Spring Boot 集成 ShardingSphere-JDBC 配置示例
概述
Apache ShardingSphere‐JDBC 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆。
Apache ShardingSphere‐JDBC 可以通过 Java,YAML,Spring 命名空间和 Spring Boot Starter这 4 种方式进行配置,开发者可根据场景选择适合的配置方式。本文章主要讲解数据分片、读写分离、分布式主键配置。
官网地址:http://shardingsphere.apache.org/index_zh.html
功能
| 特性 | 定义 |
|---|---|
| 分布式事务 | 事务能力,是保障数据库完整、安全的关键技术,也是数据库的核心技术之一。ShardingSphere 提供在单机数据库之上的分布式事务能力,可实现跨底层数据源的数据安全。 |
| 数据分片 | 数据分片,是应对海量数据存储与计算的有效手段。ShardingSphere 提供基于底层数据库之上,可计算与存储水平扩展的分布式数据库解决方案。 |
| 读写分离 | 读写分离,是应对高压力业务访问的手段之一。ShardingSphere 基于对SQL语义理解及底层数据库拓扑感知能力,提供灵活、安全的读写分离能力,且可实现读访问的负载均衡。 |
| 高可用 | 高可用,是对数据存储计算平台的基本要求。ShardingSphere 基于无状态服务,提供高可用计算服务访问;同时可感知并利用底层数据库自身高可用实现整体的高可用能力。 |
| 数据加密 | 数据加密,是保证数据安全的基本手段。ShardingSphere 提供一套完整的、透明化、安全的、低改造成本的数据加密解决方案。 |
| 影子库 | 在全链路压测场景下,ShardingSphere 通过影子库功能支持在复杂压测场景下数据隔离,压测获得测试结果可准确反应系统真实容量和性能水平。 |
引入依赖
本文章版本 5.1.2 ,概述里面说到的 4 种方式配置,不同的配置引入的Maven包会不一样。 本文章采用Spring Boot Starter配置。
<!--依赖sharding-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.2</version>
</dependency>
数据分片
垂直分片
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
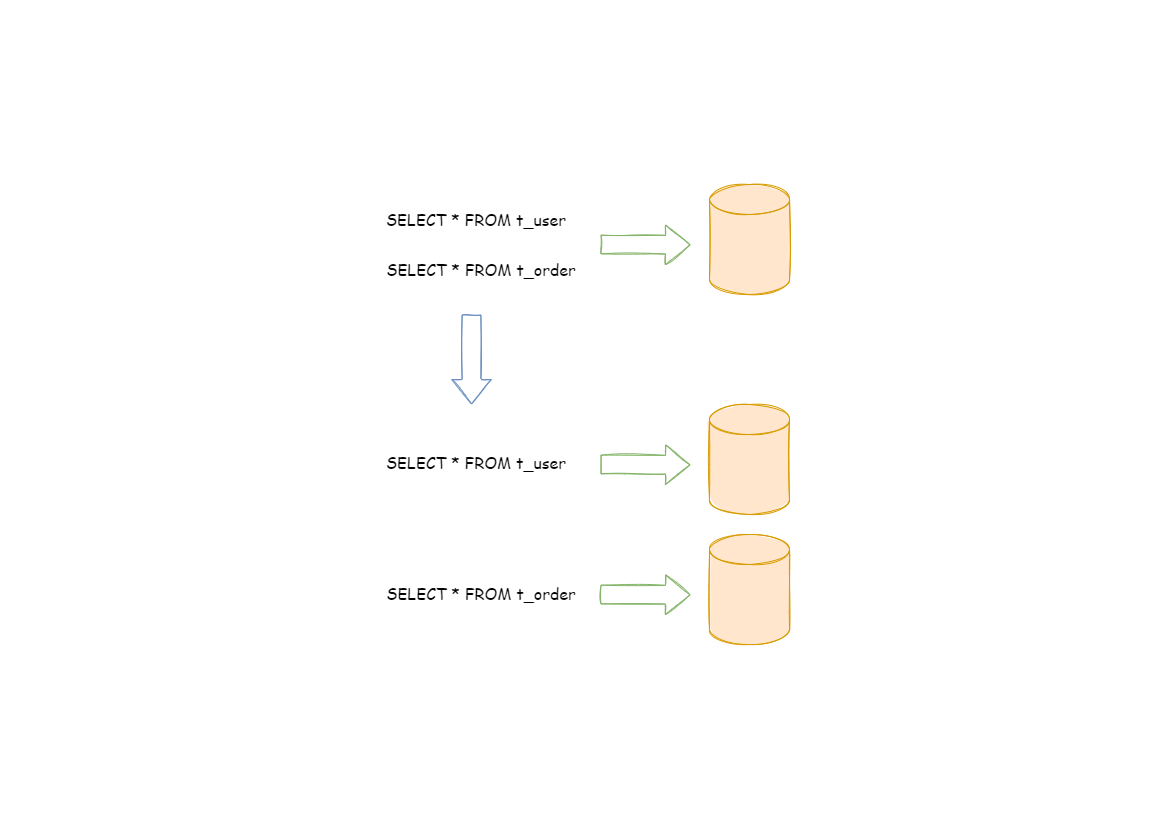
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。 垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
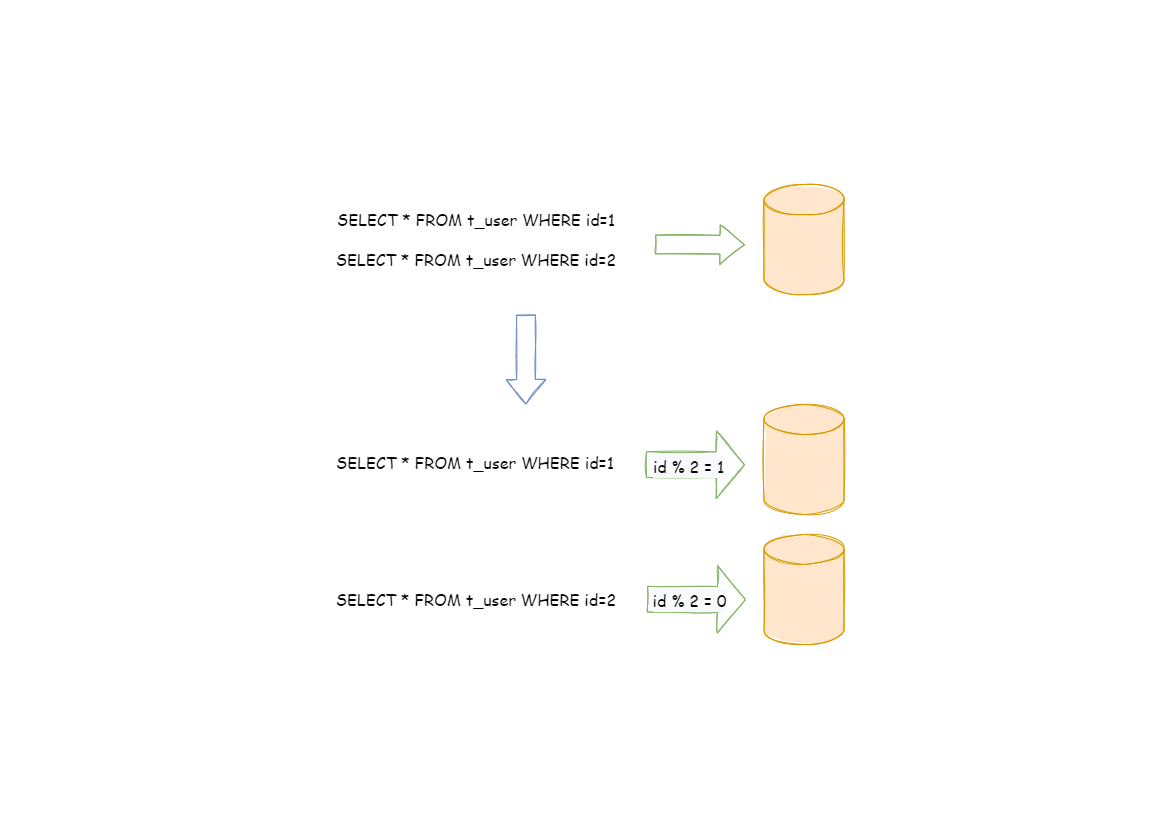
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
配置示例
server:
port: 8095
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
database:
name: ds # 逻辑库名称,默认值:logic_db
props:
sql-show: true
# 配置数据源
dataSource:
# 给每个数据源取别名,下面的ds0,ds1任意取名字
names: ds0,ds1,ds2,ds3
# 给master-ds0每个数据源配置数据库连接信息
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3307/hlw?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password:
# 配置ds1-slave
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3307/hlw1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password:
