
学习视频课程
网络空间安全概论第五章笔记链接
实验题(30'+120')
热身题
①基本思路
- 安装虚拟机:Virtual Box
- 安装Ubuntu系统
- 打开终端,安装gcc
- 编写程序
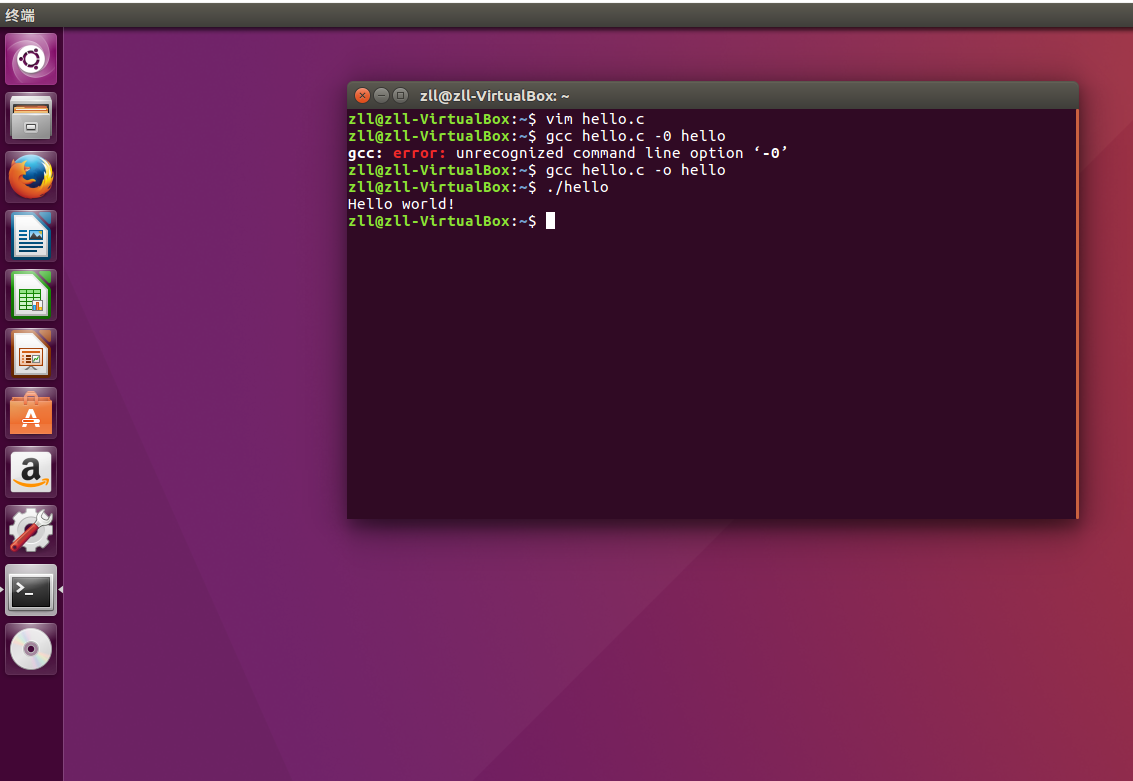
②实现结果:
代码链接:hello.c
截图:
基本题
①了解新技术
- 简单描述什么是sketch?
