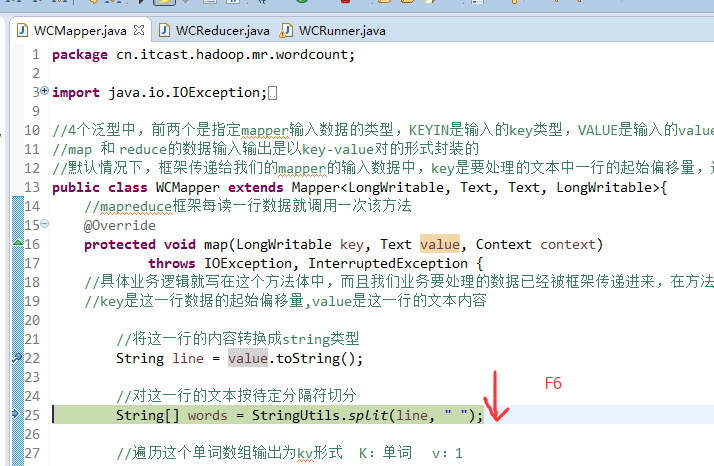
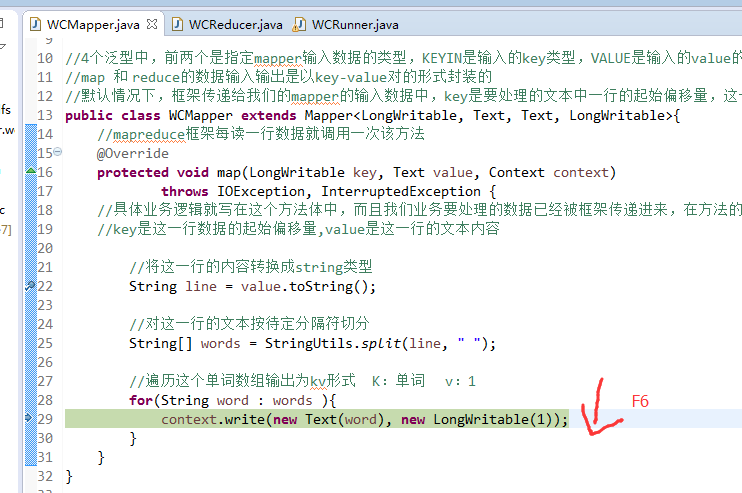
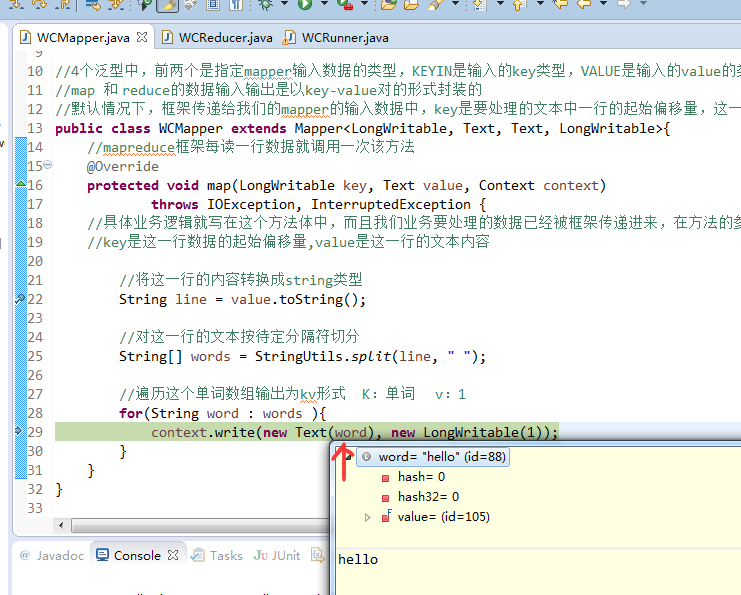
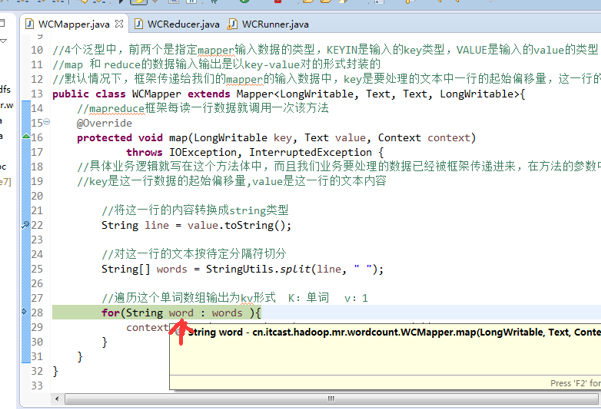
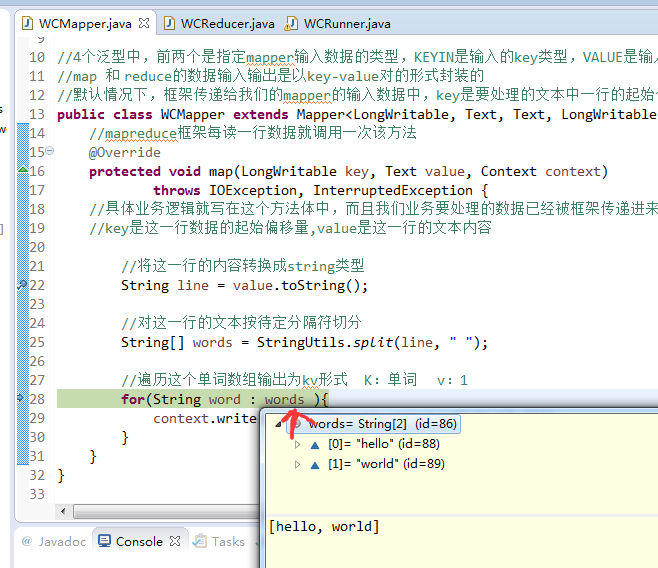
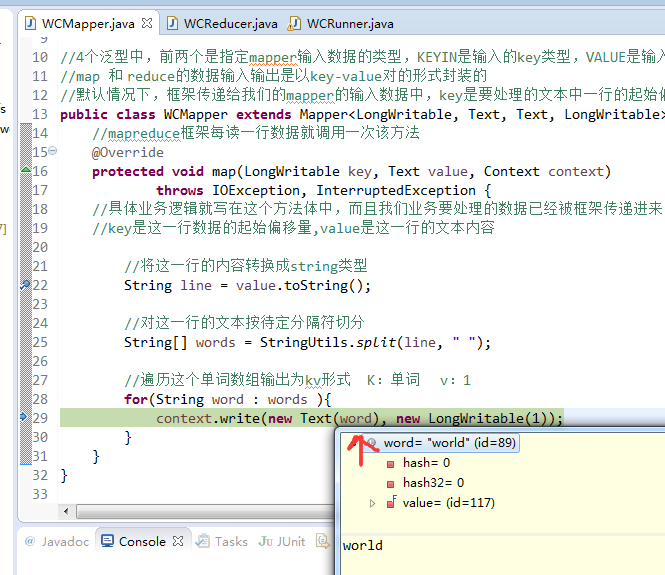
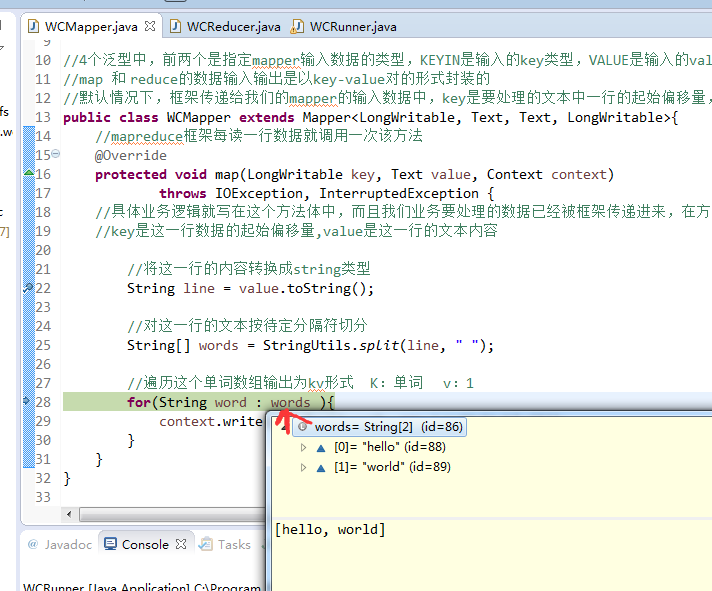
不再一个一个放了。直接放完吧,map
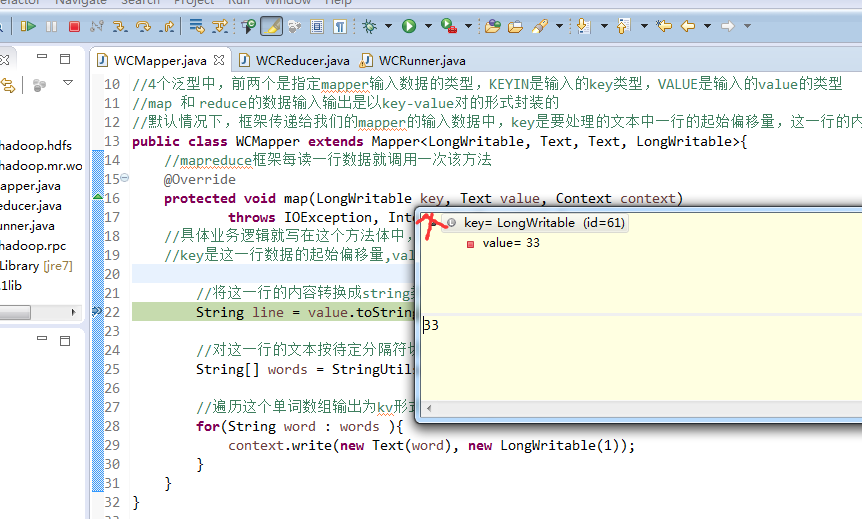
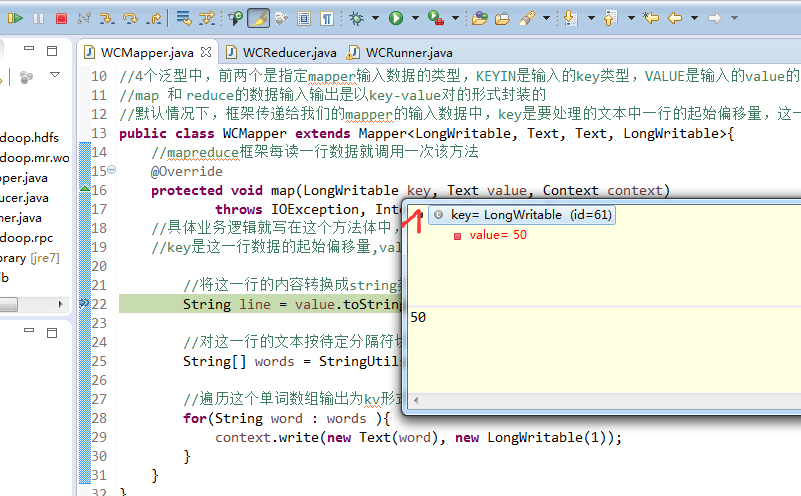

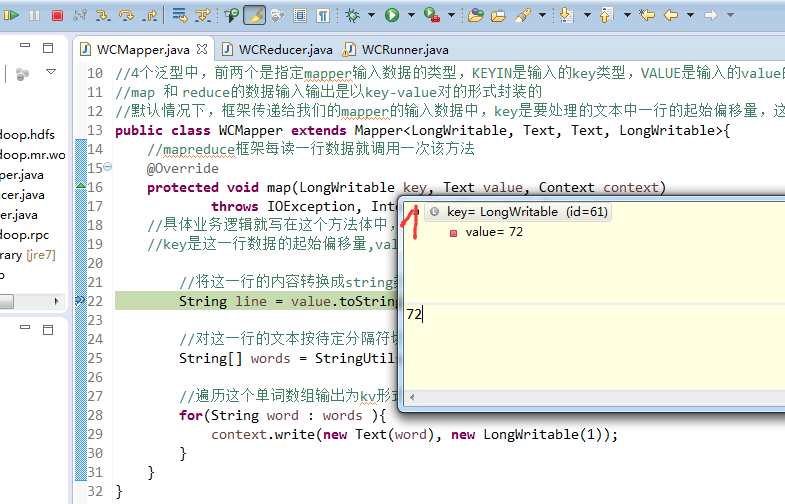
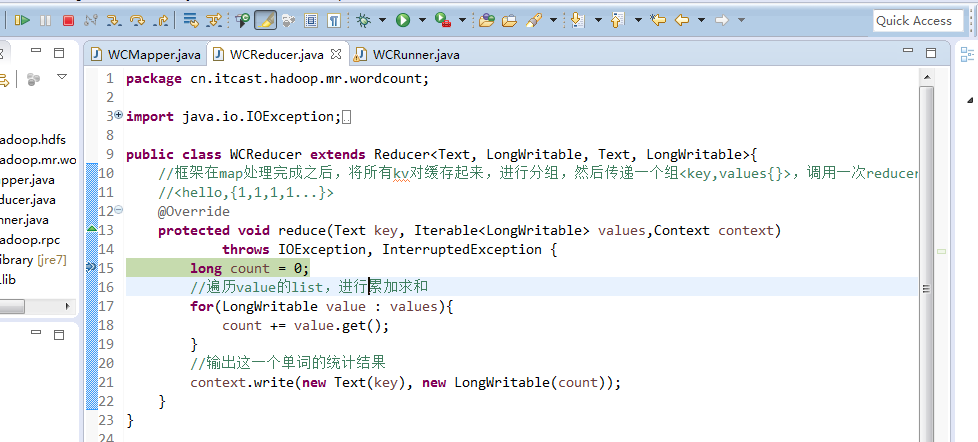
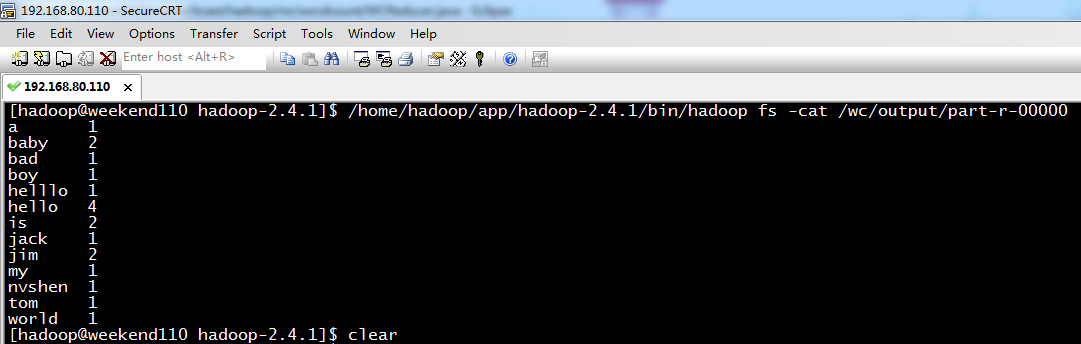
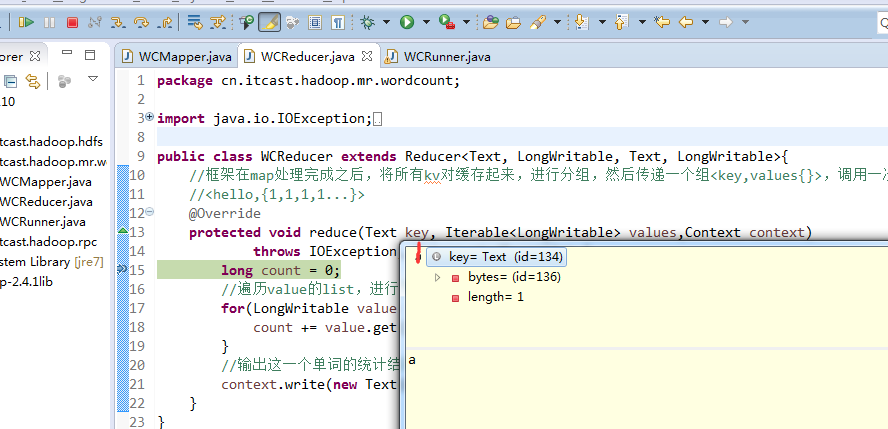




