
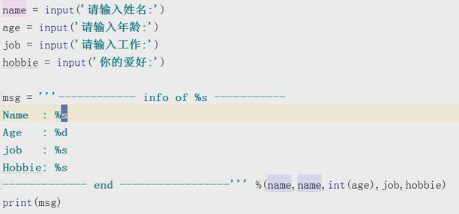
python 2
格式化输出
#% s d %是占位符,s 是字符串,d是数字
有时%仅表示百分号,但在格式化输出中计算机识别不到,会报错,这是写两个%%即可表示单纯的百分号。(第一个百分号为占位符,转译),如:
msg=“我叫%s,今年%s,身高%s,学习进度为3%%”%(name,age,height)

初始编码
最开始:
00101010 8位bit == 1个字节(1 byte)
1byte 1024byte == 1kb
1kb 1024kb == 1MB
1MB 1024MB ==1GB
1GB 1024GB ==1TB
电脑的传输和存储的都是二进制。
美国:ascii码(只显示英文,特殊字符和数字)1个字节,8位,为了解决这个全球化的文字问题,创建了一个万国码,unicode.
最开始uincode:16位或32位。
#中文9万多字
- 一个字节,表示所以英文,特殊字符,数字等等。2**8=256
- 2个字节,16位表示一个中文,有2**16=65536种可能,没有完全包含中国字,不够用。后来用了4个字节,2**32种可能,很浪费。
uincode升级版:(utf-8,utf-16,utf-32) utf-8 最少一个字节,8位表示英文;欧洲16位,两个字节;亚洲24位,3个字节表示是一个中文。2**24=67777216(包含各国语言)
#python2默认ascii码编译的,不包含中文,python3是utf-8
#gbk也是密码本,只有中文,国内使用。一个中文2个字节,不能包含所有中文。只能用于中文和ascii码中的中文。
运算符
运算有算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算。
算数运算:
+ - * / %(取余) **(幂) //(取整)
比较运算:
假设变量a=10,b=20
==(等于,比较两个对象是否相等)#(a==b)返回False.
!=(不等于,比较两个对象是否不相等)#(a!=b)返回True.
<>(不等于,同!=)
> , < , >= , <=
赋值运算:
= ,+=, -= ,*= ,/= ,%= ,**= ,//=
逻辑运算:
and(布尔“与”),or(布尔“或”),not(布尔“非”)
1,在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
2 , x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y , x为假,值是x。 #and相反
如:print(0 or 2) 2
print(1 or 2) 1
print(0 and 2) 0
print(1 and 2) 2
print(0 or 3 and 4 or 2) 4
print(1>2 and 3 or 4 and 3<2) False
print(2 or 1<3 and 2) 2
#逻辑运算符前后是大于小于这种比较的时候返回的是F or T。前后都是数字则返回的是数字。
#int——>bool,非零转换成bool 是True,另转换成bool是False.
