


hashMap的扩容机制
HashMap的扩容机制
阅读此文章前最好看一下介绍HashMap的实现原理:
叶文洁:HashMap的实现原理zhuanlan.zhihu.com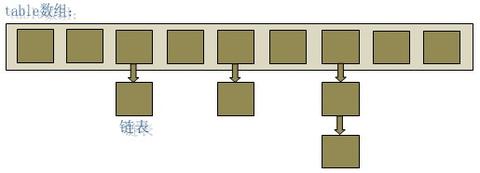
为了方便说明,这里明确几个名词:
- capacity 即容量,默认16。
- loadFactor 加载因子,默认是0.75
- threshold 阈值。阈值=容量*加载因子。默认12。当元素数量超过阈值时便会触发扩容。
什么时候触发扩容?
一般情况下,当元素数量超过阈值时便会触发扩容。每次扩容的容量都是之前容量的2倍。
HashMap的容量是有上限的,必须小于1<<30,即1073741824。如果容量超出了这个数,则不再增长,且阈值会被设置为Integer.MAX_VALUE( ,即永远不会超出阈值了)。
JDK7中的扩容机制
JDK7的扩容机制相对简单,有以下特性:
- 空参数的构造函数:以默认容量、默认负载因子、默认阈值初始化数组。内部数组是空数组。
- 有参构造函数:根据参数确定容量、负载因子、阈值等。
- 第一次put时会初始化数组,其容量变为不小于指定容量的2的幂数。然后根据负载因子确定阈值。
- 如果不是第一次扩容,则
,
。
JDK8的扩容机制
JDK8的扩容做了许多调整。
HashMap的容量变化通常存在以下几种情况:
- 空参数的构造函数:实例化的HashMap默认内部数组是null,即没有实例化。第一次调用put方法时,则会开始第一次初始化扩容,长度为16。
- 有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的2的幂数,将这个数设置赋值给阈值(threshold)。第一次调用put方法时,会将阈值赋值给容量,然后让
。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!)
- 如果不是第一次扩容,则容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,负载因子还是不变)
此外还有几个细节需要注意:
- 首次put时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;
- 不是首次put,则不再初始化,直接存入数据,然后判断是否需要扩容;
扩容时容量的计算方法说完了,下面说一说元素的迁移。
JDK7的元素迁移
JDK7中,HashMap的内部数据保存的都是链表。因此逻辑相对简单:在准备好新的数组后,map会遍历数组的每个“桶”,然后遍历桶中的每个Entity,重新计算其hash值(也有可能不计算),找到新数组中的对应位置,以头插法插入新的链表。
这里有几个注意点:
- 是否要重新计算hash值的条件这里不深入讨论,读者可自行查阅源码。
- 因为是头插法,因此新旧链表的元素位置会发生转置现象。
- 元素迁移的过程中在多线程情境下有可能会触发死循环(无限进行链表反转)。
JDK8的元素迁移
JDK8则因为巧妙的设计,性能有了大大的提升:由于数组的容量是以2的幂次方扩容的,那么一个Entity在扩容时,新的位置要么在原位置,要么在原长度+原位置的位置。原因如下图:
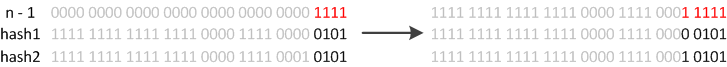
数组长度变为原来的2倍,表现在二进制上就是多了一个高位参与数组下标确定。此时,一个元素通过hash转换坐标的方法计算后,恰好出现一个现象:最高位是0则坐标不变,最高位是1则坐标变为“10000+原坐标”,即“原长度+原坐标”。如下图:
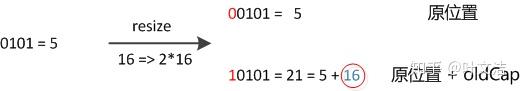
(图片来源于文末的参考链接)
因此,在扩容时,不需要重新计算元素的hash了,只需要判断最高位是1还是0就好了。
JDK8的HashMap还有以下细节:
- JDK8在迁移元素时是正序的,不会出现链表转置的发生。
- 如果某个桶内的元素超过8个,则会将链表转化成红黑树,加快数据查询效率。