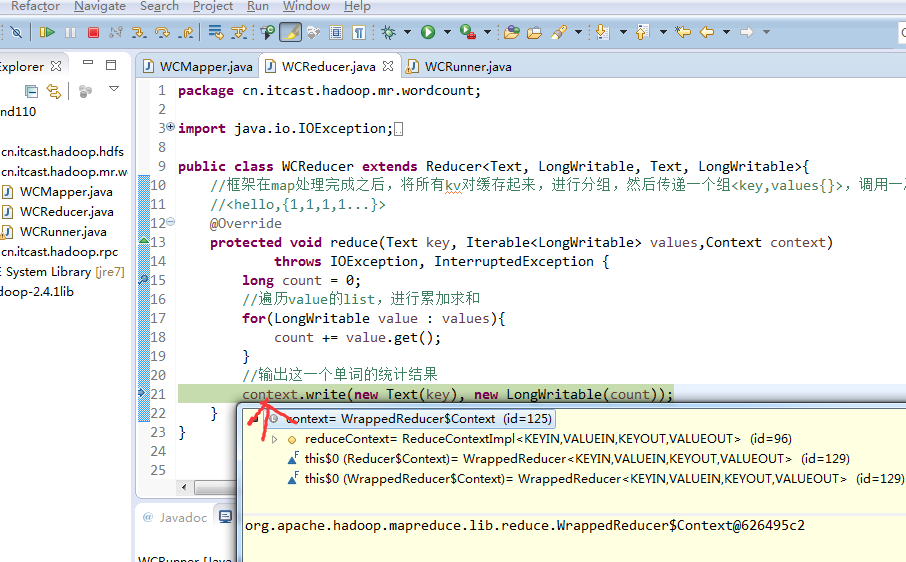

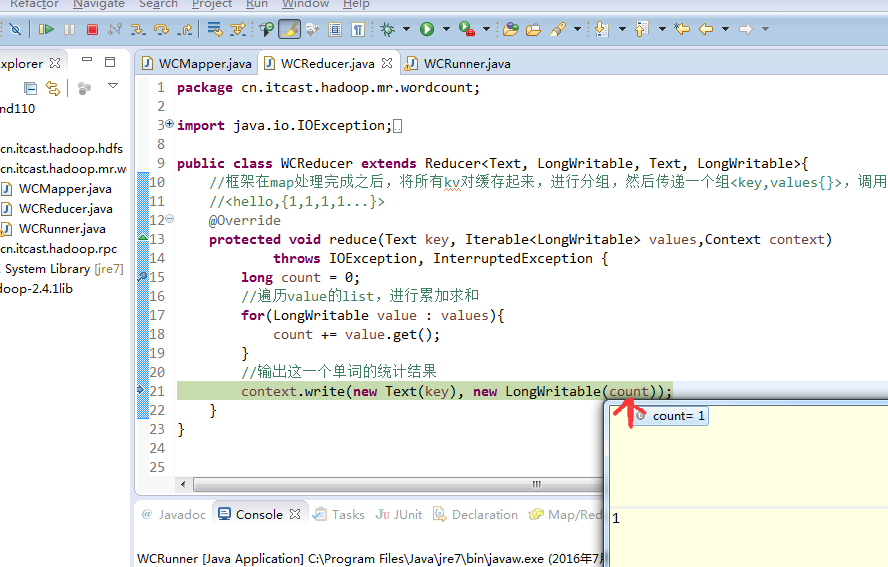

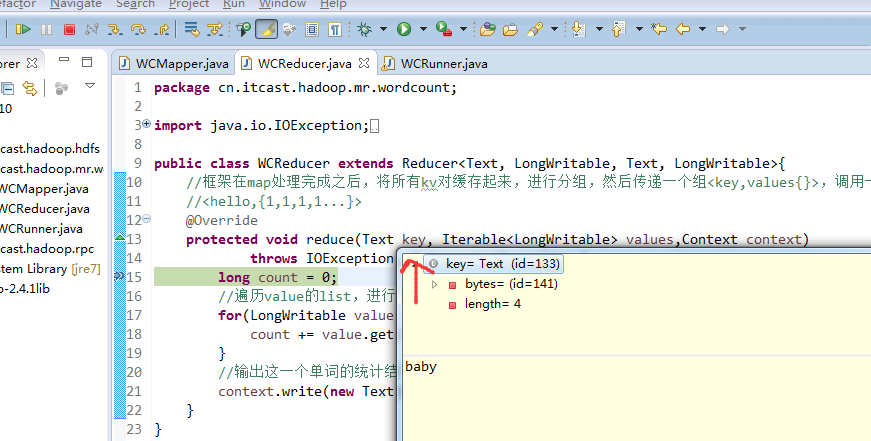




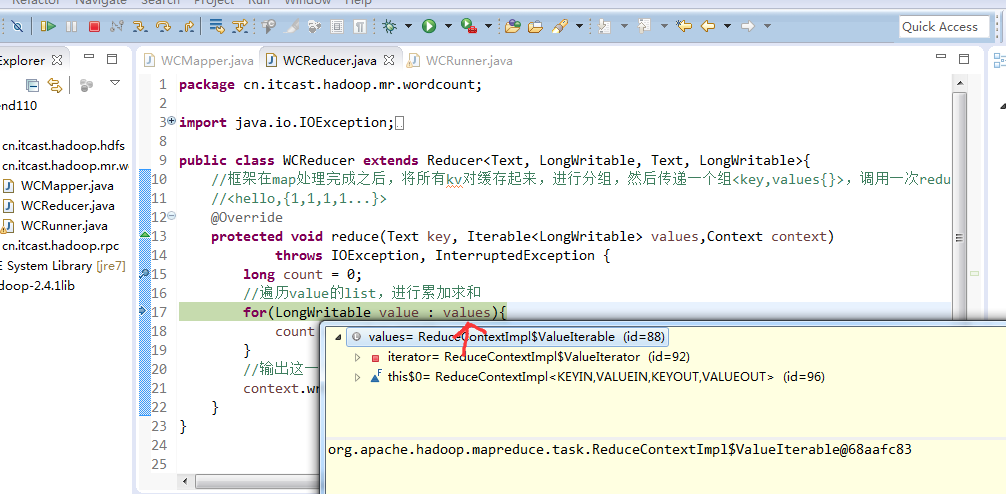
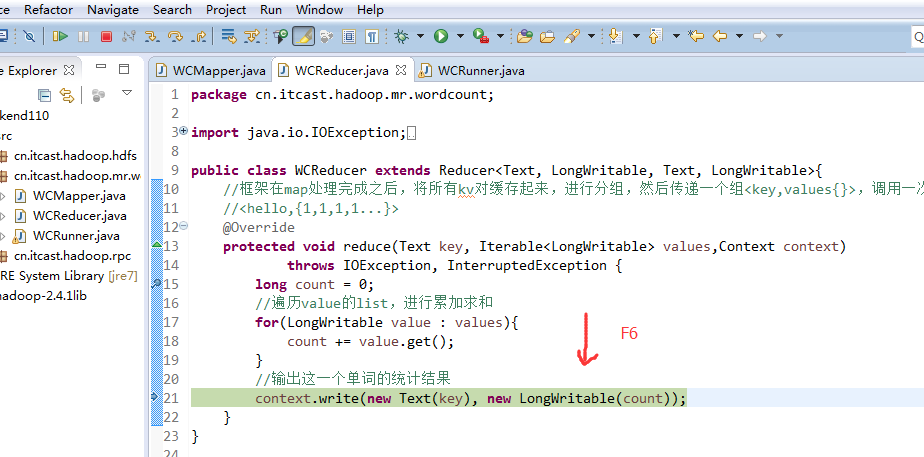
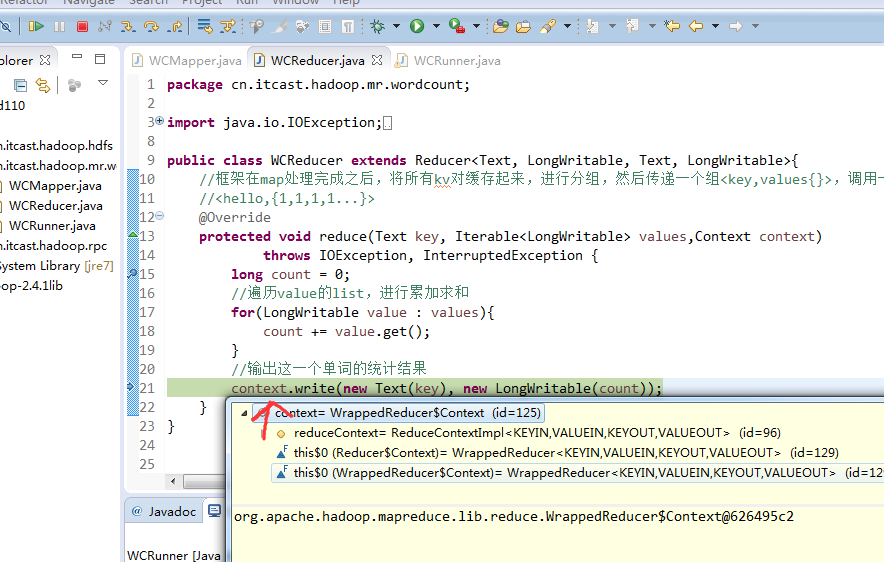
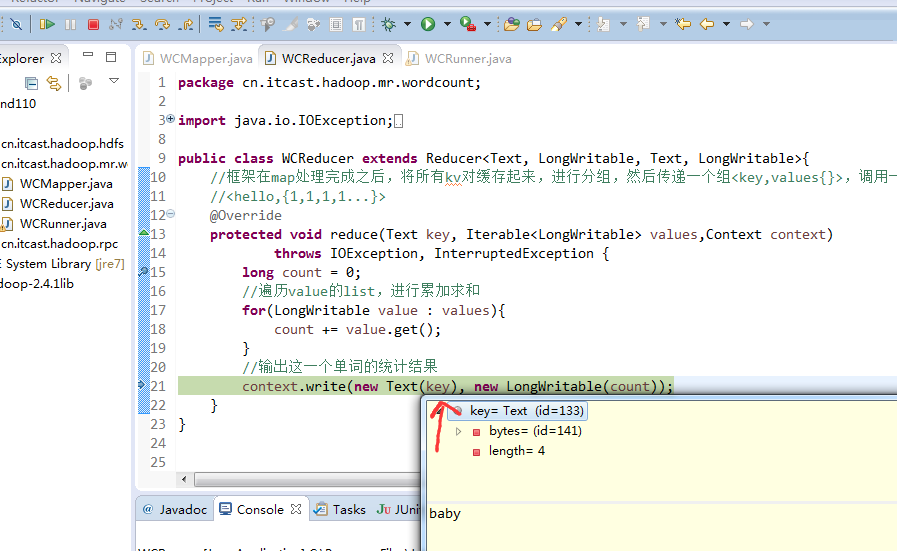

