
Paper Reading - Attention Is All You Need ( NIPS 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1706.03762
Motivation:
- The inherently sequential nature of Recurrent Models precludes parallelization within training examples.
- Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences. In all but a few cases, however, such attention mechanisms are used in conjunction with a recurrent network.
Innovation:
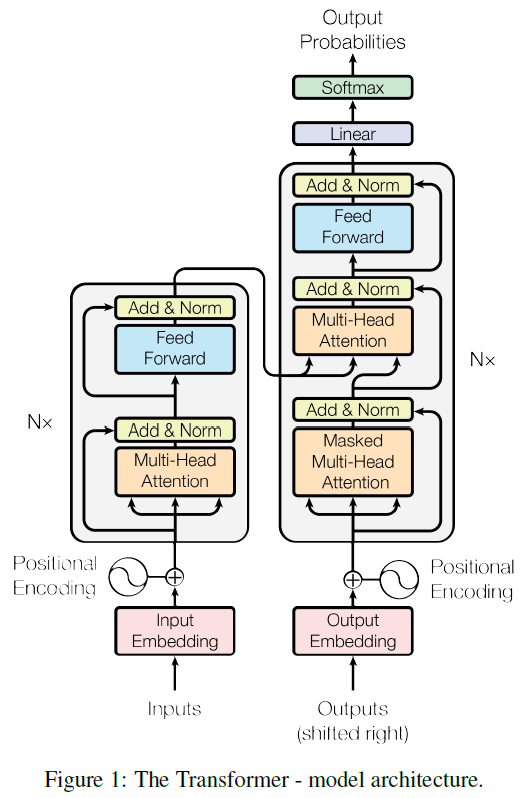
- The first sequence transduction model, the Transformer, relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or Convolutions. The Transformer follows the overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
- Encoder: The encoder is composed of a stack of N = 6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. The authors employ a residual connection around each of the two sub-layers, followed by layer normalization. That is, the output of each sub-layer is LayerNorm (x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel = 512.
- Decoder: The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, they employ residual connections around each of the sub-layers, followed by layer normalization. They also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
- Scaled Dot-Product Attention and Multi-Head Attention. The Transformer uses multi-head attention in three different ways:
- In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models such as [ Google’s neural machine translation system: Bridging the gap between human and machine translation. ].
- The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder. [ More about Attention Definition ]
- Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. They need to prevent leftward information flow in the decoder to preserve the auto-regressive property. They implement this inside of scaled dot-product attention by masking out (setting to -∞) all values in the input of the softmax which correspond to illegal connections. See Figure 2.
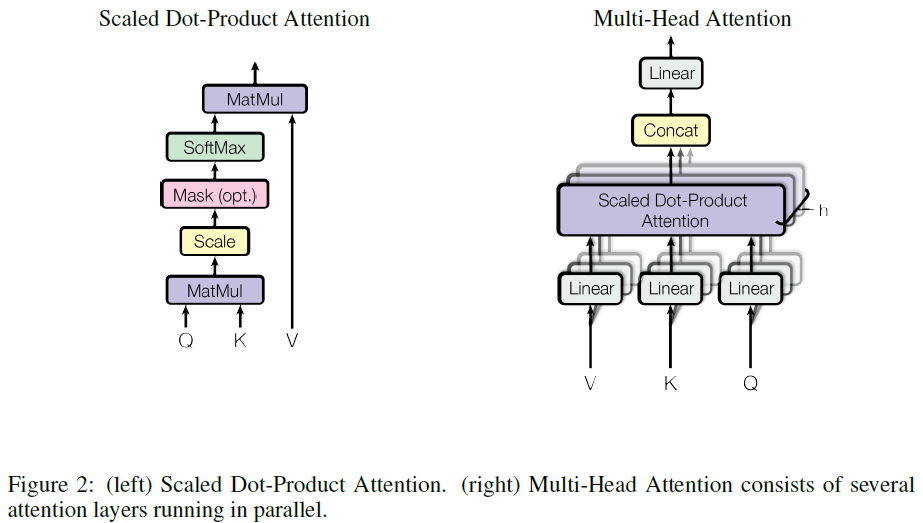
In terms of encoder-decoder, the query Q is usually the hidden state of the decoder. Whereas key K, is the hidden state of the encoder, and the corresponding value V is normalized weight, representing how much attention a key gets. -- The Transformer - Attention is all you need.
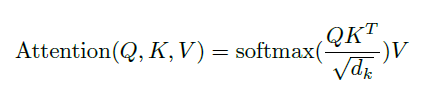

- Positional Encoding: Add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. In this work, they use sine and cosine functions of different frequencies:
- PE(pos, 2i) = sin ( pos / 100002i/dmodel )
- PE(pos, 2i+1) = cos ( pos / 100002i/dmodel)
Improvement:
- Position-wise Feed-Forward Networks: In addition to attention sub-layers, each of the layers in their encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between. FFN(x) = max(0, xW1 + b1)W2 + b2.
General Points:
- An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
- Why Self-Attention:
- One is the total computational complexity per layer. Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required.
- The third is the path length between long-range dependencies in the network.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号