

python版mapreduce题目实现寻找共同好友
看到一篇不知道是好好玩还是好玩玩童鞋的博客,发现一道好玩的mapreduce题目,地址http://www.cnblogs.com/songhaowan/p/7239578.html
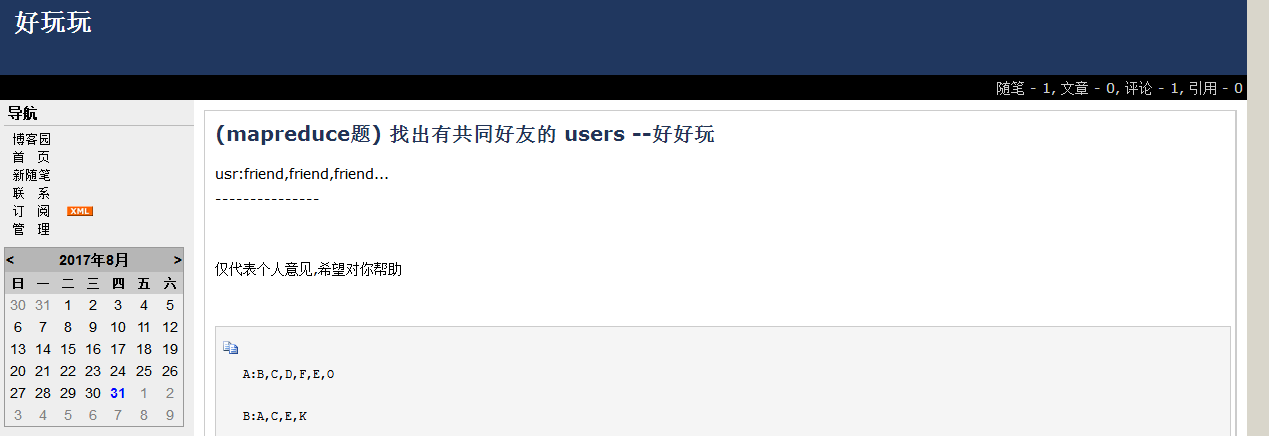
如图
由于自己太笨,看到一大堆java代码就头晕、心慌,所以用python把这个题目研究了一下。
题目:寻找共同好友。比如A的好友中有C,B的好友中有C,那么C就是AB的共同好友。
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
m.py
#-*-encoding:utf-8-*- #!/home/hadoop/anaconda2/bin/python import sys result = {} for line in sys.stdin: line = line.strip() if len(line)==0: continue key,vals = line.split(':') val = vals.split(',') result[key] = val if len(result)==1: continue else: for i in result[key]: for j in result: if i in result[j]: if j<key: print j+key,i elif j>key: print key+j,i
r.py
#-*-encoding:utf-8-*- import sys result = {} for line in sys.stdin: line = line.strip() k,v = line.split(' ') if k in result: result[k].append(v) else: result[k] = [v] for key,val in result.items(): print key,val
执行的命令
hadoop jar /home/hadoop/hadoop-2.7.2/hadoop-streaming-2.7.2.jar \ -files /home/hadoop/test/m.py,/home/hadoop/test/r.py \ -input GTHY -output GTHYout \ -mapper 'python m.py' -reducer 'python r.py'
执行情况
packageJobJar: [/tmp/hadoop-unjar2310332345933071298/] [] /tmp/streamjob8006362102585628853.jar tmpDir=null 17/08/31 14:47:59 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.228.200:18040 17/08/31 14:48:00 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.228.200:18040 17/08/31 14:48:00 INFO mapred.FileInputFormat: Total input paths to process : 1 17/08/31 14:48:00 INFO mapreduce.JobSubmitter: number of splits:2 17/08/31 14:48:01 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1504148710826_0003 17/08/31 14:48:01 INFO impl.YarnClientImpl: Submitted application application_1504148710826_0003 17/08/31 14:48:01 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1504148710826_0003/ 17/08/31 14:48:01 INFO mapreduce.Job: Running job: job_1504148710826_0003 17/08/31 14:48:08 INFO mapreduce.Job: Job job_1504148710826_0003 running in uber mode : false 17/08/31 14:48:08 INFO mapreduce.Job: map 0% reduce 0% 17/08/31 14:48:16 INFO mapreduce.Job: map 100% reduce 0% 17/08/31 14:48:21 INFO mapreduce.Job: map 100% reduce 100% 17/08/31 14:48:21 INFO mapreduce.Job: Job job_1504148710826_0003 completed successfully 17/08/31 14:48:21 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=558 FILE: Number of bytes written=362357 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=462 HDFS: Number of bytes written=510 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=11376 Total time spent by all reduces in occupied slots (ms)=2888 Total time spent by all map tasks (ms)=11376 Total time spent by all reduce tasks (ms)=2888 Total vcore-milliseconds taken by all map tasks=11376 Total vcore-milliseconds taken by all reduce tasks=2888 Total megabyte-milliseconds taken by all map tasks=11649024 Total megabyte-milliseconds taken by all reduce tasks=2957312 Map-Reduce Framework Map input records=27 Map output records=69 Map output bytes=414 Map output materialized bytes=564 Input split bytes=192 Combine input records=0 Combine output records=0 Reduce input groups=69 Reduce shuffle bytes=564 Reduce input records=69 Reduce output records=33 Spilled Records=138 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=421 CPU time spent (ms)=2890 Physical memory (bytes) snapshot=709611520 Virtual memory (bytes) snapshot=5725220864 Total committed heap usage (bytes)=487063552 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=270 File Output Format Counters Bytes Written=510 17/08/31 14:48:21 INFO streaming.StreamJob: Output directory: GTHYout
最终结果
hadoop@master:~/test$ hadoop fs -text GTHYout/part-00000 BD ['A', 'E'] BE ['C'] BF ['A', 'C', 'E'] BG ['A', 'C', 'E'] BC ['A'] DF ['A', 'E'] DG ['A', 'E', 'F'] DE ['L'] HJ ['O'] HK ['A', 'C', 'D'] HI ['A', 'O'] HO ['A'] HL ['D', 'E'] FG ['A', 'C', 'D', 'E'] LM ['E', 'F'] KO ['A'] AC ['D', 'F'] AB ['C', 'E'] AE ['B', 'C', 'D'] AD ['E', 'F'] AG ['C', 'D', 'E', 'F'] AF ['B', 'C', 'D', 'E', 'O'] EG ['C', 'D'] EF ['B', 'C', 'D', 'M'] CG ['A', 'D', 'F'] CF ['A', 'D'] CE ['D'] CD ['A', 'F'] IK ['A'] IJ ['O'] IO ['A'] HM ['E'] KL ['D']
突然发现代码中居然一句注释都没有。果然自己还是太辣鸡,还没养成好习惯。
由于刚接触大数据不久,对java不熟悉,摸索地很慢。希望python的轻便能助我在大数据的世界探索更多。
有错的地方还请大佬多多指出~