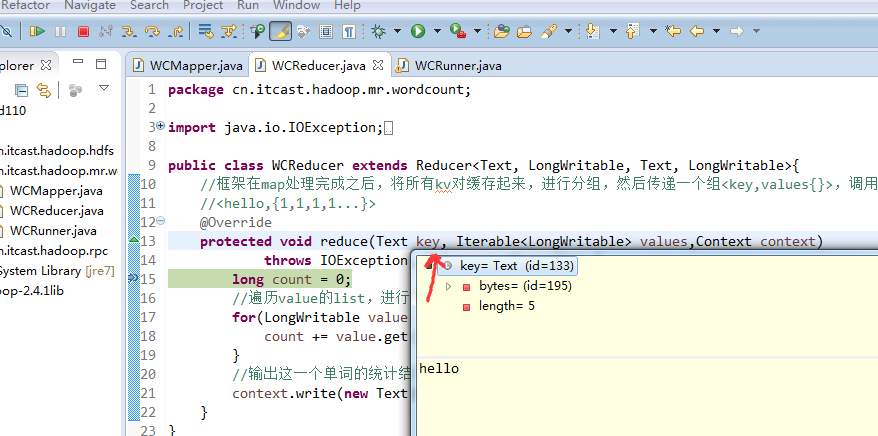
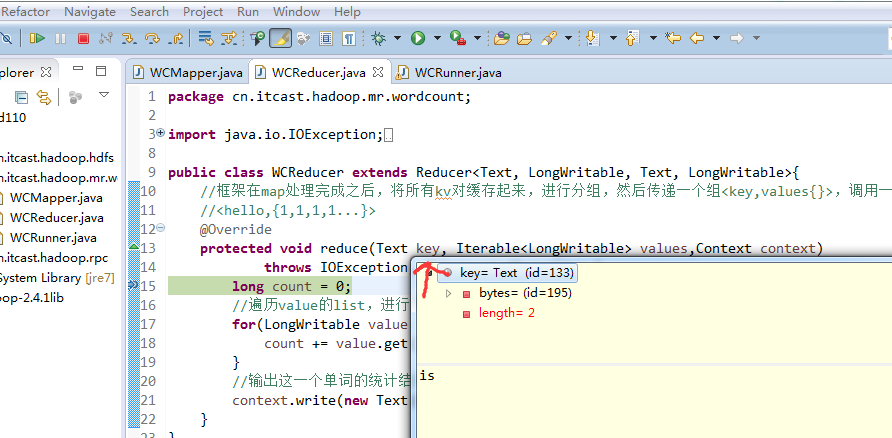
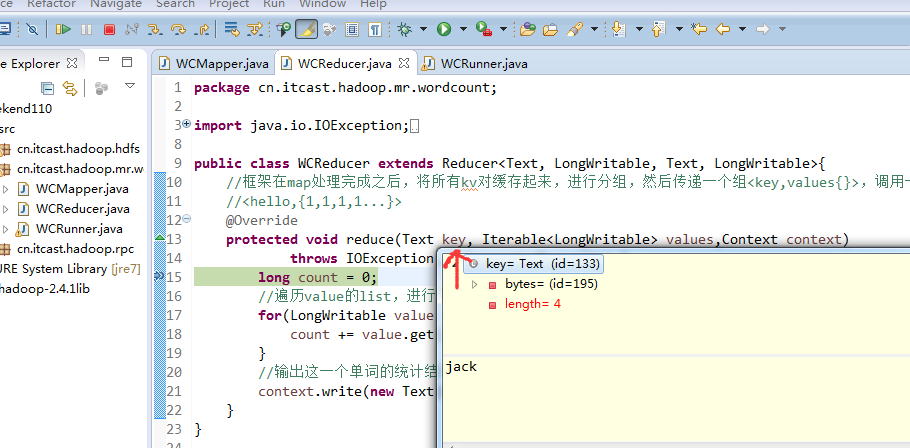
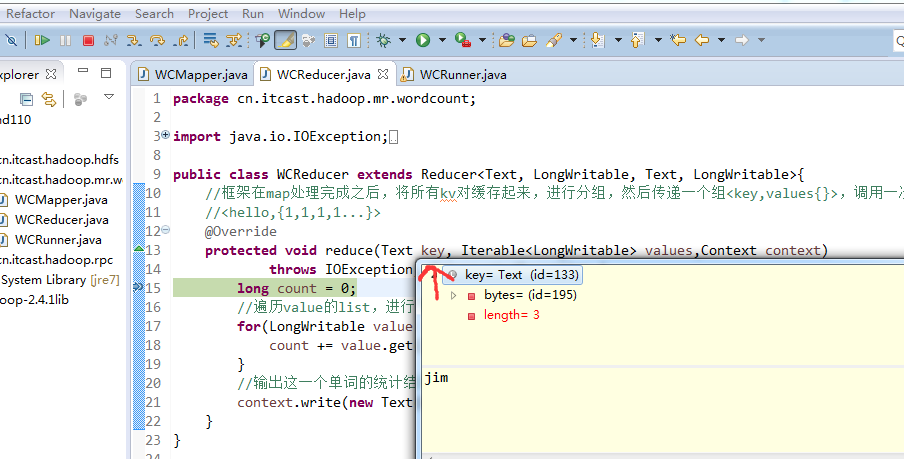
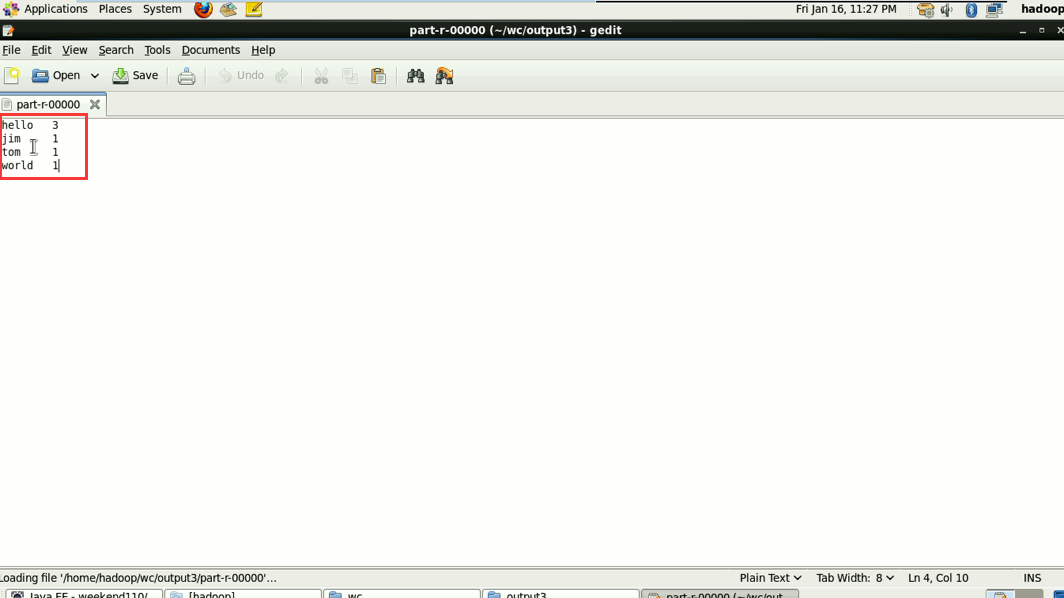
a 1
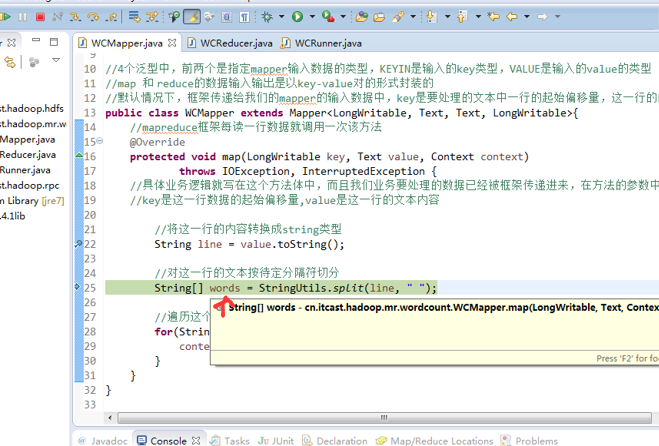
baby 2
bad 1
boy 1
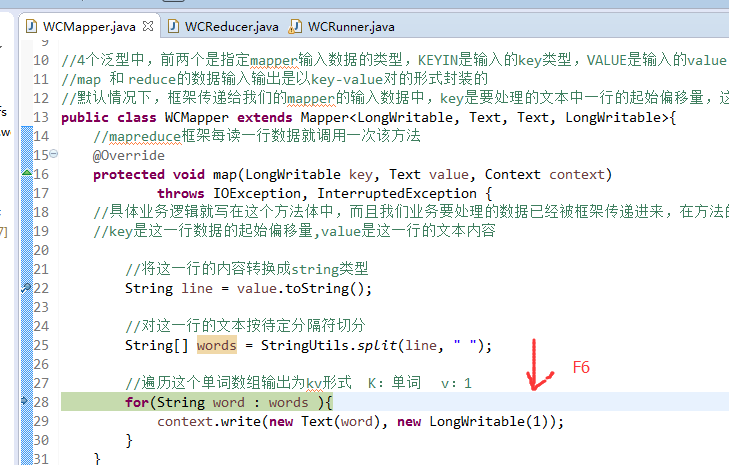
helllo 1
hello 4
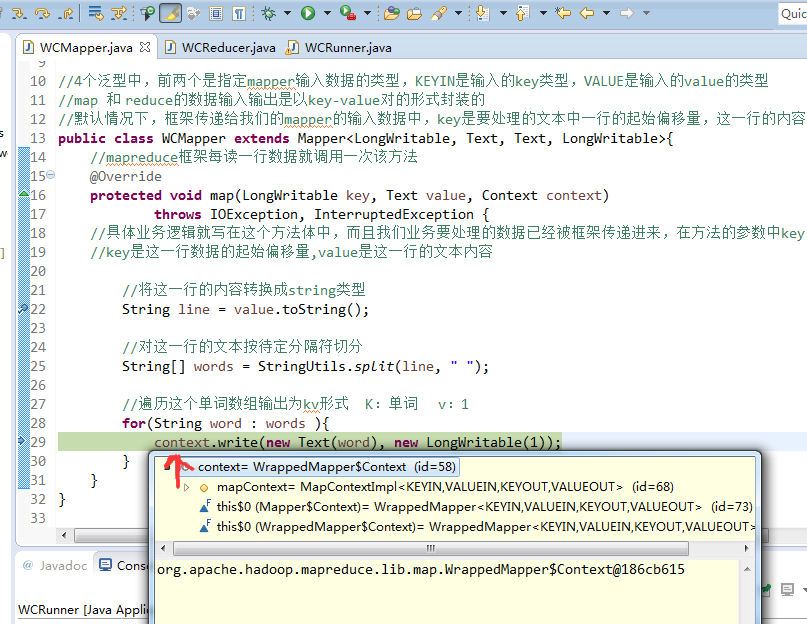
is 2
jack 1
jim 2
my 1
nvshen 1
tom 1
world
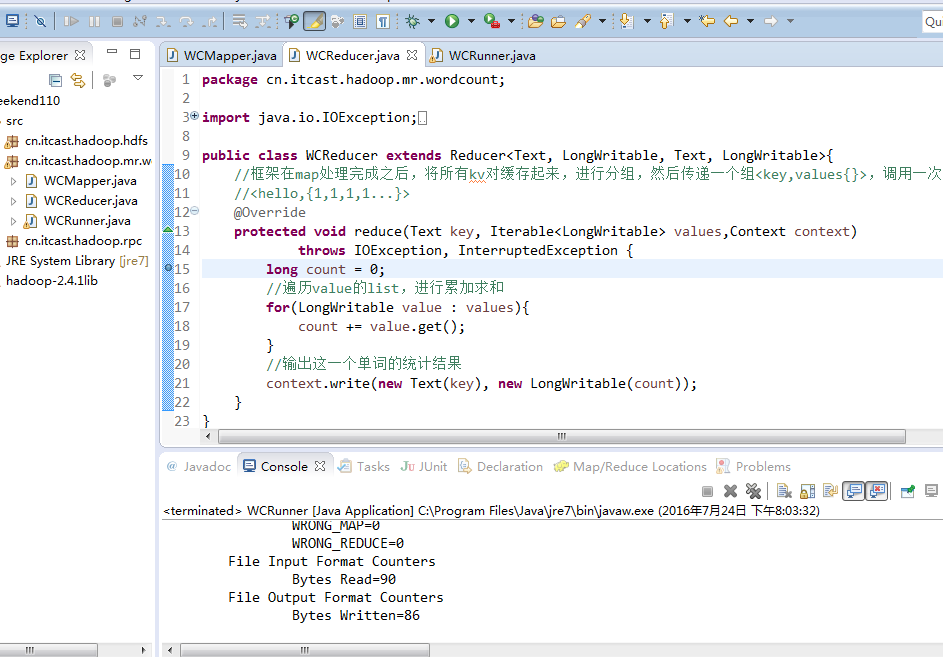
以上是weekend110的job提交的逻辑之源代码跟踪
接下来是yarn框架的技术机制,
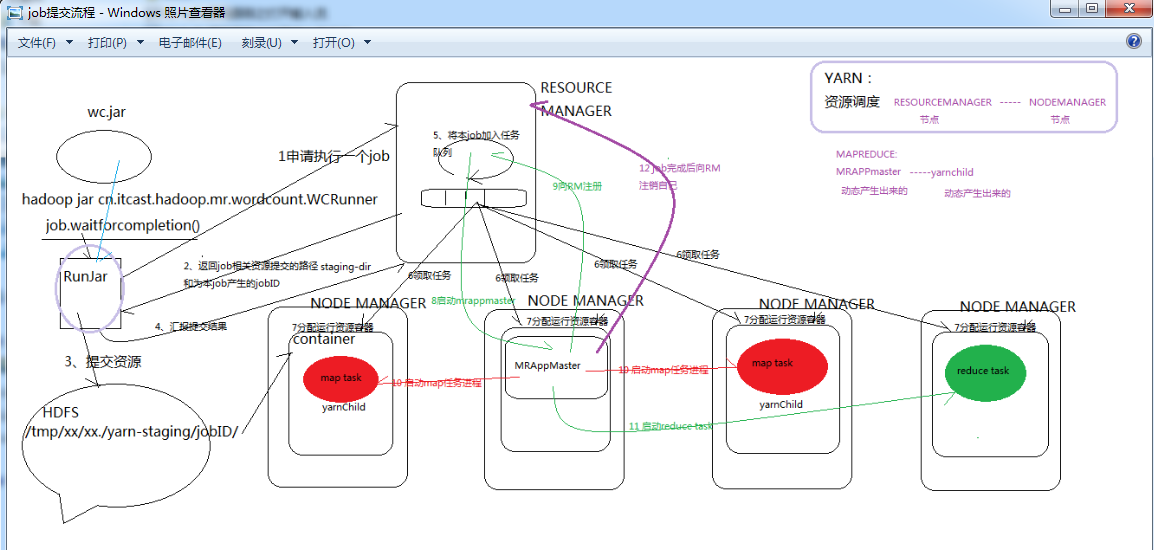
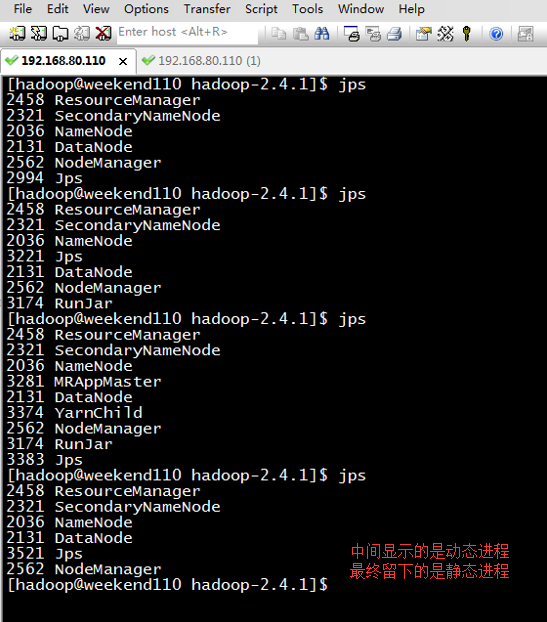
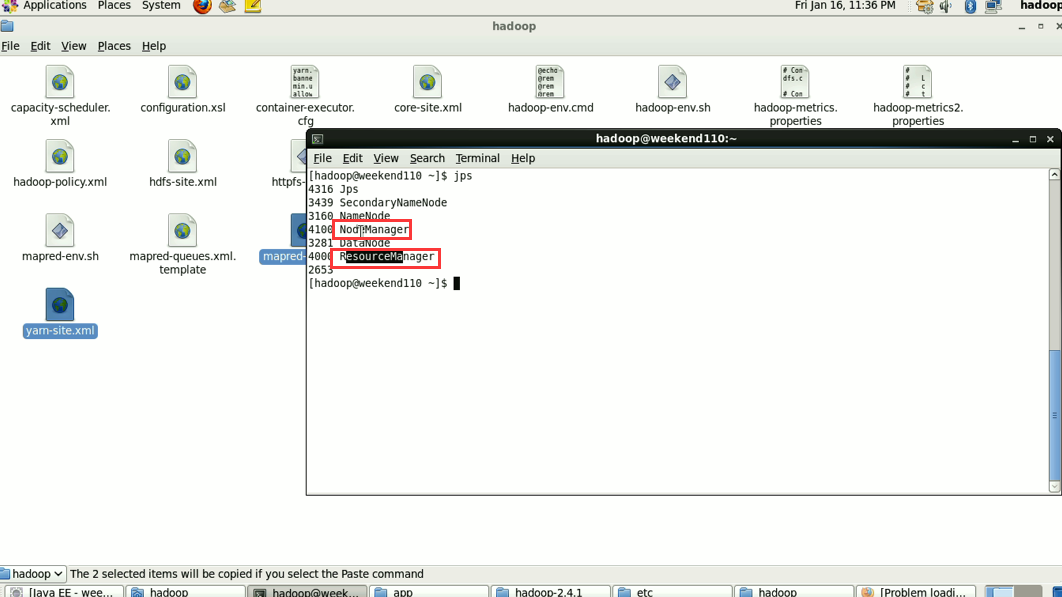
Resourcemanager和nodemanager进程一直在,
Yarnchild进程一会在,一会不在,