- sketch:
- sketch是使用哈希(散列)来进行估计网络流的一种测试方法,无需记录所有数据,只记录存储数据的特征,以此减少存储开销。
- 具体到CM sketch算法中:使用二维的哈希表, w是哈希表的取值空间, d是哈希函数的个数。对某个元素, 分别使用d个哈希函数计算相应的哈希值, 并在对应的桶上递增1, 每个桶的值称为sketch。
- sketch:
- 描述Count-min sketch的算法过程
-
使用d个哈希函数,每个哈希函数的取值范围都在[1,w]内,从而可以组成一个d*w的二维数组
-
对于每个二元组(k,v),代表元素k需要更新v次
-
分别使用d个哈希函数对k进行哈希操作,得到d个mapped counter,然后对它们全部加v

-
当需要查询某个元素的频率估计值时,先根据哈希函数得到mapped counter
-
然后去其中的最小值(最小值代表出现次数最少,相对最精确)
-
- 补充知识(hash函数):
- 基本概念:
- Hash,一般翻译做"散列",也有直接音译为"哈希"的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。
- 这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。
- 简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
- 性质:
- 如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。
- 散列函数的输入和输出不是一一对应的,如果两个散列值相同,两个输入值很可能是相同的,但不绝对肯定二者一定相等(可能出现哈希碰撞)。
- 散列表:
- 散列表是散列函数的一个主要应用,使用散列表能够快速的按照关键字查找数据记录。(就像英语字典)
- 哈希碰撞:
- 简单来说,如果不同的输入得到了同一个哈希值,就发生了"哈希碰撞"(collision)。
