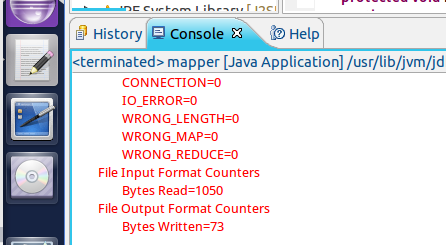
Mapreduce实例
实验原理
MapReduce采用的是“分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个从节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单来说,MapReduce就是”任务的分解与结果的汇总“。
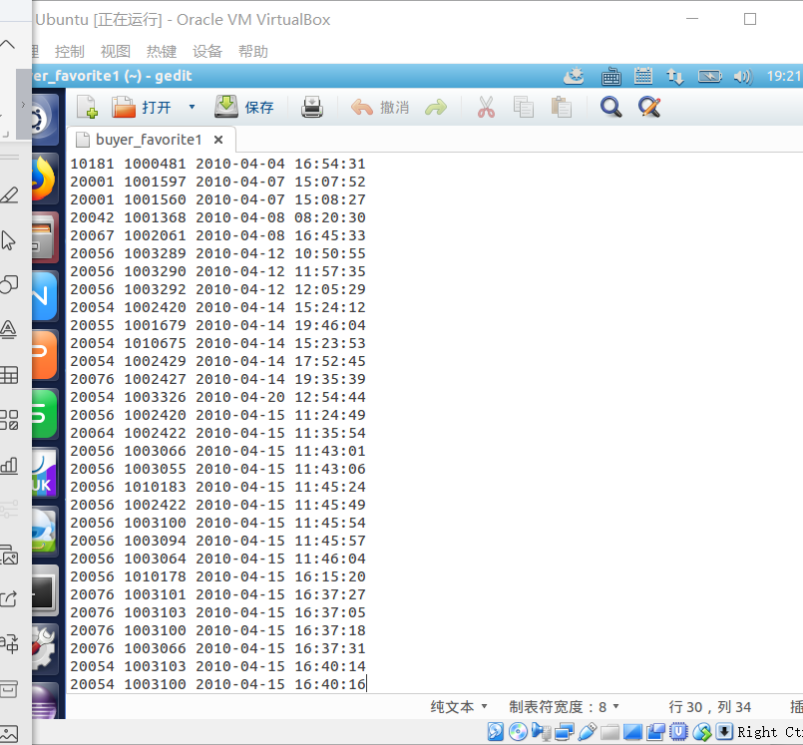
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1。
buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“\t”分割,样本数据及格式如下:

实验步骤
- 先启动hadoop

2.然后在home/hadoop目录下创建一个buyer_favorite1的文件,将实例中的数据复制粘贴到该文件里
3.然后在HDFS目录下创建/mymapreduce1/in目录
./bin/hdfs dfs -mkdir -p /mymapreduce1/in

4.然后将home/hadoop/buyer_favorite1文件上传到HDFS上/mymapreduce1/in目录下
./bin/hdfs dfs -put /home/hadoop/buyer_favorite1 /mymapreduce1/in
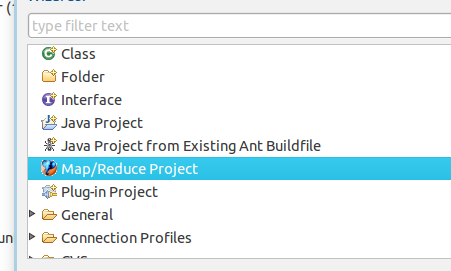
5.然后打开eclipse 新建project项目,选择map/reduce project项目
6.然后创建包创建类
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class mapper {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("mapper");
job.setJarByClass(mapper.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path in = new Path(
"hdfs://localhost:9000/mymapreduce1/in/buyer_favorite1");
Path out = new Path(
"hdfs://localhost:9000/mymapreduce1/out");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class doMapper extends
Mapper<Object, Text, Text, IntWritable> {
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString(),
" /t");
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
public static class doReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
}
将这些代码复制粘贴到项目里,然后运行run as run on hadoop