以上是weekend110的job提交的逻辑及YARN框架的技术机制
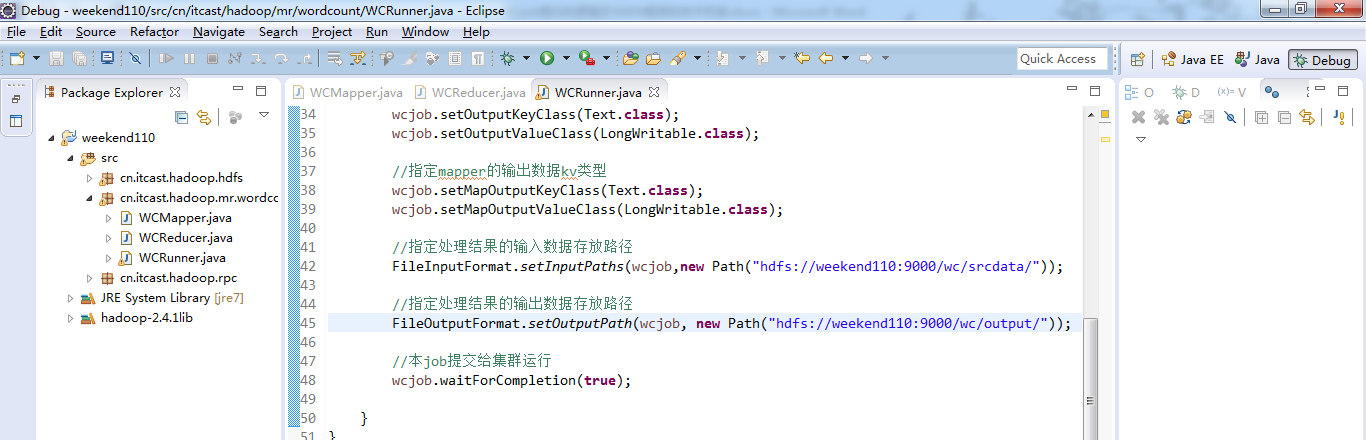
MR程序的几种提交运行模式
本地模型运行:
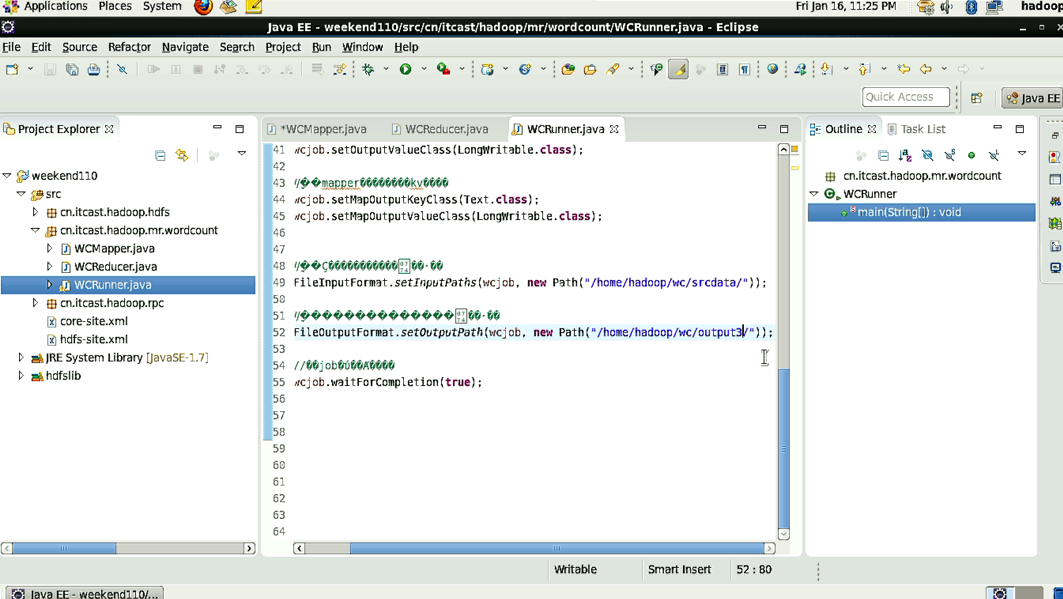
1/在windows的eclipse里面直接运行main方法,就会将job提交给本地执行器localjobrunner执行
----输入输出数据可以放在本地路径下(c:/wc/srcdata/)
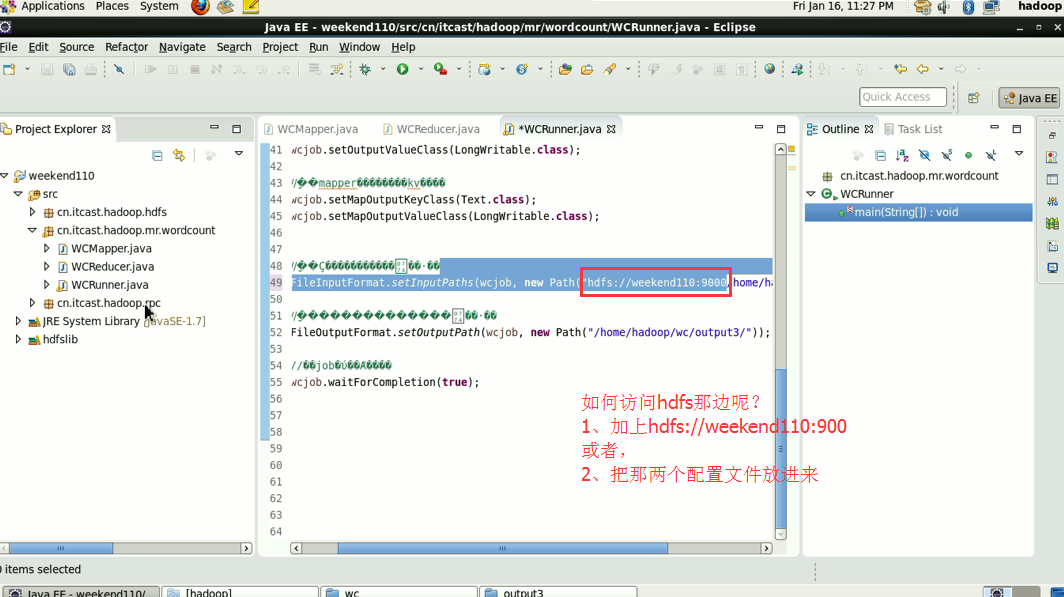
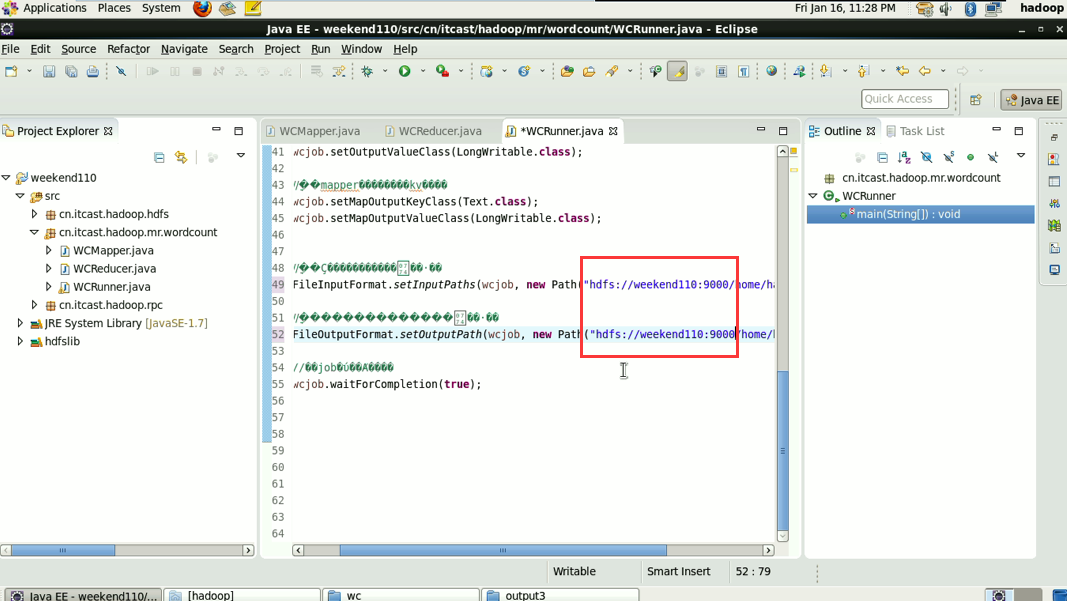
----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata)
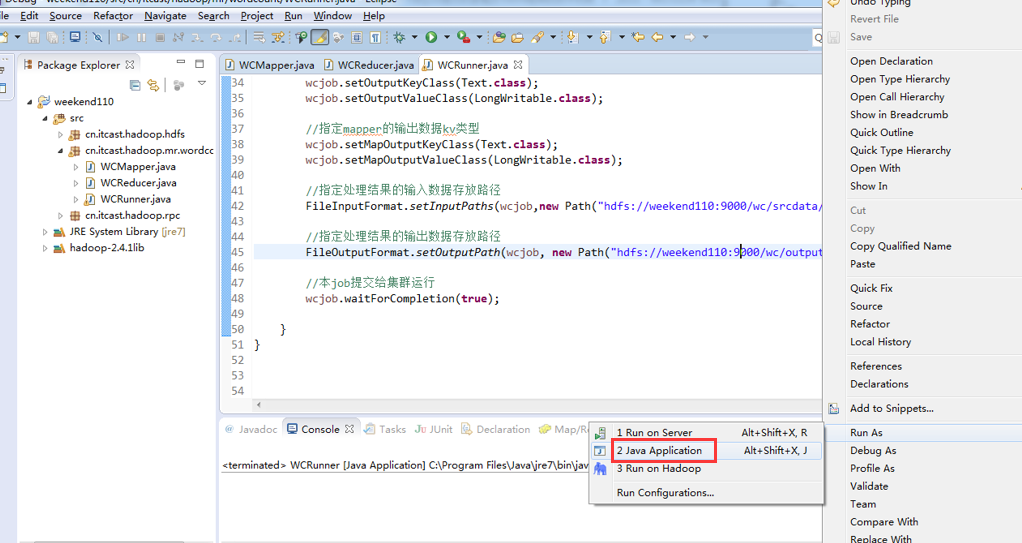
2/在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行
----输入输出数据可以放在本地路径下(/home/hadoop/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata)
集群模式运行:
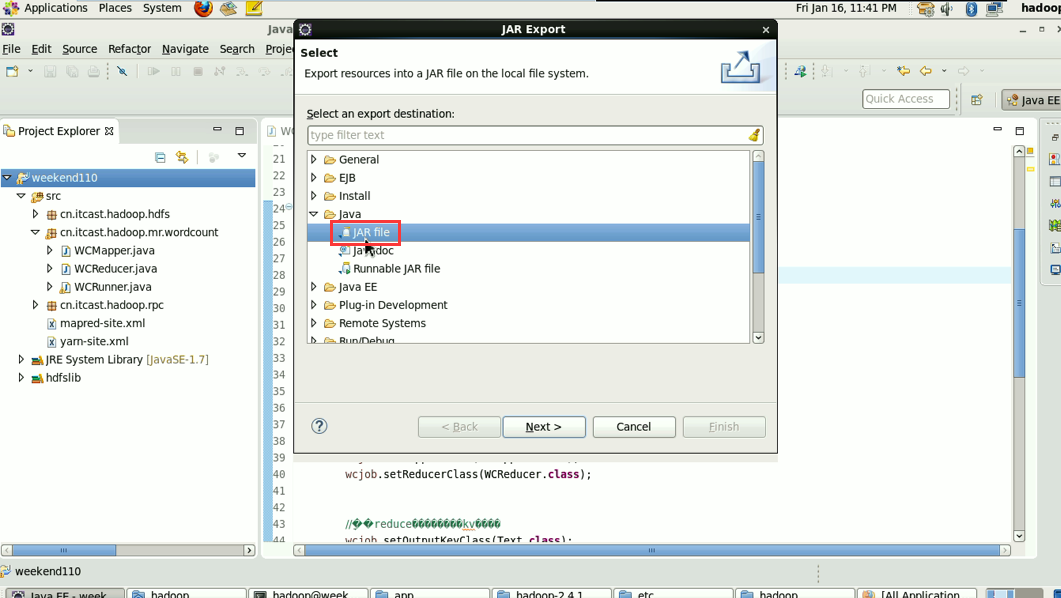
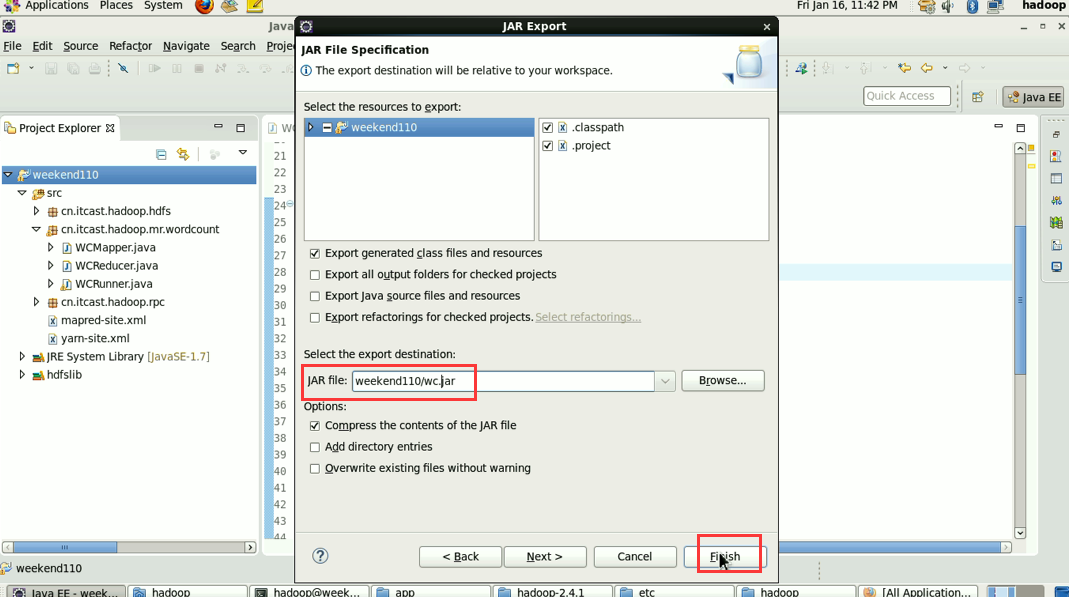
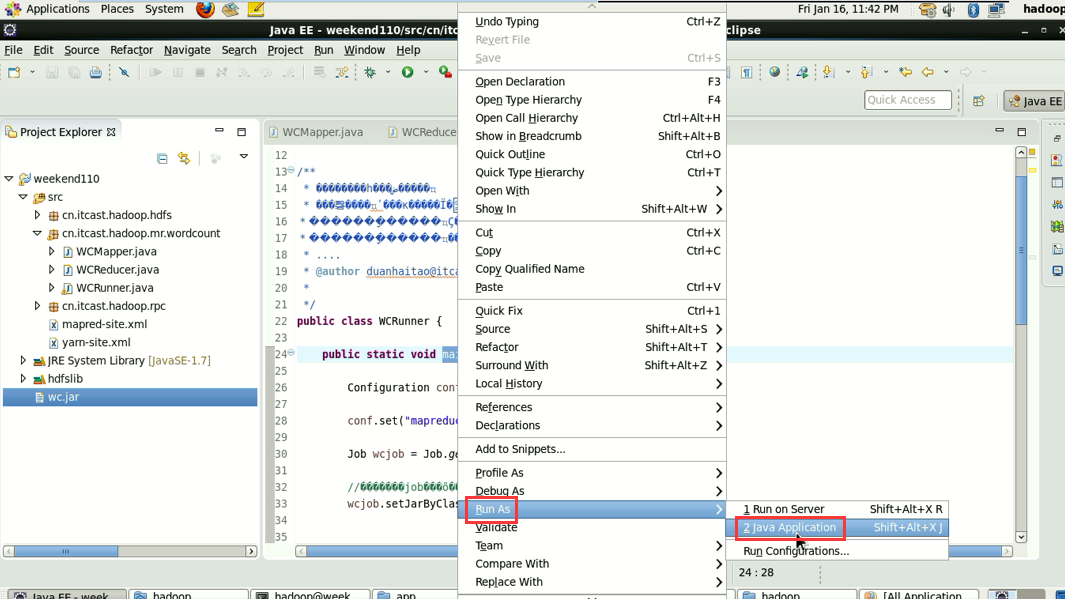
1/将工程打成jar包,上传到服务器,然后用hadoop命令提交 hadoop jar wc.jar cn.itcast.hadoop.mr.wordcount.WCRunner
2/在linux的eclipse中直接运行main方法,也可以提交到集群中去运行,但是,必须采取以下措施:
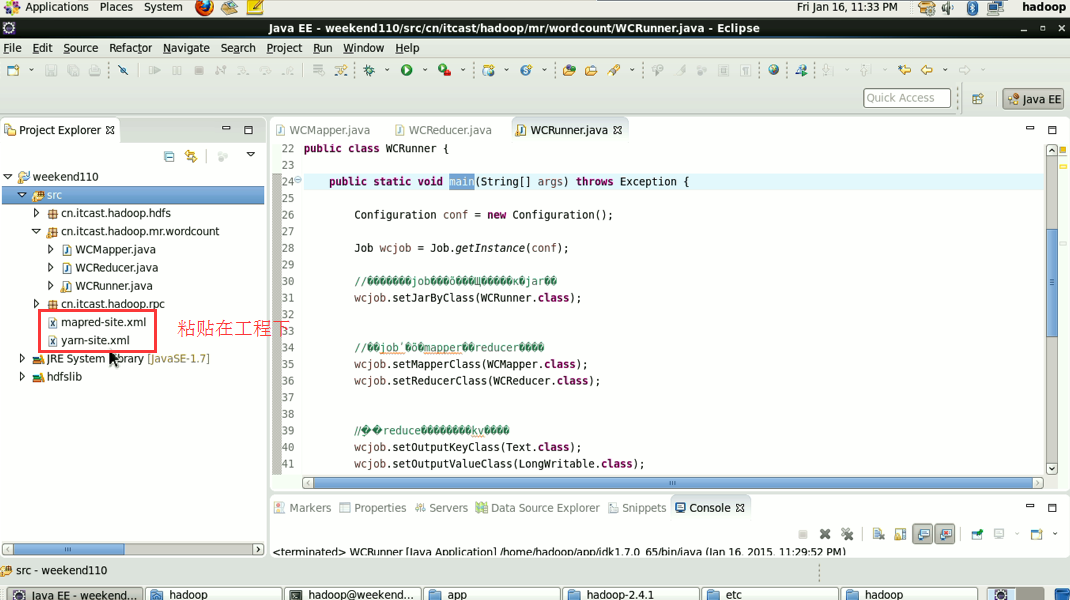
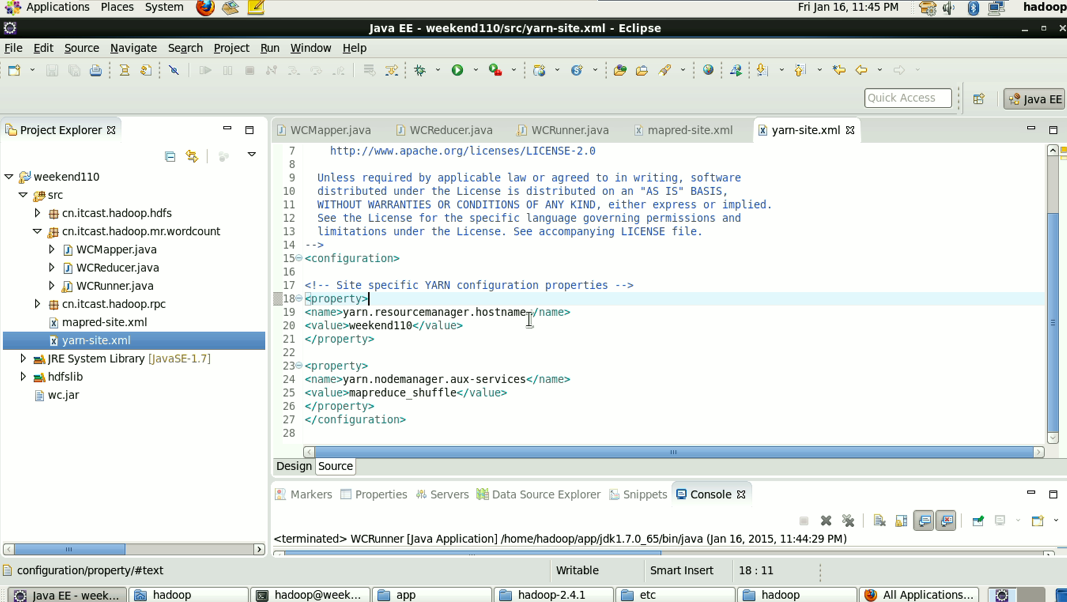
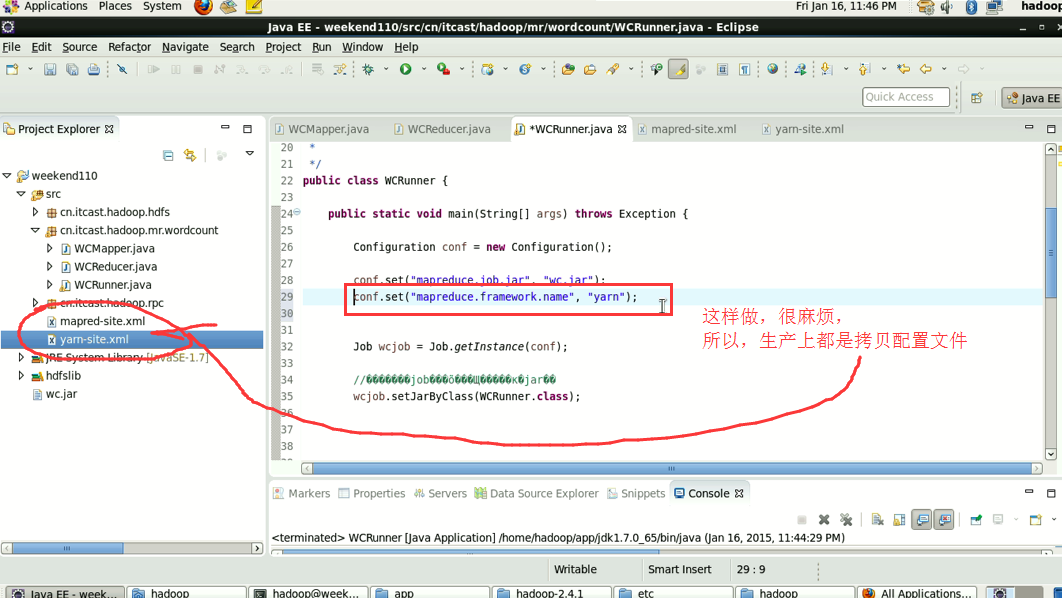
----在工程src目录下加入 mapred-site.xml 和 yarn-site.xml
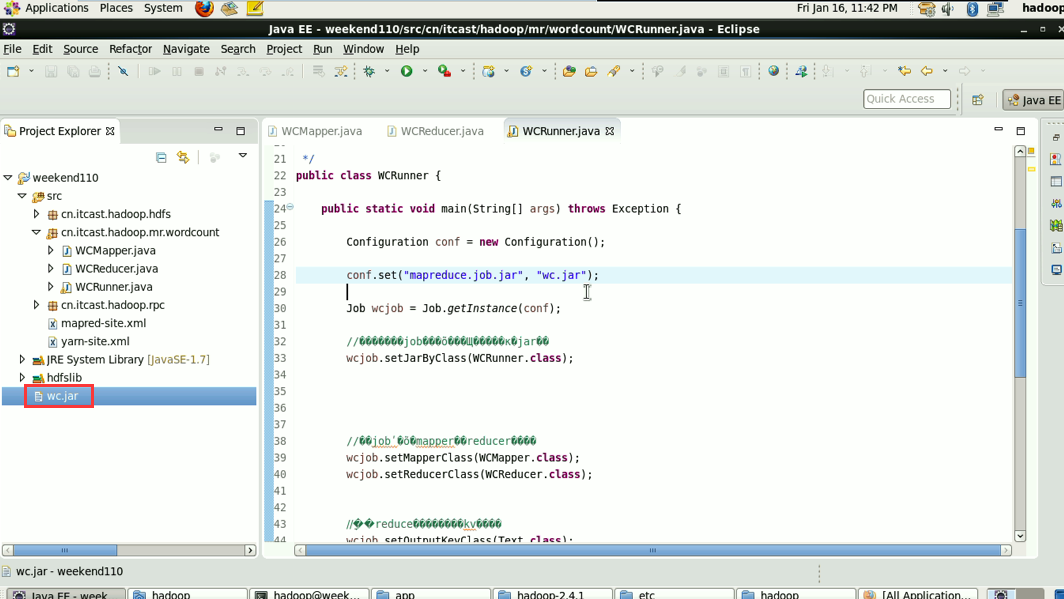
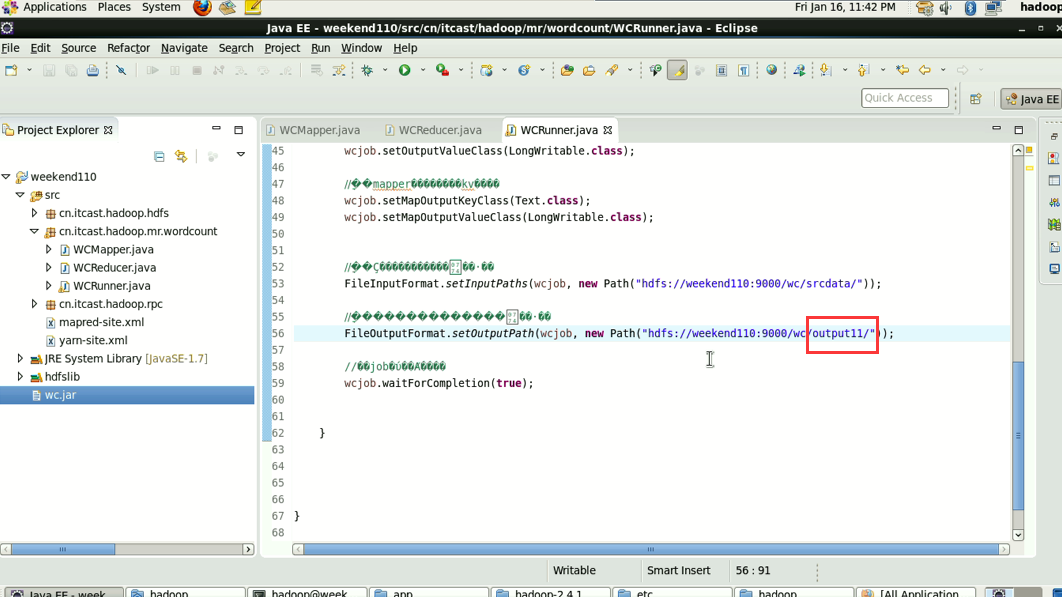
----将工程打成jar包(wc.jar),同时在main方法中添加一个conf的配置参数 conf.set("mapreduce.job.jar","wc.jar");
3/在windows的eclipse中直接运行main方法,也可以提交给集群中运行,但是因为平台不兼容,需要做很多的设置修改
----要在windows中存放一份hadoop的安装包(解压好的)
----要将其中的lib和bin目录替换成根据你的windows版本重新编译出的文件
----再要配置系统环境变量 HADOOP_HOME 和 PATH
----修改YarnRunner这个类的源码
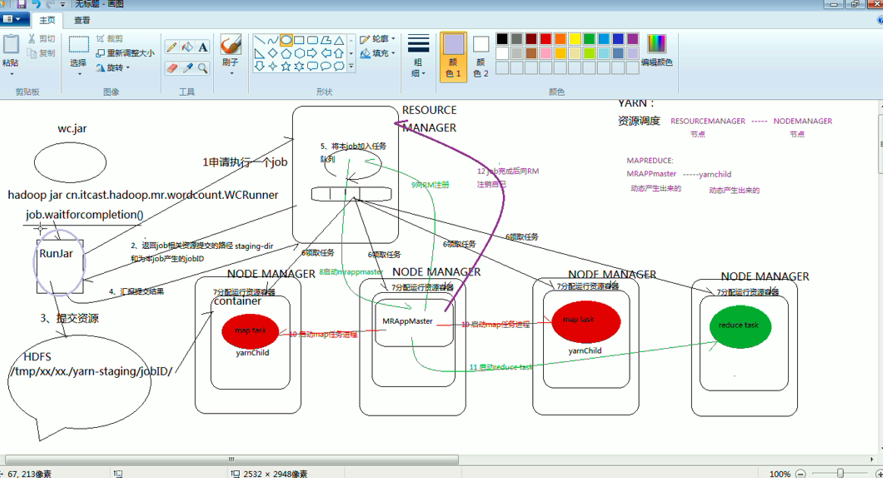
玄机是在Runjar,
Runjar客户端,它持有的是跟rm通信的那个客户端,它就会往那走
Runjar客户端,它持有的是跟本地模式通信的那个客户端,它就会提交到本地去了
那么,它在什么情况之下,持有rm客户端,什么情况下,持有本地客户端呢?
看源码最清楚
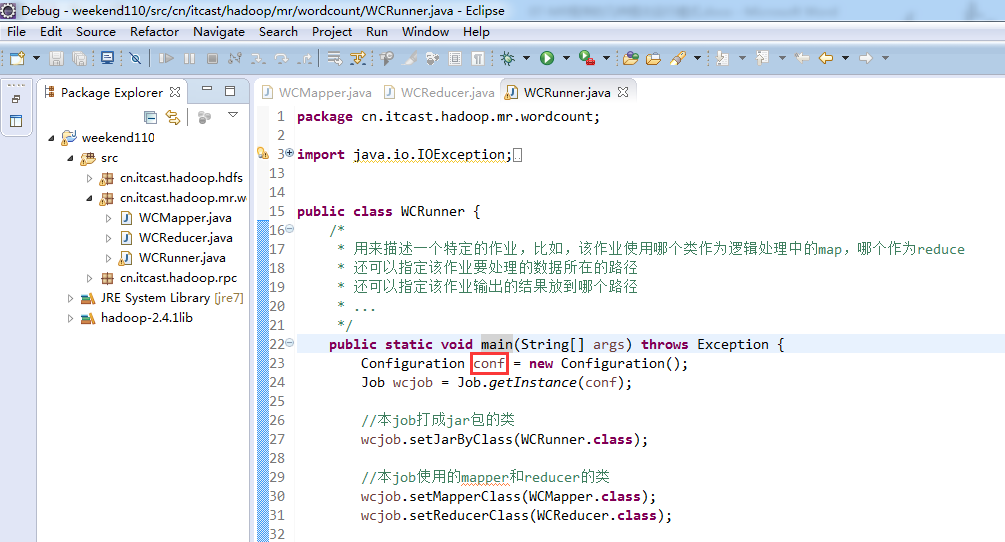
配置对象,没配任何信息,默认就会创建一个跟本地模式通信的Runjar,
MR程序的几种提交运行模式

