


4.1 线性判据基本概念
- 生成模型:直接在输入空间中学习其概率密度p(x),对于贝叶斯分类,用作观测似然。然后可以通过这个p(x)生成新的样本数据;也可以检测出较低概率的数据,进行离群点检测。但是p(x)需要大量的数据才能学习得好,不然会出现维度灾难。
- 判别模型:直接在输入空间输出后验概率。快速,省去了观测似然的部分。
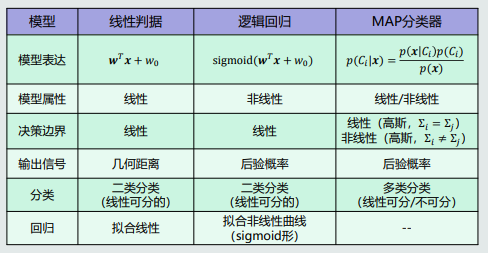
- 线性判据:如果判别模型f(x)是线性函数,那f(x)为线性判据。对于二分类,决策边界是线性;对于多分类,相邻两类的决策边界也是线性。计算量少,适合样本少的情况。
- 线性判据模型:f(x) = w^T x + w0, w决定了决策边界的方向,w0决定了决策边界的偏移量,使得输出可为正负。
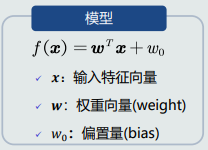

- 任意样本x到决策边界的垂直距离:r = f(x) / ||w||。


4.2 线性判据学习概述
- 线性判据有可能有多个解,所以学习算法要去找到最优解,也就是最优的w和w0。
- 目标函数常有均方差、交叉熵,加入各种约束条件来提高泛化能力,如正则项、加入边缘约束等,缩小解域。对其求最优一般两个方法:解析解、迭代梯度下降.
- 监督式学习(训练)过程
- 识别过程 f(x)</>0?
- key:寻找最优解?
- 解不唯一;
- 参数空间&解域(从解域中找到最优解);
- 设计目标函数 + 约束条件(提高泛化能力)
- 最大/最小化目标函数
4.3 并行感知机算法
- 感知机算法需要将负label取反。
- 目标函数是被错误分类的所有训练样本的输出取反求和。
- 由于目标函数求偏导后不含参数w和w0,所以使用梯度下降来找最优,需要设置步长、阈值,和初始化w和w0,当目标函数小于阈值或者大于等于0后,停止。


4.4 串行感知机算法
-
训练样本一个一个给出的时候,叫做串行。
-
目标函数相对于并行,变成对当前训练样本的输出取反。遍历所有样本,当ak.T @ yn时更新ak+1。

-
如果训练样本是线性可分的,感知机算法理论上会收敛。步长能够决定收敛的速度,以及是否收敛到局部或者全局最优点。目标函数如果对于任意a,存在常数L,使得|J(a)| < L,那么步长为1 / (2L) 的时候能够收敛到局部最优。如果目标函数是凸函数,局部最优就是全局最优。
-
当样本位于决策边界边缘的时候,对样本的决策有很大的不确定性,加入边缘约束b,使得解出的w和w0不为0
4.5 Fisher线性判据
-
Fisher:找到一个合适的投影轴,使得两类样本在轴上重叠部分最少。也就是类内样本离散程度更小,更聚集,类间差异更大,距离更远。

-
类间样本用均值差度量,类内样本用协方差矩阵度量。
-
fisher中利用协方差的逆,将两类均值差的向量进行旋转,以适应类分布的形状
4.6 支持向量机基本概念
- 感知机思想:最小化分类误差;fisher:数据降到一维,最大化类间距离,最小化类内散度。
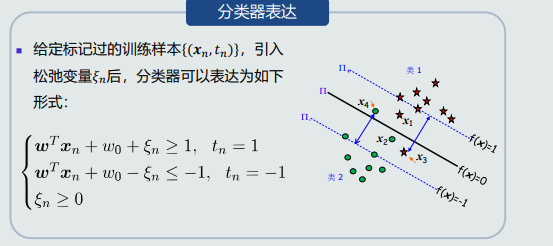
- 支持向量机思想:两个类与决策边界最近的训练样本到决策边界的距离和最大。
- 支持向量机需要将负类label设为-1。引入概念:支持向量。
- 目标函数就是最大化间隔的距离和,约束条件是间隔里面没有样本,也就是输出值的绝对值要大于间隔值,ppt上为1

