

Link of the Paper: https://arxiv.org/pdf/1412.6632.pdf
Main Points:
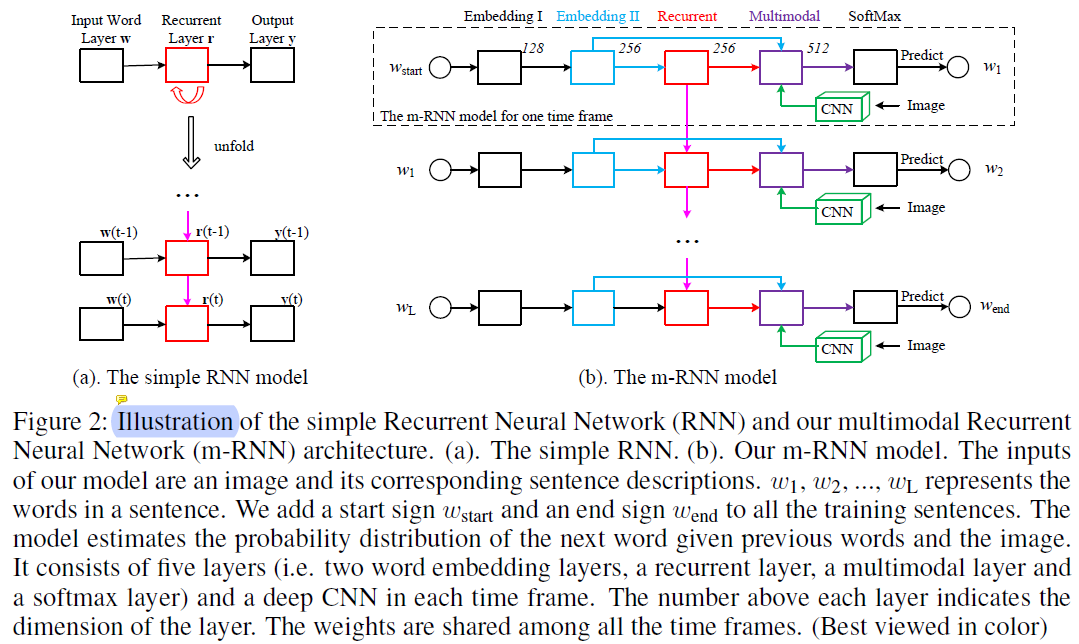
- The authors propose a multimodal Recurrent Neural Networks ( AlexNet/VGGNet + a multimodal layer + RNNs ). Their work has two major differences from these methods. Firstly, they incorporate a two-layer word embedding system in the m-RNN network structure which learns the word representation more efficiently than the single-layer word embedding. Secondly, they do not use the recurrent layer to store the visual information. The image representation is inputted to the m-RNN model along with every word in the sentence description.
- Most of the sentence-image multimodal models use pre-computed word embedding vectors as the initialization of their models. In contrast, the authors randomly initialize their word embedding layers and learn them from the training data.
- The m-RNN model is trained using a log-likelihood cost function. The errors can be backpropagated to the three parts ( the vision part, the language part, and the ) of the m-RNN model to update the model parameters simultaneously.
- The hyperparameters, such as layer dimensions and the choice of the non-linear activation functions, are tuned via cross-validation on Flickr8K dataset and are then fixed across all the experiments.
Other Key Points:
- Applications for Image Captioning: early childhood education, image retrieval, and navigation for the blind.
- There are generally three categories of methods for generating novel sentence descriptions for images. The first category assumes a specific rule of the language grammer. They parse the sentence and divide it into several parts. This kind of method generates sentences that are syntactically correct. The second category retrieves similar captioned images, and generates new descriptions by generalizing and re-composing the retrieved captions. The third category of methods, which is more related to our method, learns a probability density over the space of multimodal inputs, using for example, Deep Boltzmann Machines, and topic models. They generate sentences with richer and more flexible structure than the first group. The probability of generating sentences using the model can serve as the affinity metric for retrieval.
- Many previous methods treat the task of describing images as a retrieval task and formulate the problem as a ranking or embedding learning problem. They first extract the word and sentence features ( e.g. Socher et al.(2014) uses dependency tree Recursive Neural Network to extract sentence features ) as well as the image features. Then they optimize a ranking cost to learn an embedding model that maps both the sentence feature and the image feature to a common semantic feature space ( the same semantic space ). In this way, they can directly calculate the distance between images and sentences. These methods genarate image captions by retrieving them from a sentence database. Thus, they lack the ability of generating novel sentences or describing images that contain novel combinations of objects and scenes.
- Benchmark datasets for Image Captioning: IAPR TC-12 ( Grubinger et al.(2006) ), Flickr8K ( Rashtchian et al.(2010) ), Flickr30K ( Young et al.(2014) ) and MS COCO ( Lin et al.(2014) ).
- Evaluation Metrics for Sentence Generation: Sentence perplexity and BLUE scores.
- Tasks related to Image Captioning: Generating Novel Sentences, Retrieving Images Given a Sentence, Retrieving Sentences Given an Image.
- The m-RNN model is trained using Baidu's internal deep learning platform PADDLE.