演示:
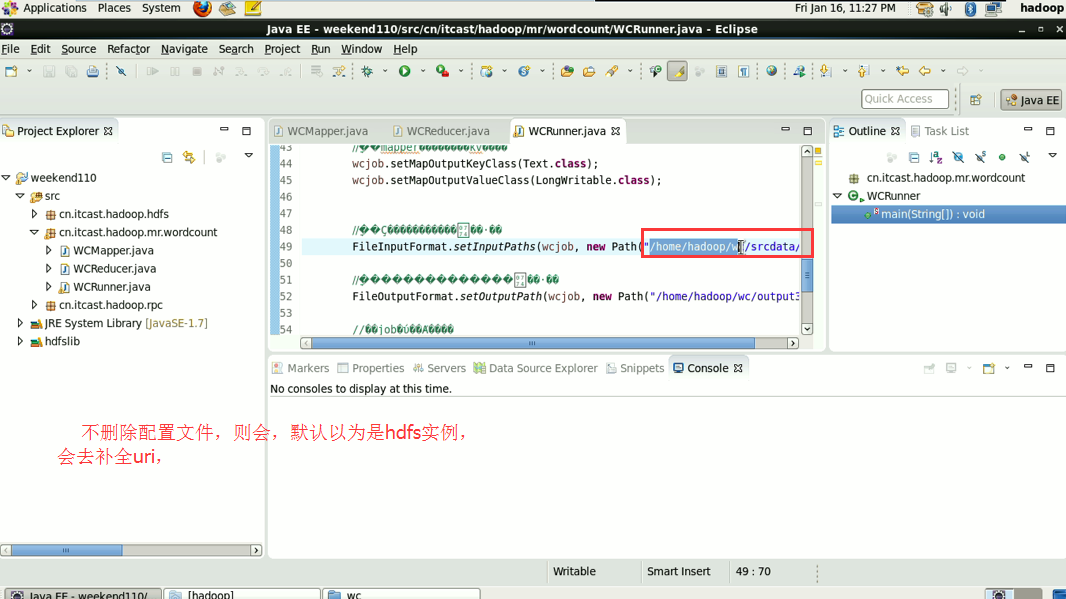
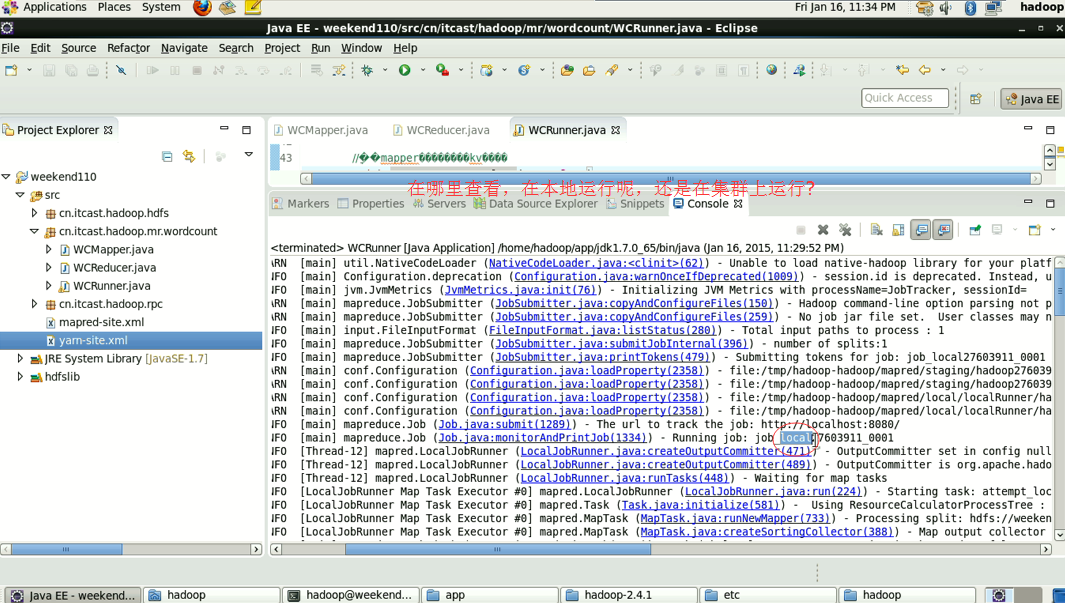
2/在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行
----输入输出数据可以放在本地路径下(/home/hadoop/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata)
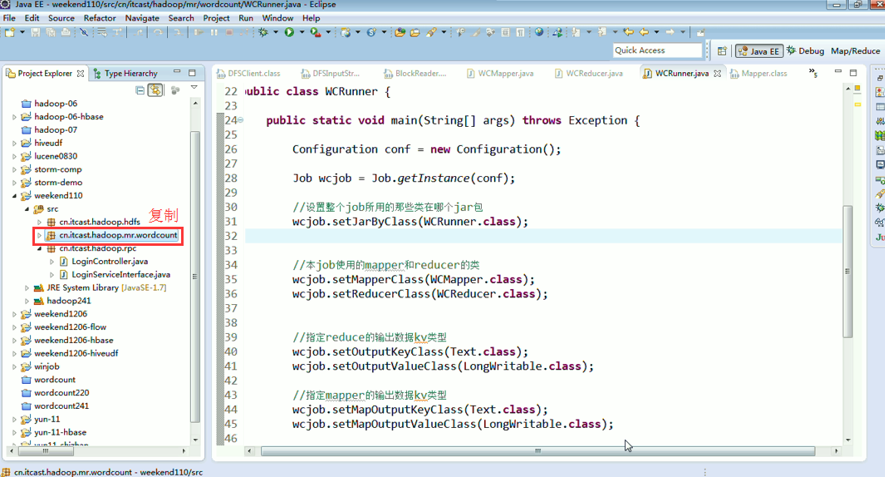




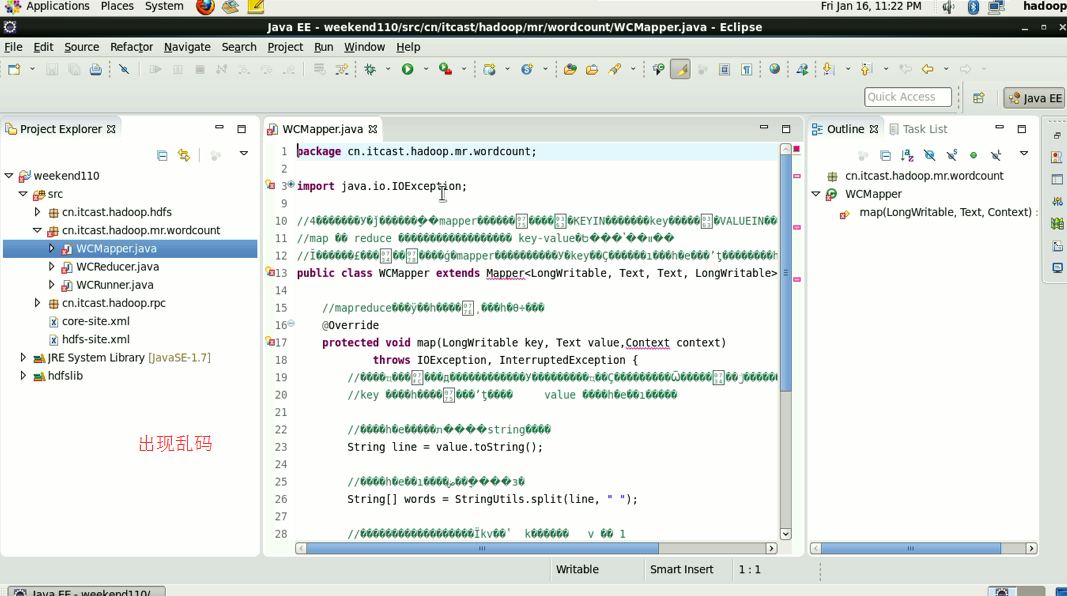
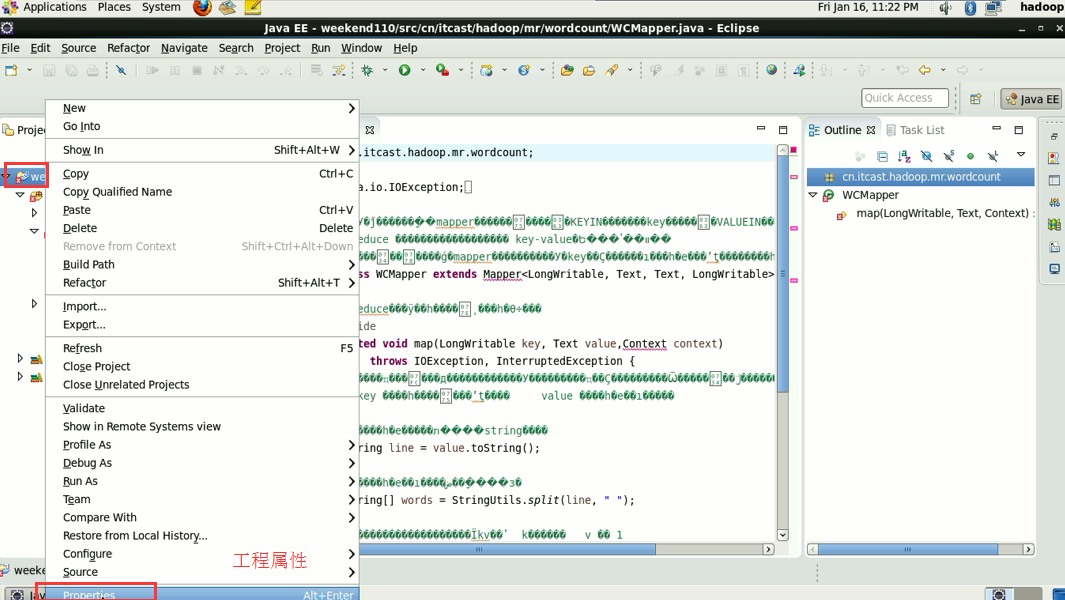
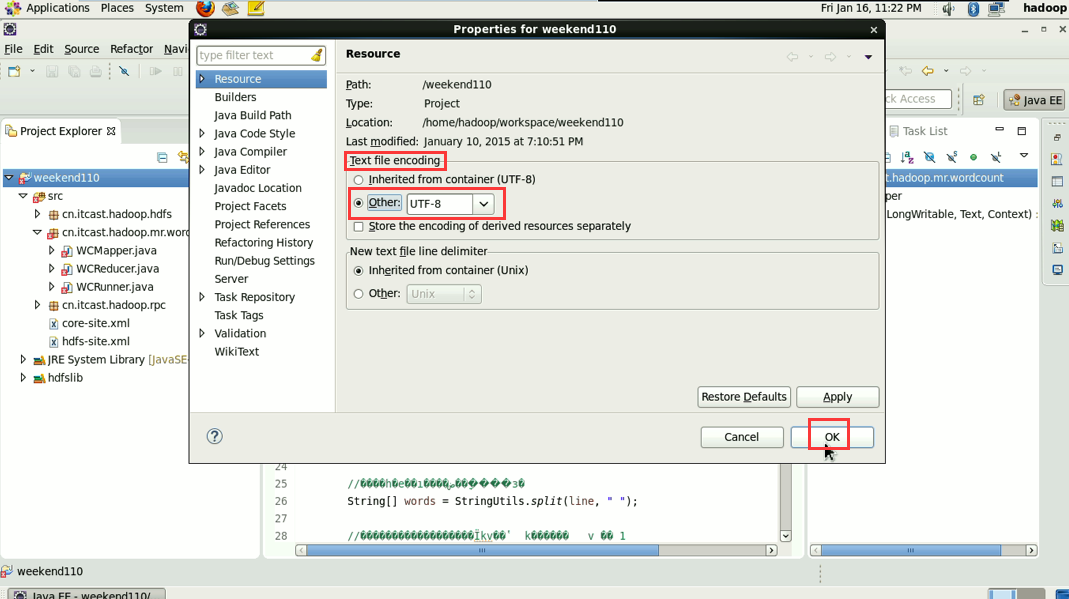
在这里,依然还是没解决,windows是用的是jpk,这里用的是utf-8,告诫我们,平常要习惯用utf-8