4.7 拉格朗日乘数法
- 利用拉格朗日乘数法解决条件优化问题。
- 分为不等式约束和等式约束的优化问题。
- 等式约束中g(x) = 0的条件,使得λ可正可负,f(x)和g(x)的梯度方向一定平行,但方向可能同向或者反向,且梯度幅值不同。
- 不等式约束分为两种情况,一种是极值点在可行域内,相当于g(x) < 0,那么必有λ为0;另一种是极值点落在可行域边界,那么λ大于0,即f(x)的梯度方向将和g(x)平行且相反
4.8 拉格朗日对偶问题
- 对于要求解的主问题,往往难以求解。因此引入对偶函数,给出了主问题最优值的下界。
- 对偶函数与x无关,并且是凹函数。目标函数是凹函数,约束条件是凸函数,那么对偶问题是凸优化问题,不论主函数的凹凸性。
- 凸优化的性质:局部极值点就是全局极值点,于是对于主问题的求解,往往可以求解其对偶问题,得到主问题的下界估计。
- 分为强对偶性和弱对偶性。
4.9 支持向量机学习算法
- 回到4.6节未解决的最大化间隔的距离和,构建拉格朗日函数、对偶函数。
- 对对偶函数进行一系列的演化,利用二次规划求解N个最优的拉格朗日乘数,并以此计算最优的w和w0。
- w和w0的学习过程实际上是在训练样本中选择一组支持向量,用作线性分类器。
4.10 软间隔支持向量机
- 由于绝对地要求间隔中无样本,并且可能存在噪声和异常点,导致其被选作支持向量,使得决策边界过拟合。所以允许在一定程度上,让训练样本出现在间隔区域内。
- 因此引入松弛变量,松弛变量的大小决定了错误分类的程度,一般不能超过间隔大小,使得线性SVM可以近似分类非线性数据。
- 再引入正则系数,对错分进行惩罚,但要控制C不能过大,防止过拟合。
- 同样地,构建拉格朗日函数、对偶函数来求最优的w和w0。
4.11 线性判据多类分类
- 多类分类的本质是非线性。于是需要多个分类器进行组合。
- 方式一:one to all,需要K个分类器,并假设每个类与其他类线性可分。样本属于分类器输出为正的类。决策边界垂直于wi。不适合数据集不平衡,会出现重叠区域和拒绝区域。
- 方式二:线性机,对于输出,不再使用选择值为正的类,而是选择输出最大的类。因为离分类边界越远,该类被判错可能性越小,由此解决了重叠区域,但仍不能解决拒绝区域。
- 方式三:one to one,化为一个正类,其余类均为负类,共需要K(K - 1) / 2个分类器,能够避免数据集不平衡的问题。如果所有和Ci相关的分类器输出都为正,那么x属于Ci。可以适用于线性不可分的情况,实现非线性分类。仍存在拒绝区域,于是使用输出max思想,选择与其成对的所有分类器输出之和最大的类。

4.12 线性回归
-
模型表达

-
模型对比


-
输入样本分为tall数据和wide数据。
-
线性回归需要学习参数W,目标函数使用均方误差,最小化其输出和真值的误差。一般使用二范式。
-
使用最小二乘法或者梯度下降法来目标优化。
-
其中,如果X.T @ X是非奇异矩阵,那么W有唯一解,否则,W有无穷个解或者无解。对于tall数据,X.T @ X是非奇异矩阵的可能性大,如果是wide数据,那必定是奇异矩阵。因此,最小二乘法适合tall数据。
-
最大似然等同于最小化均方误差。
4.13 逻辑回归的概念