- 举例来说,很多网络服务会使用哈希函数,产生一个 token,标识用户的身份和权限。如果两个不同的用户,得到了同样的 token,就发生了哈希碰撞。服务器将把这两个用户视为同一个人,这意味着,用户 B 可以读取和更改用户 A 的信息,这无疑带来了很大的安全隐患。
- 基本概念:
- 为什么使用多个哈希函数
- 使用哈希,会有冲突,不同的元素哈希到同一个数组的位置索引,这样,频率的统计都会偏大。
- 如果使用多个数组,和多个哈希函数,来计算一个元素对应的数组的位置索引;
- 那么,要查询某个元素的频率时,返回这个元素在不同数组中的计数值中的最小值。这样还是有冲突,不过冲突会比较少。
②实现新技术:
基本思路:
- 在GitHub上面寻找相应代码
- 阅读readme.txt文件了解其中的函数如何调用
- 使用c.update更新:自己任意定义字符串“hello”、“world”
- 使用c.estimate查询“hello”、“world”两个字符串的频率
- 输出查询得到的值
- (感谢程同学改掉了GitHub上代码的bug)
实现结果:
- 所用的count min sketch代码链接:GitHub
- 代码链接: test without files
- 截图:

③获取用户请求:
基本思路:
- 安装tcpsump
- 输入指令sudo tcpdump -i enp0s3 -n > pakcet_capture.txt 抓取数据并重定向到.txt文件中
实现结果:
- 文件链接:pakcet_capture.txt
- 文件截图:

④请求格式转换:
基本思路:
- 利用fgets函数从文件中读取数据到字符数组I当中
- 将请求的用户,length保存到字符数组O当中
- 输出字符数组O
- 使用 > 重定向输出到文件Request.txt
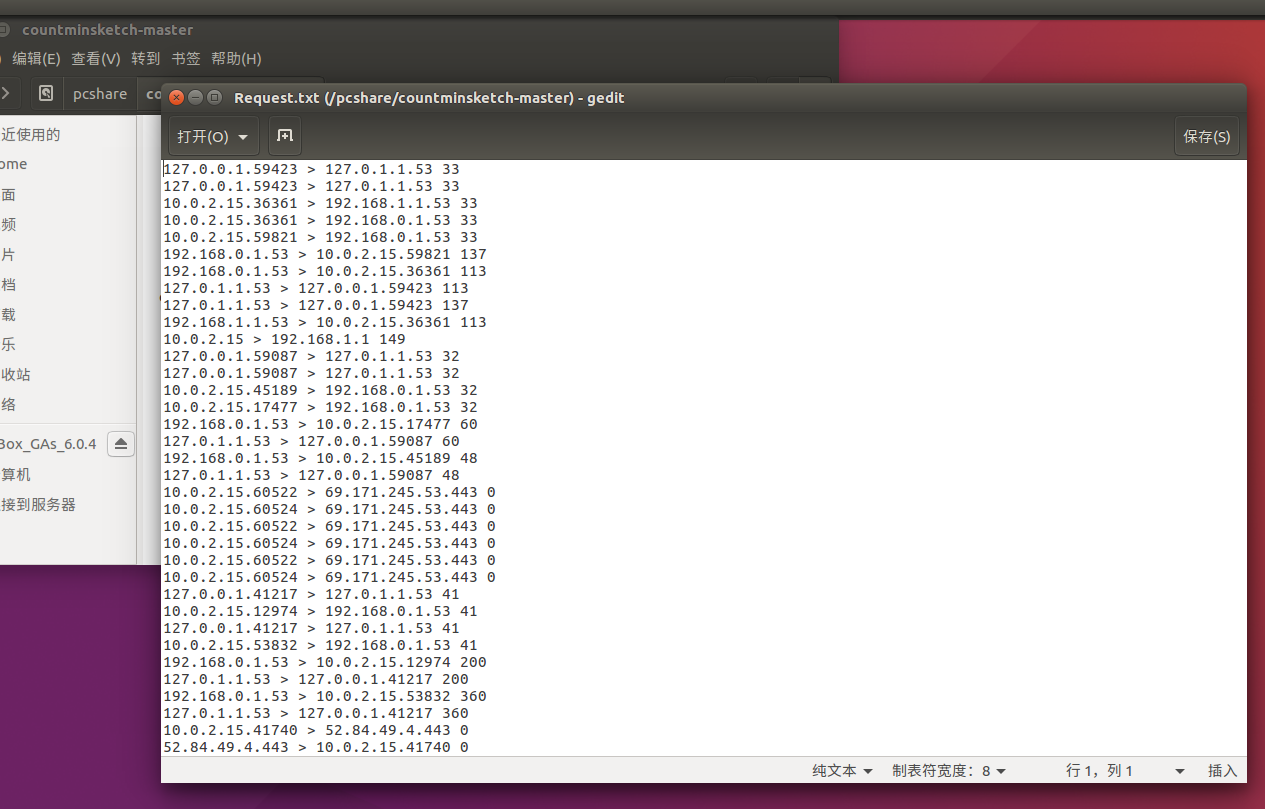
实现结果:
- 代码链接:conversion.cpp
- 文件链接:Request.txt
- 截图:
⑤测试新技术:
基本思路:
- 读取一组数据到数组IP
- 逆序保存length数值
- 数组IP仅保留请求的用户名