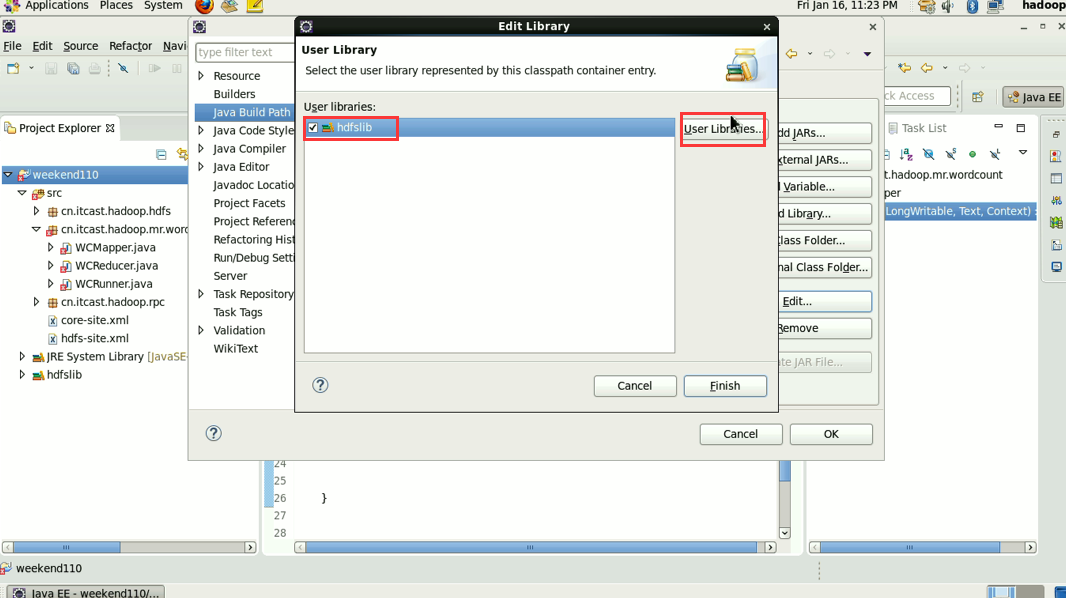
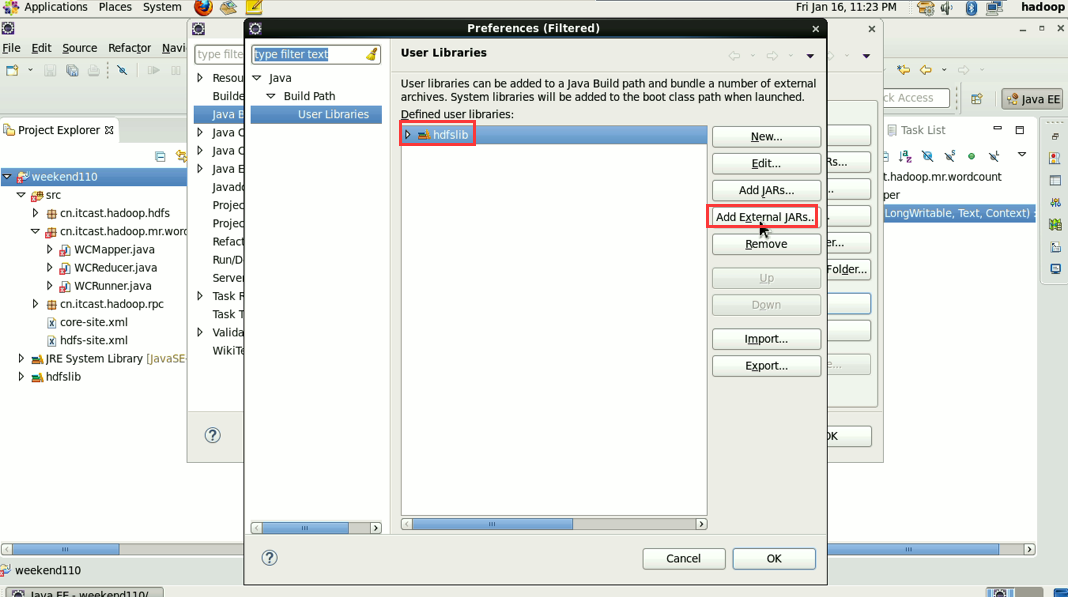
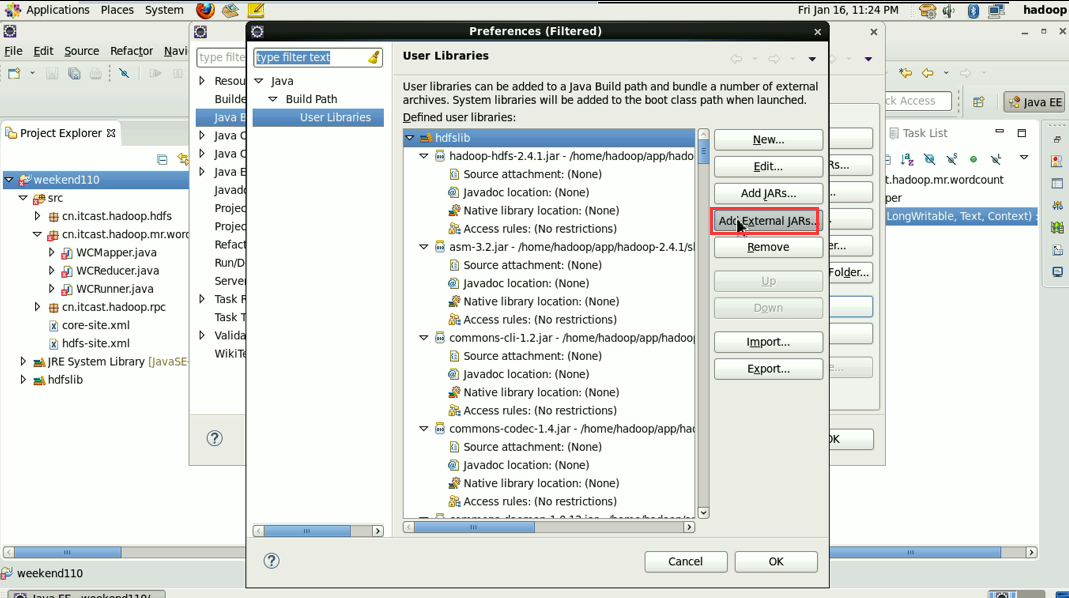
1 Common的jar包和 2 hdfs的jar包,已经加过了,
还需,3 mapreduce的jar包 4 mapreduce下lib下的jar 和5 yarn的jar包和6 yarn下lib的jar包。
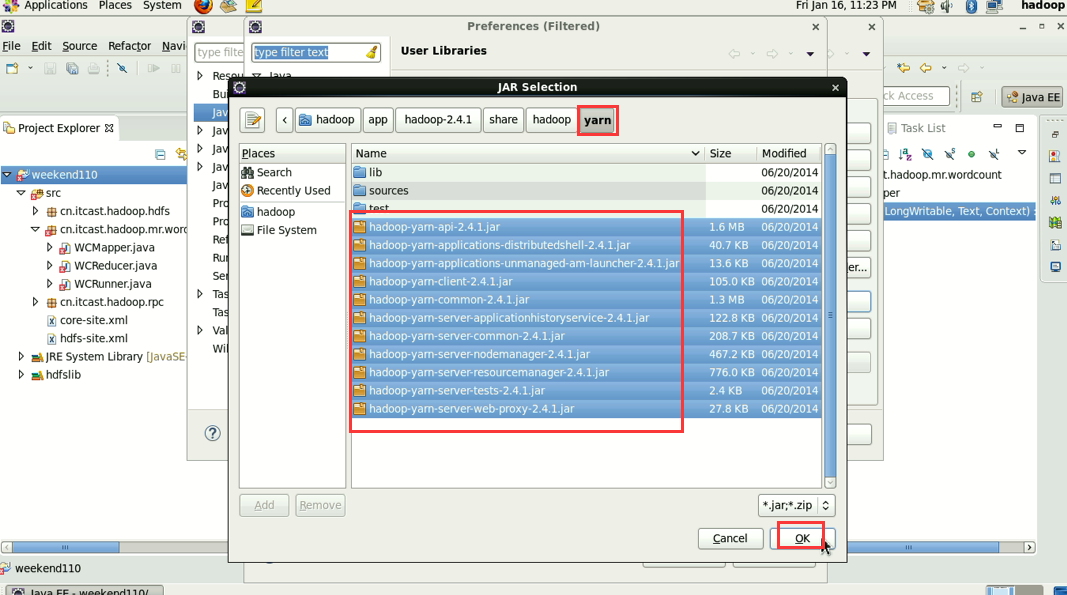

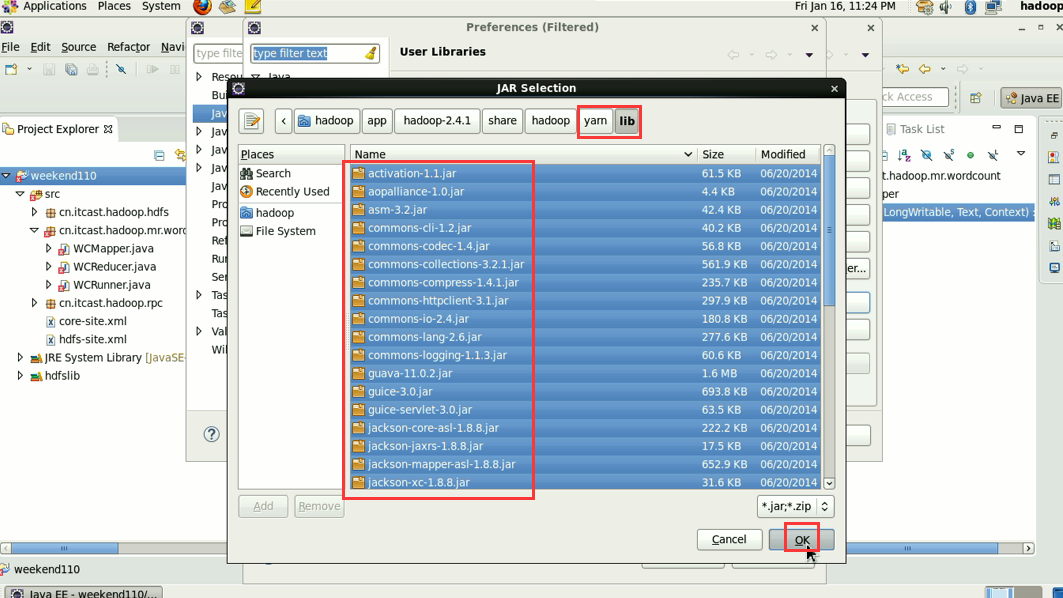
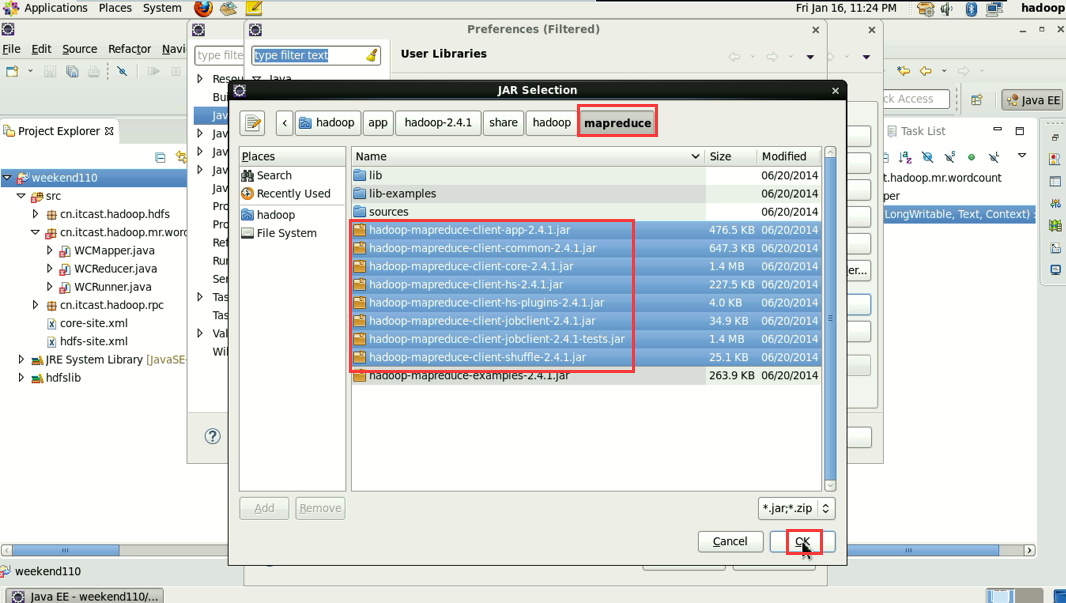
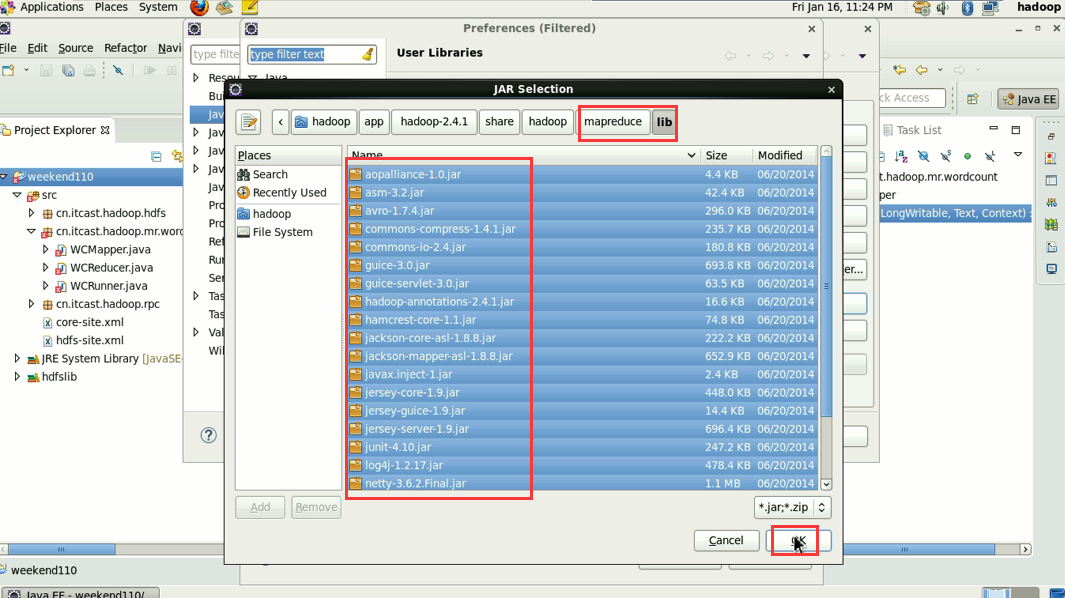