ds2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3308/hlw?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password:
ds3:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3308/hlw1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password:
rules:
sharding:
tables:
# db_user 逻辑表名
db_user:
# 数据节点:数据源$->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.db_user$->{0..1}
key-generate-strategy: # 分布式序列策略
column: id # 自增列名称,缺省表示不使用自增主键生成器
keygenerator-name: snowflake # 分布式序列算法名称
# 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。
database-strategy:
standard:
sharding-column: age # 分片字段(分片键)
sharding-algorithm-name: database-inline # 分片算法名称
# 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。
table-strategy:
standard:
sharding-column: age # 分片字段(分片键)
sharding-algorithm-name: table-inline # 分片算法名称
default-sharding-column: age # 默认分片列名称
default-database-strategy: # 默认数据库分片策略
standard:
sharding-column: age
sharding-algorithm-name: database-inline
default-table-strategy: # 默认表分片策略
standard:
sharding-column: age
sharding-algorithm-name: table-inline
binding-tables[0]:
db_user
sharding-algorithms:
database-inline:
type: INLINE # 分片算法类型
props:
algorithm-expression: ds$->{age % 2} # 分片算法表达式
table-inline:
type: INLINE
props:
algorithm-expression: db_user$->{age % 2} # 分片算法表达式
key-generators:
snowflake:
type: SNOWFLAKE
读写分离
应用场景
许多系统通过采用主从数据库架构的配置来提高整个系统的吞吐量,但是主从的配置也给业务的使用带来了一定的复杂性。接入 ShardingSphere,可以利用读写分离功能管理主从数据库,实现透明化的读写分离功能,让用户像使用一个数据库一样使用主从架构的数据库。
配置示例
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
dataSource: # 此次省略数据源及分库分表的配置 可参考上面
rules:
readwrite-splitting: # 读写分离配置
data-sources:
ds0:
type: Static
load-balancer-name: round-robin
props:
# 注意,如果接口有事务,读写分离不生效,默认全部使用主库,为了保证数据一致性
write-data-source-name: ds0 # 写库数据源名称
read-data-source-names: ds0,ds2 # 读库数据源列表,多个从数据源用逗号分隔
ds1:
type: Static
load-balancer-name: round-robin # 负载均衡算法名称
props:
write-data-source-name: ds1
read-data-source-names: ds1,ds3