- 使用c.update更新总请求值
- 判断此IP是否已经在黑客名单内
- 如果不在黑客名单内,而且查询得到的值大于阈值T,拉入黑客名单
- 输出黑客名单
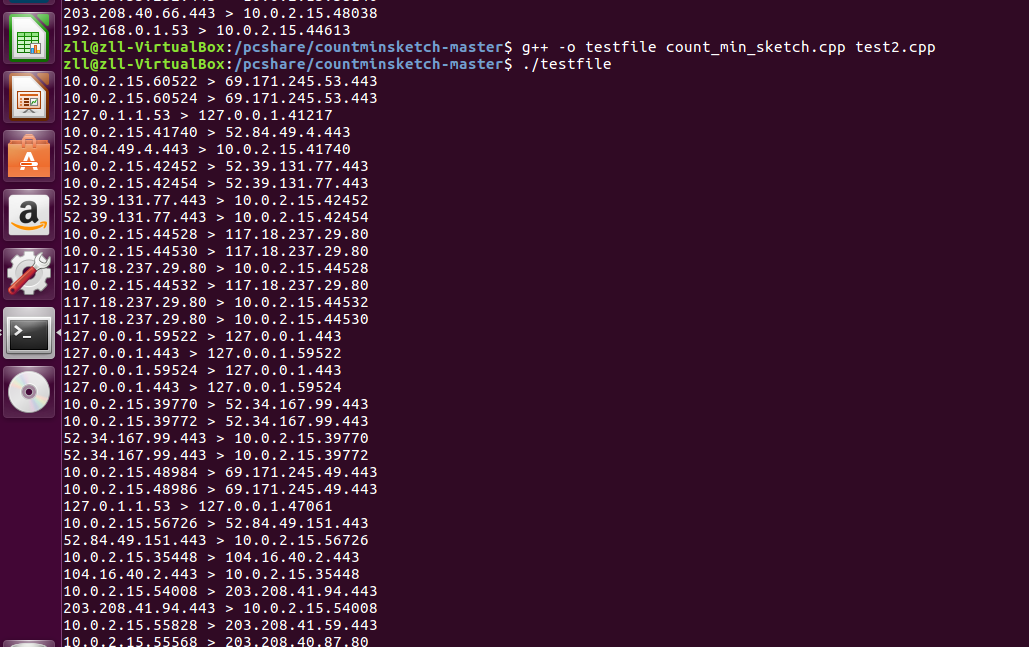
实现结果:
- 代码链接:test2
- 截图:

开放题
①理论部分:
-
解释为什么sketch可以省空间
- sketch使用哈希函数,而哈希函数可以把任意长度的输入映射为固定长度的输出。
- 所以,不需要把每组数据都存储下来,只要创建几个数组来存储元素sketch的计数。每组数据根据哈希值来分类,各种包再根据哈希值归来。
- 如此一来,就可以节省大量原本用于存储数据的空间。(特别是当每组数据都很长时)
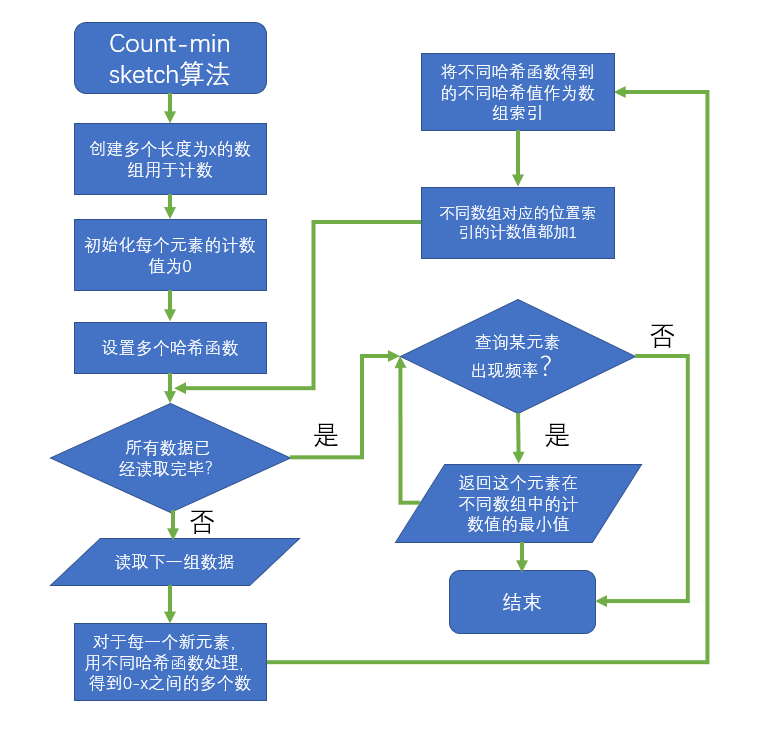
-
用流程图描述count-min sketch的算法过程:
-
拿它和你改进后的方法对比,分析它的优劣:
- 优点:
- 通用性更强
- 更好的解决了用户名很长的问题
- 对于庞大的数据,处理效率更高,查询某元素的效率也更高
- 只需要固定大小的内存和计算时间,和需要统计的元素多少无关
- 缺点:
- 当数据总量不够大时,精确度不是很高
- 使用hash函数,就可能产生哈希碰撞
- 优点:
-
吐槽count min sketch:
- github上面的代码有些会却库缺函数,bug有点多
- 难度有点大,不易掌握(对我来说)
②实验部分:
-
基本思路:
- 直接从终端上实时获取数据
- 格式转换
- 使用c.update更新此用户请求总值
- 判断是否已经拉入黑客名单
- 如果已经拉入黑客名单,则忽略这条请求
- 如果未拉入黑名单且请求总值超过阈值T,则拉入黑客名单
- 实时输出新增黑客(重定向到txt文件当中)
-
关于实时:
- 可能需要一个人为操作来确定读取结束(比如CTRL+c),否则只要出现新数据就读取
-
实现:没找到如何解决“实时获取”的方法
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号