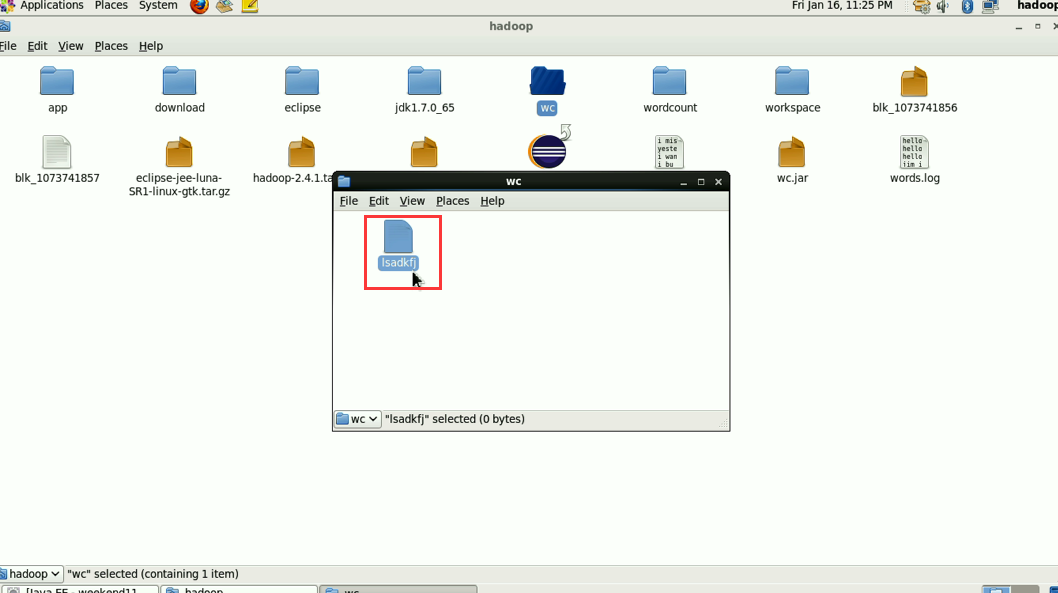

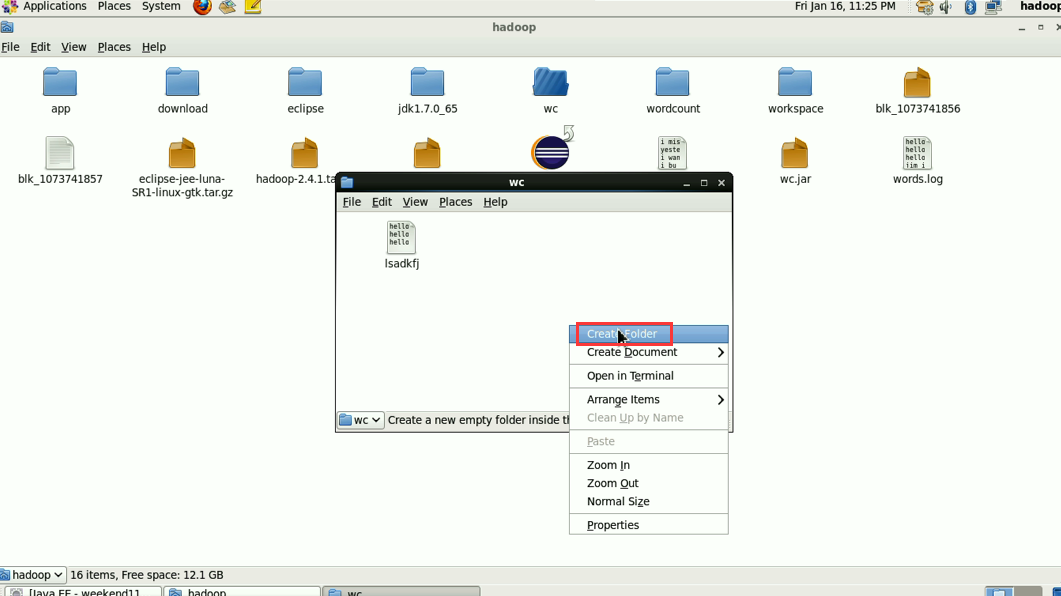
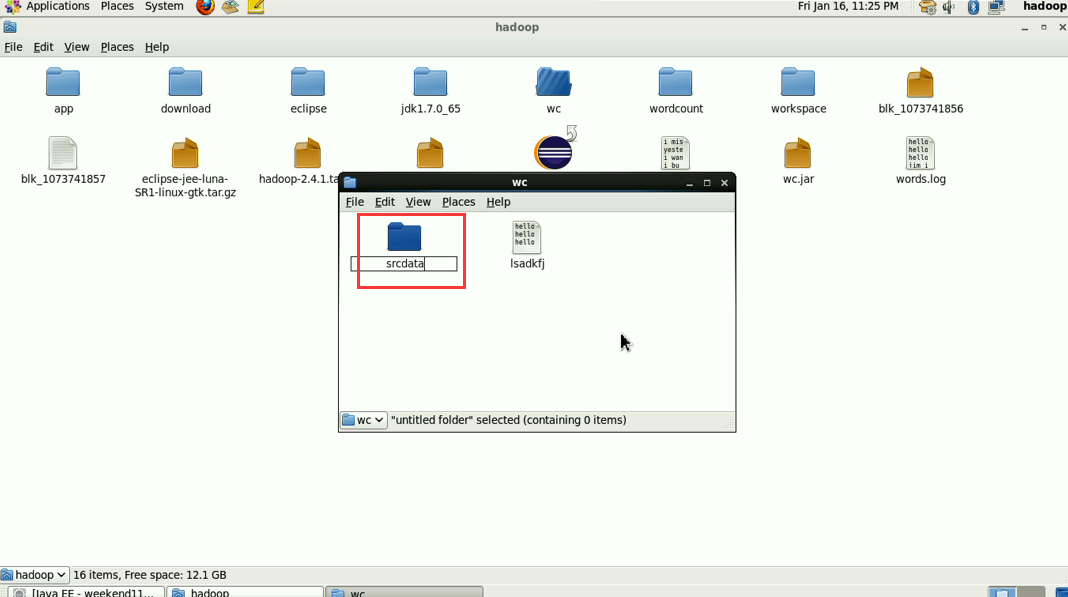
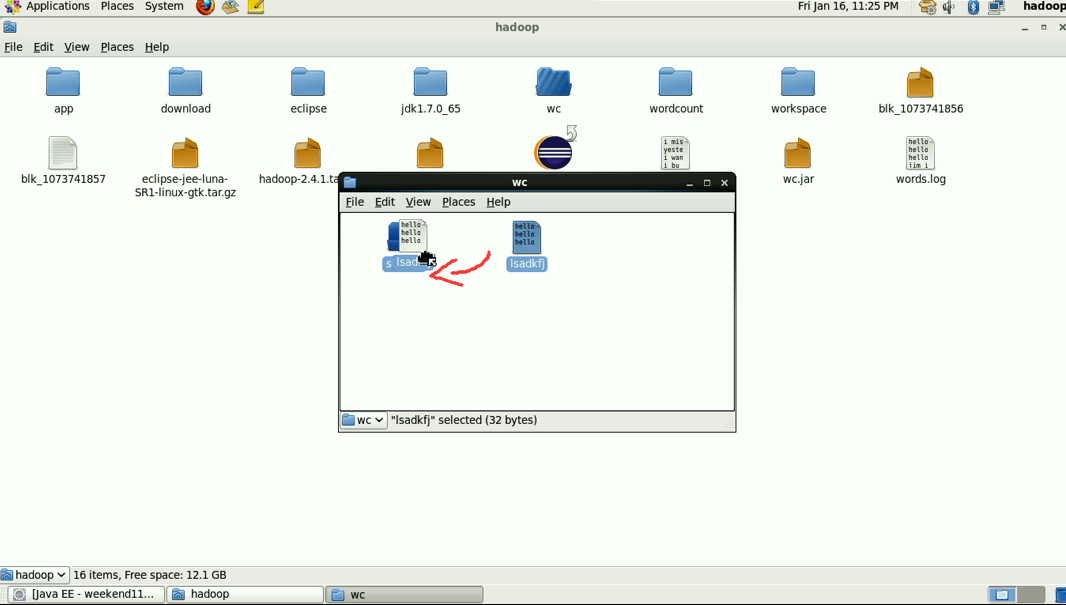
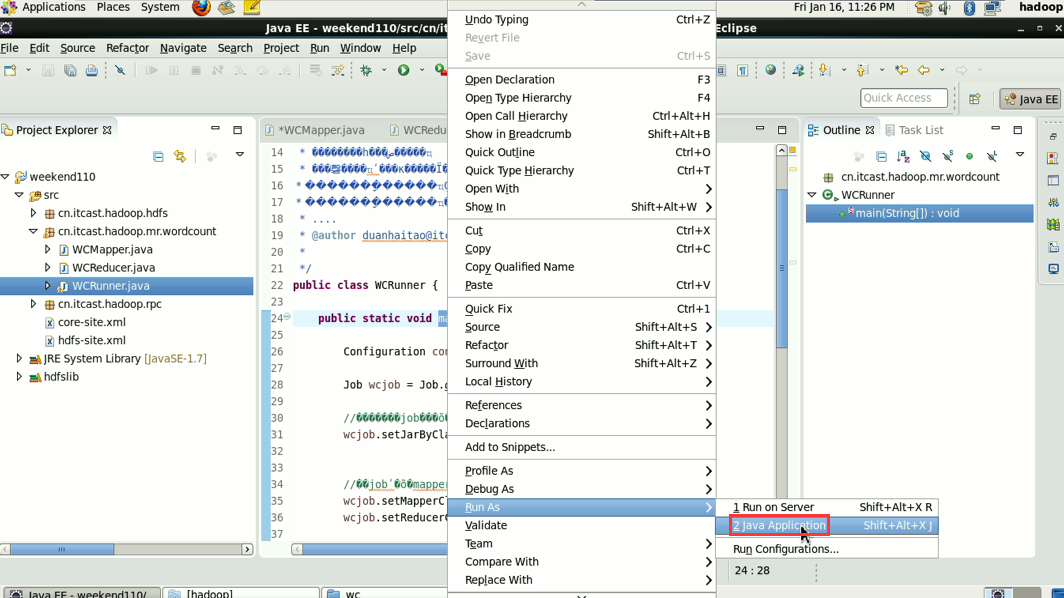
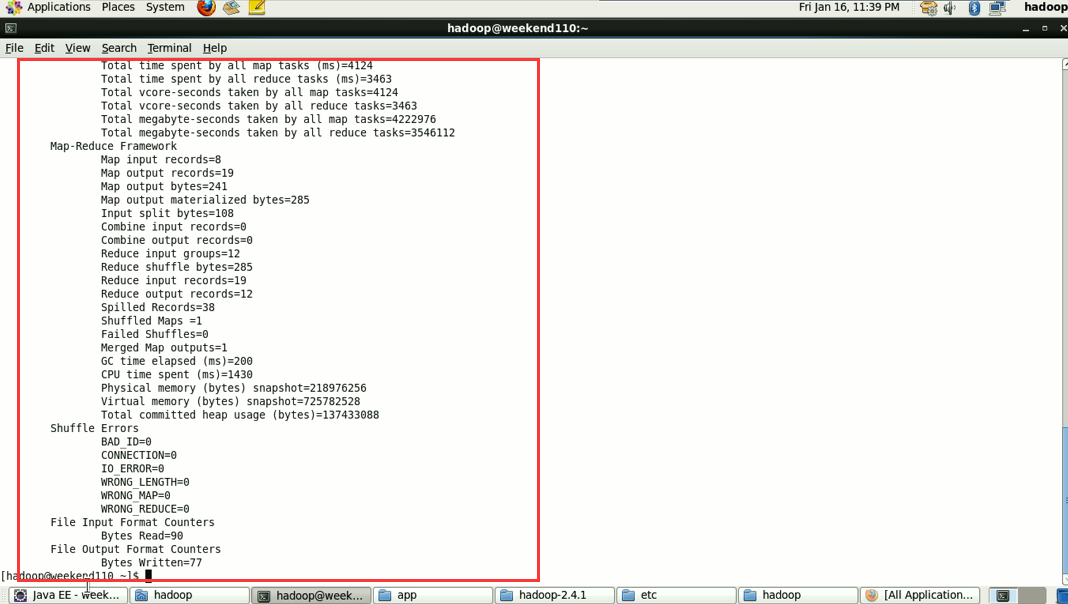
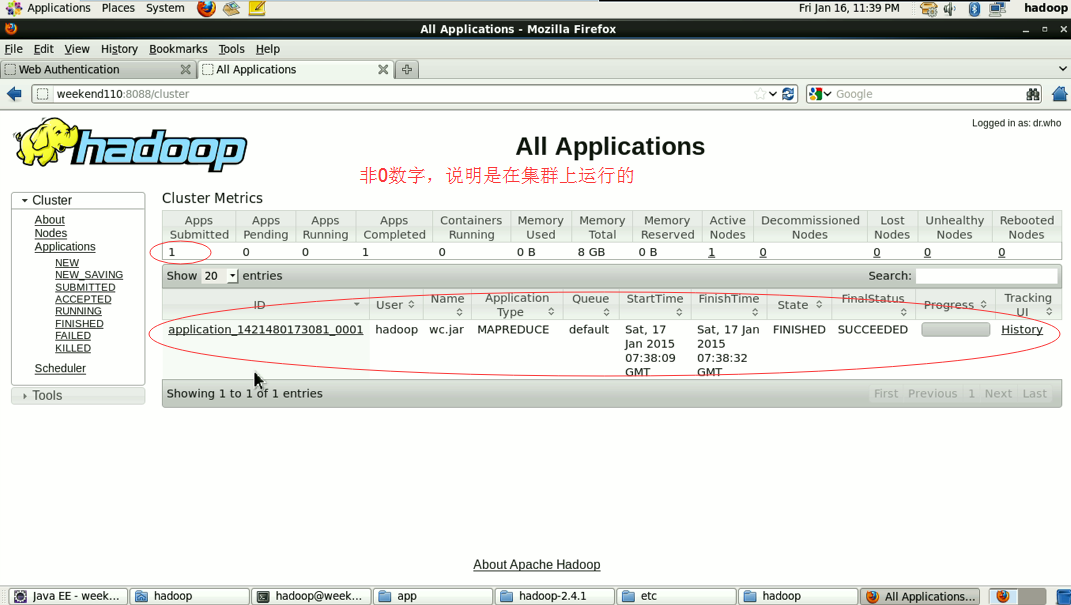
hadoop没启,这只是在linux里的jvm运行。
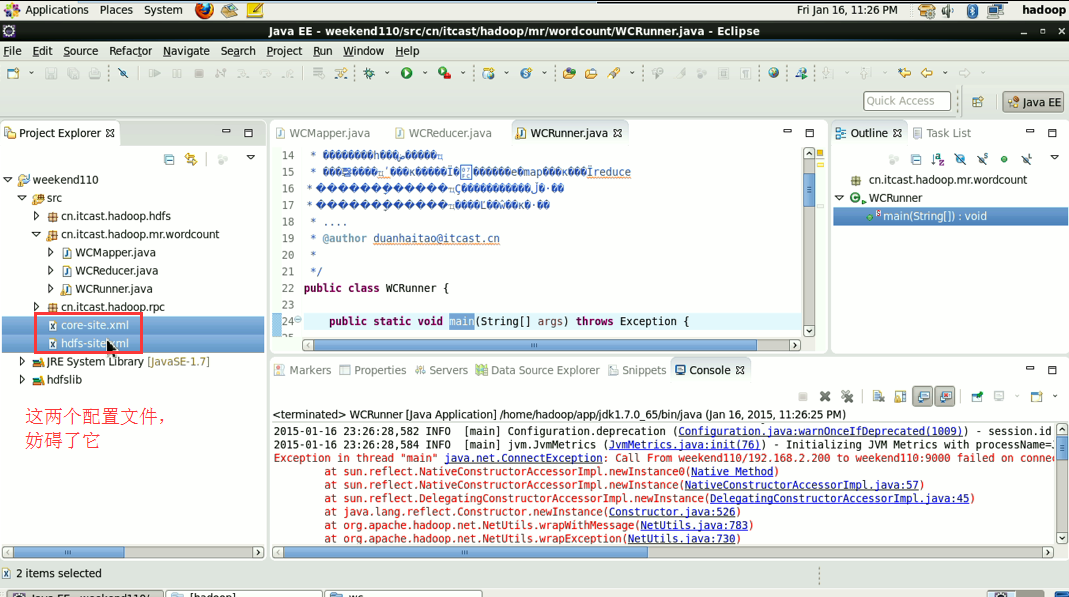
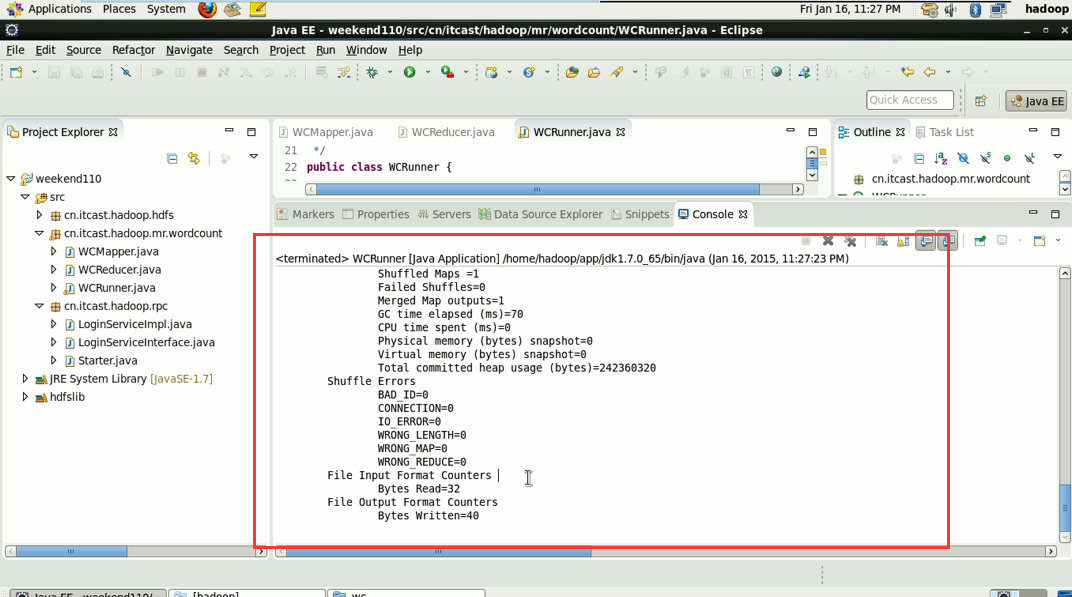
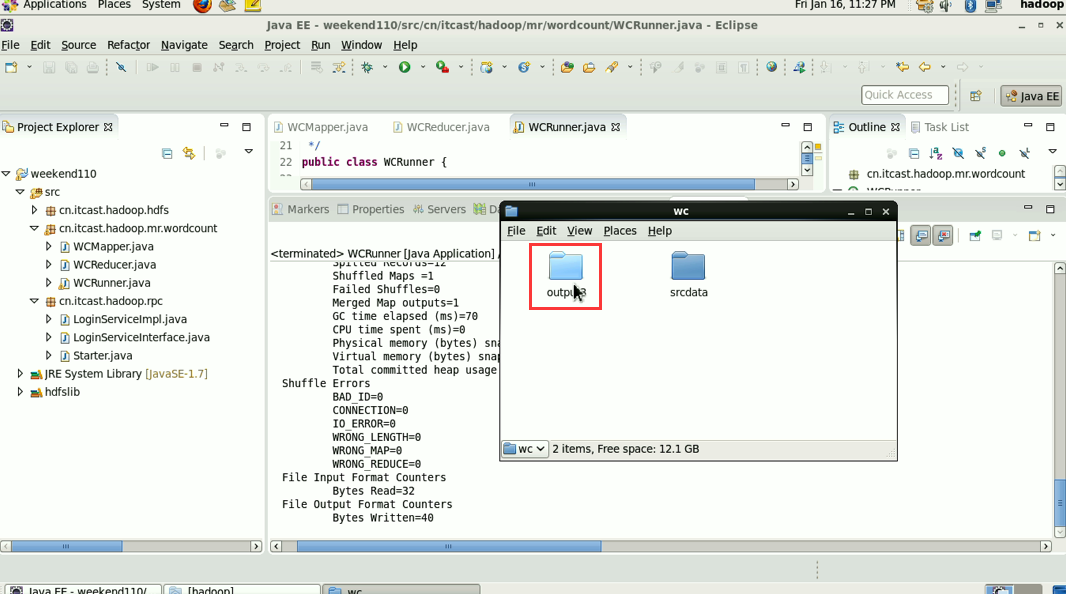
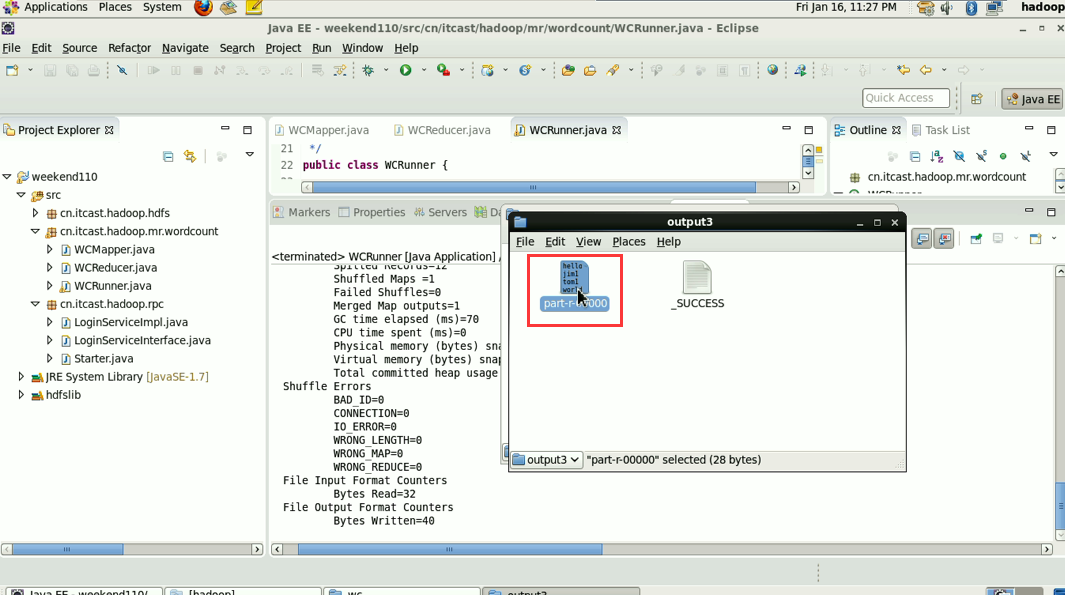
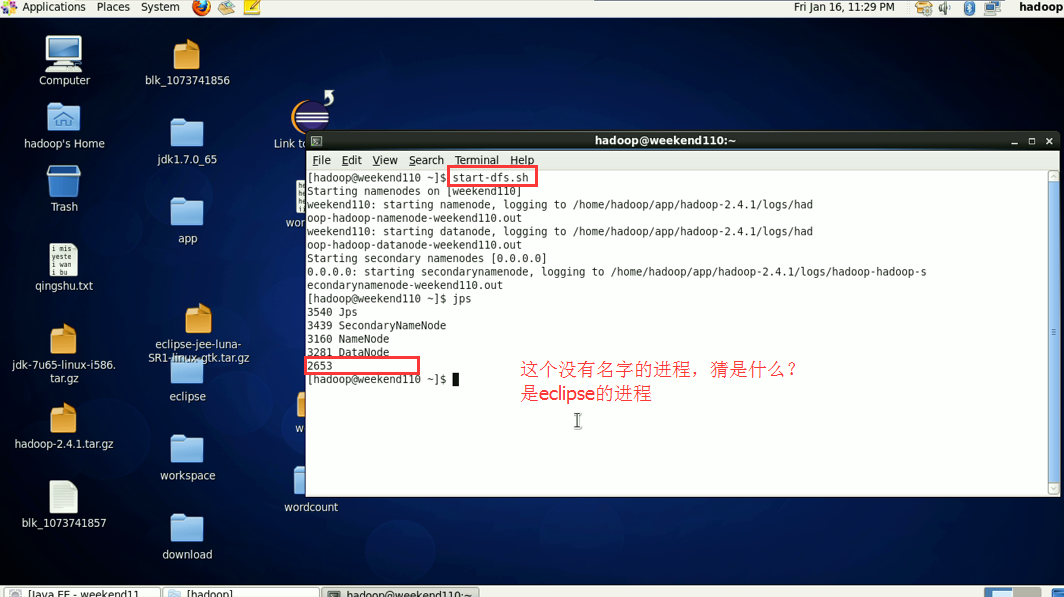