- 当两个类别数据的协方差不同时,MAP分类器的决策边界是超二次型曲面,非线性。
- 当观测是高斯分布并且协方差矩阵相同时,利用logit变换,后验概率对数比率等于线性判据输出。
- 线性模型f(x)输入sigmoid函数,得到logistic回归,就是其后验概率。
- 逻辑回归是一个非线性模型。
- 逻辑回归用于分类:仍然只能处理两个类别线性可分的情况。但是,sigmoid函数输出了后验概率,使得逻辑回归成为一个非线性模型。因此,逻辑回归比线性模型向前迈进了一步。
- 逻辑回归用于拟合:可以拟合有限的非线性曲线。
- 模型对比
4.14 逻辑回归的学习
- 逻辑回归需要学习w和w0。负类标签设为0。
- 利用最大似然估计,对于所有训练样本,最大化输出标签分布的似然函数,求得参数的最优值。
- 利用梯度下降法,迭代得到w和w0。
- sigmoid函数会出现梯度消失问题,在输出值接近于1的时候,输入的巨大变化也只能导致输出的小范围变动。所以在初始化的时候,选择较小的初始值,并设置阈值,到达阈值的精度时,停止迭代,防止过拟合。在神经网络中,利用relu等激活函数来代替sigmoid。
4.15 Softmax判据的概念
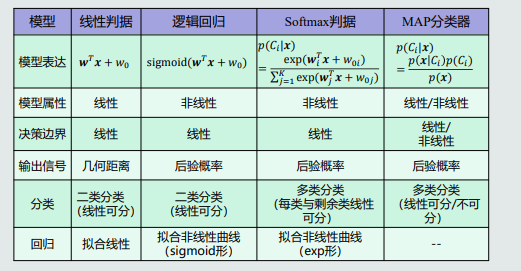
- 分类K个类,构建K个线性分类器,分为该类和剩余类。由于所有类的后验概率和为1,可以得到任意类的后验概率表示。也就使得K个线性分类器能够计算得到每个类的后验概率。
- 该方法叫做Softmax函数,由于K个分类器的输出,特别是一个类远大于其他类,此时需要将其进行exp函数和归一化操作。与max函数不同的是,Softmax函数可微分。
- 由此得到Softmax判据,就是得到最大Softmax函数计算得到的那个类的下标。在分类任务时,等同于one2one的线性机。
- Softmax判据常用于神经网络的输出层之后,比如利用CNN来分类手写数字时,得到其输出最大值下标。
- Softmax判据是一个非线性模型,对于分类任务,能够处理多个类别、每个类别和其余类线性可分的情况;对于回归任务,能够拟合exp形的非线性曲线。
- 模型对比
4.16 Softmax判据的学习

- Softmax判据需要学习K组w和w0。
- 和逻辑回归的学习相似,目标函数能够使用交叉熵解释。不同的是,使用one-hot编码,模型输出的概率分布符合多项分布。
- 在目标函数梯度下降求w和w0时,与逻辑回归不同的是,Softmax针对每个输出类别分别计算梯度值,但每个参数的梯度值与所有的类别样本都相关。
- Softmax判据输出为非线性,但只能刻画线性分类边界。
4.17 核支持向量机 (Kernel SVM)
-
Kernel思想是将低维空间中线性不可分的样本数据,找到一个映射,使得这些样本数据在高维空间线性可分。
-
由此,就能够使用SVM来进行分类。
-
核函数:在低维空间的一个非线性函数,包含向量映射和点积计算。
- 多项式核函数
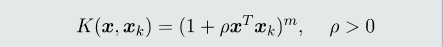
- 高斯核函数
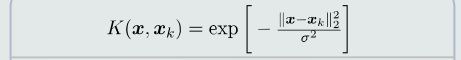
- 多项式核函数
-
核SVM的决策是关于测试样本和支持向量的核函数的线性组合。决策边界是非线性的。
-
同样的,在高维空间中计算SVM时,也需要计算其对偶问题的解,对于软间隔SVM也需要引入松弛量。
-
多项式核可以解决线性不可分问题,但当参数较大时,计算困难,超参数多。
-
高斯核具有更明显的非线性,但容易过拟合。
思维导图
 posted on
posted on