load-balancers:
round-robin:
type: ROUND_ROBIN #一共三种一种是 RANDOM(随机),一种是 ROUND_ROBIN(轮询),一种是 WEIGHT(权重)
注意
官网文档亲测有个小bug,在同时配置数据分片和读写分离时,不能按照官网配置启动会有报错,读写分离配置要按照5.1.0版去配置
如下为官网配置,上面配置示例为亲测可用的配置
spring.shardingsphere.datasource.names= # 省略数据源配置,请参考使用手册
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splittingdata-source-name>.static-strategy.write-data-source-name= # 写库数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splittingdata-source-name>.static-strategy.read-data-source-names= # 读库数据源列表,多个从数据源
用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splittingdata-source-name>.load-balancer-name= # 负载均衡算法名称
# 负载均衡算法配置
spring.shardingsphere.rules.readwrite-splitting.load-balancers.<load-balancealgorithm-name>.type= # 负载均衡算法类型
spring.shardingsphere.rules.readwrite-splitting
分布式事务
应用场景
在单机应用场景中,依赖数据库提供的事务即可满足业务上对事务 ACID 的需求。但是在分布式场景下,传统数据库解决方案缺乏对全局事务的管控能力,用户在使用过程中可能遇到多个数据库节点上出现数据不一致的问题。
ShardingSphere 分布式事务,为用户屏蔽了分布式事务处理的复杂性,提供了灵活多样的分布式事务解决方案,用户可以根据自己的业务场景在 LOCAL,XA,BASE 三种模式中,选择适合自己的分布式事务解决方案。
LOCAL 事务
支持项
- 完全支持非跨库事务,例如:仅分表,或分库但是路由的结果在单库中;
- 完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能够回滚。
不支持项
- 不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库宕机,则只有第二个库数据提交,且无法回滚。
XA 事务
支持项
- 支持 Savepoint 嵌套事务;
- PostgreSQL/OpenGauss 事务块内,SQL 执行出现异常,执行 Commit,事务自动回滚;
- 支持数据分片后的跨库事务;
- 两阶段提交保证操作的原子性和数据的强一致性;
- 服务宕机重启后,提交/回滚中的事务可自动恢复;
- 支持同时使用 XA 和非 XA 的连接池。
不支持项
- 服务宕机后,在其它机器上恢复提交/回滚中的数据;
- MySQL 事务块内,SQL 执行出现异常,执行 Commit,数据保持一致。
BASE 事务
支持项
- 支持数据分片后的跨库事务;
- 通过 undo 快照进行事务回滚;
- 支持服务宕机后的,自动恢复提交中的事务。
不支持项
- 不支持隔离级别。
事务对比
| LOCAL | XA | BASE | |
|---|---|---|---|
| 业务改造 | 无 | 无 | 需要 seata server |
| 一致性 | 不支持 | 支持 | 最终一致 |
| 隔离性 | 不支持 | 支持 | 业务方保证 |
| 并发性能 | 无影响 | 严重衰退 | 略微衰退 |
| 适合场景 | 业务方处理不一致 | 短事务 & 低并发 | 长事务 & 高并发 |
使用方式
@Transactional
@ShardingTransactionType(TransactionType.XA)
public void insert(){
…
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号