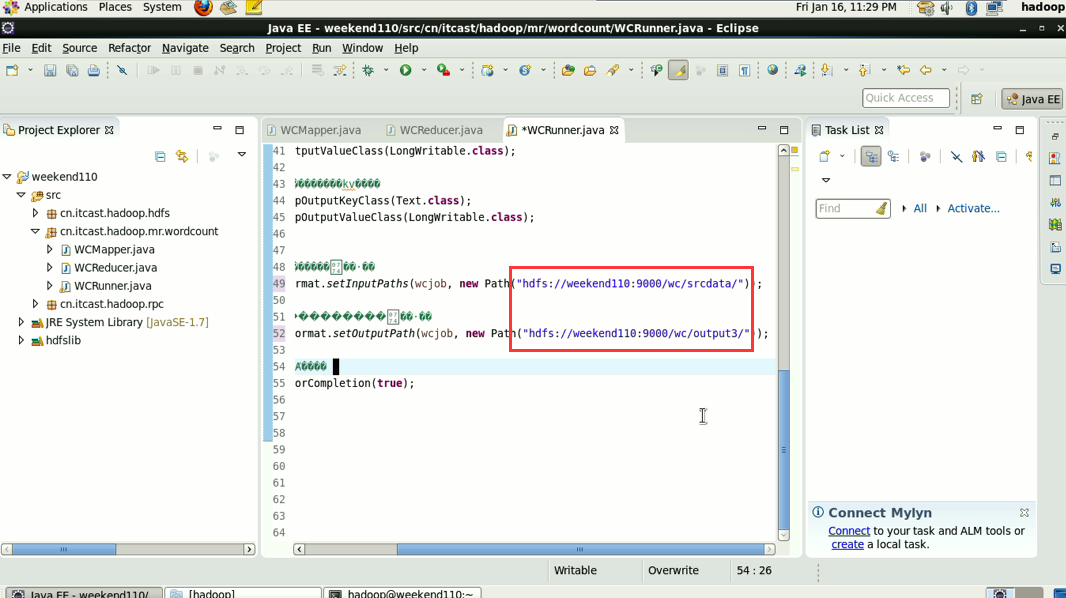
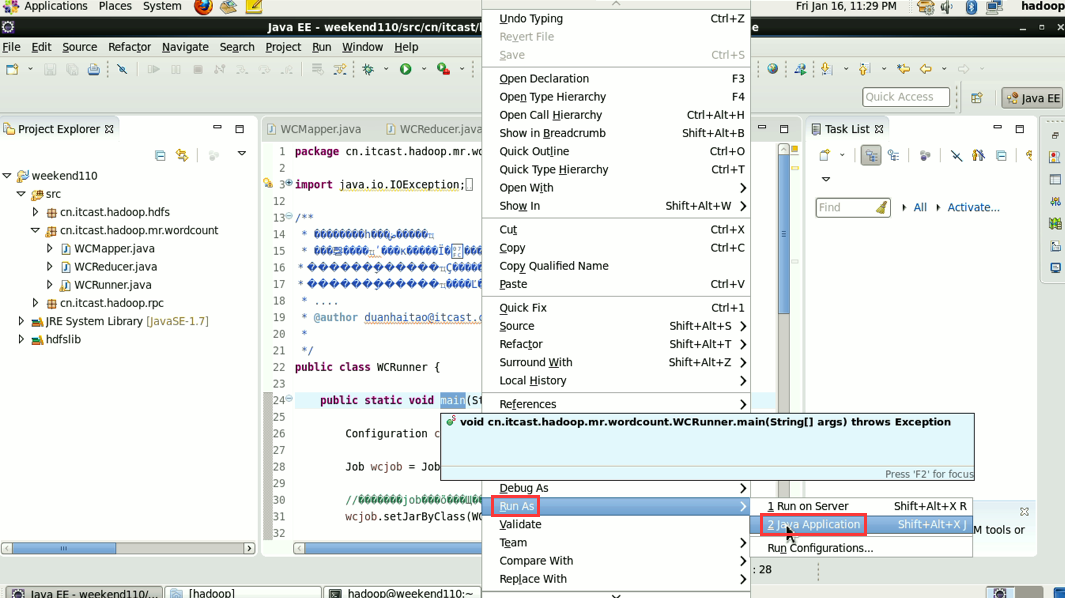
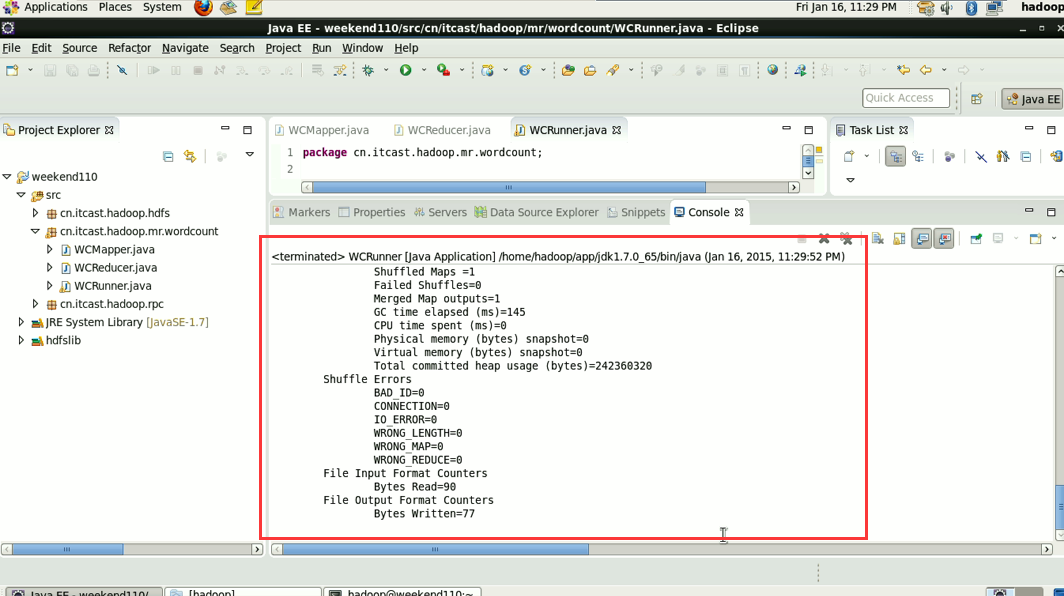

这说明,跑的mr的确是在本地,

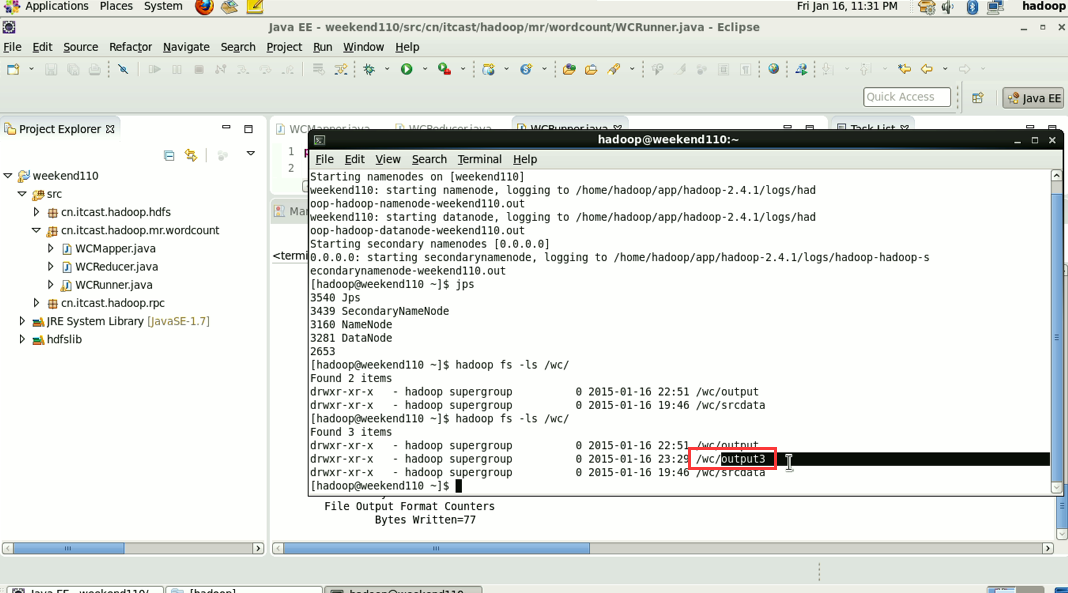





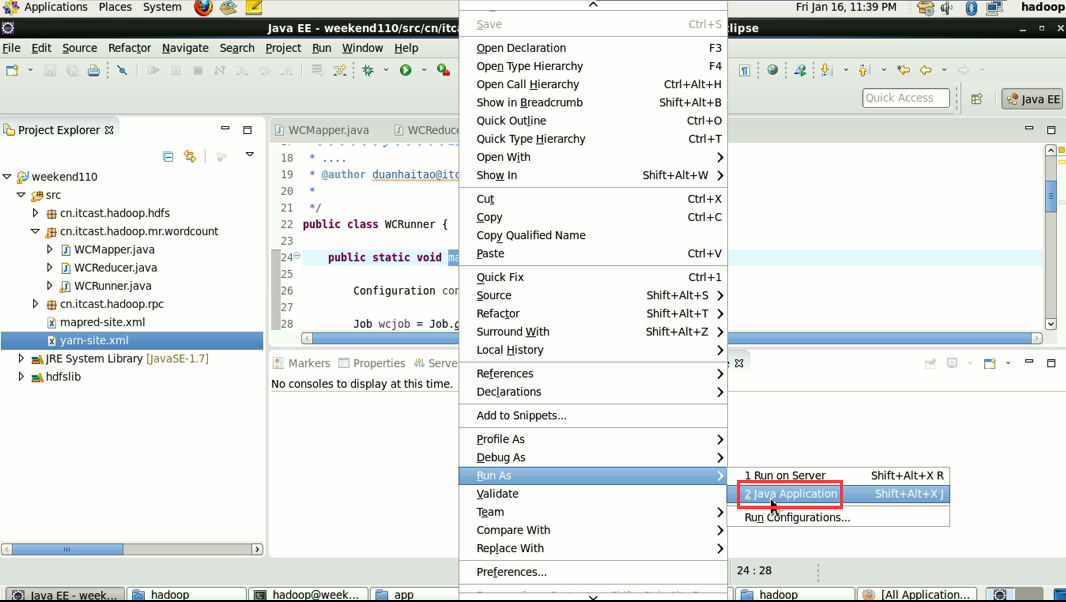
情况四:



总结,eclipse开发,若在windows下,需要插件,一般牛人会ant编译出一个插件,挂到csdn上,卖积分。也许,这位牛人弄出来的插件在他电脑上是可以,但到别人电脑上又不可以了。所以,一般能在linux里的eclipse下开发最好不过了。这样可避免插件浪费很多时间。
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号