
Paper Reading - CNN+CNN: Convolutional Decoders for Image Captioning
Link of the Paper: https://arxiv.org/abs/1805.09019
Innovations:
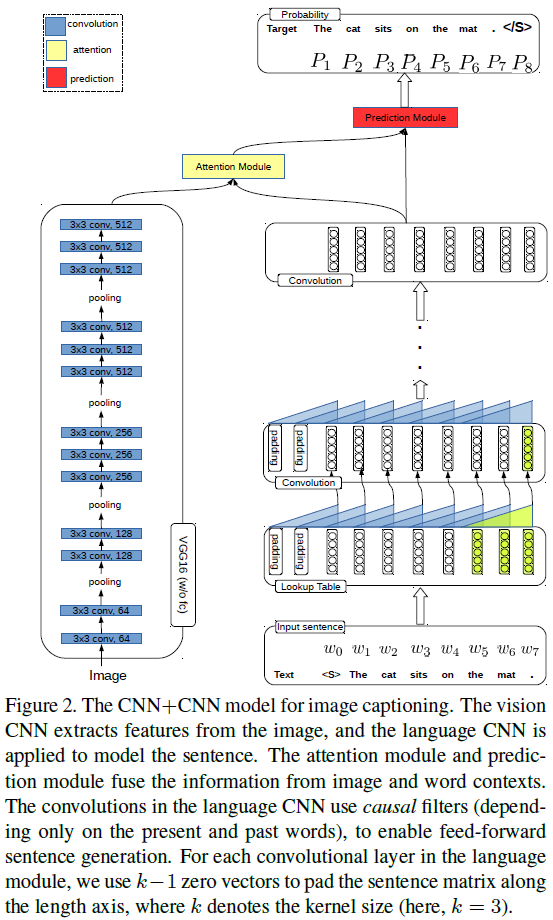
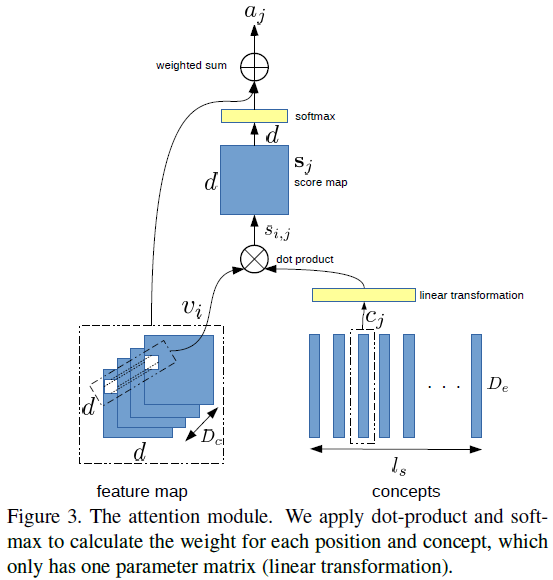
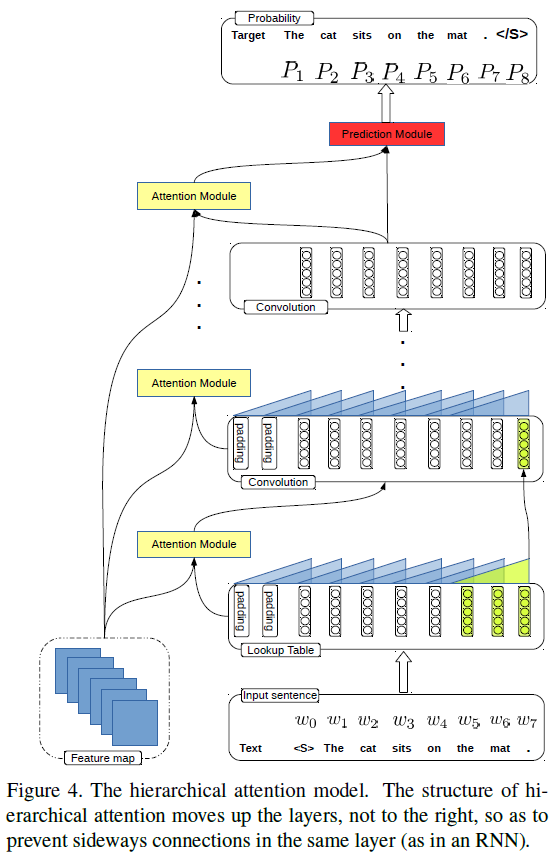
- The authors propose a CNN + CNN framework for image captioning. There are four modules in the framework: vision module ( VGG-16 ), which is adopted to "watch" images; language module, which is to model sentences; attention module, which connects the vision module with the language module; prediction module, which takes the visual features from the attention module and concepts from the language module as input and predicts the next word.
General Points:
- RNNs or LSTMs cannot be calculated in parallel and ignore the underlying hierarchical structure of a sentence.
- Directly feeding the output of the CNN into the RNN treats objects in an image the same and ignores the salient objects when generating one word.
- In both m-RNN and NIC, an image is represented by a single vector, which ignores different areas and objects in the image. A spatial attention mechanism is introduced into image captioning model in Show, attend and tell: Neural image caption generation with visual attention, which allows the model to pay attention to different areas at each time step.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号