
Link of the Paper: https://ieeexplore.ieee.org/document/7298856/
A Correlative Paper: Learning a Recurrent Visual Representation for Image Caption Generation (Link of the Paper: https://arxiv.org/abs/1411.5654)
Main Points:
- A bi-directional mapping model using recurrent neural networks: unlike previous approaches which map both sentences and images to a common embedding ( and then calculate the similarity and match / generate, I guess ) that may be used for image search or for ranking image captions.
- A bi-directional representation: generates both novel descriptions from images and visual representations from descriptions.
- A novel recurrent visual memory: automatically learns to remember long-term visual concepts.
- A set of latent variables Ut-1 that encodes the visual interpretation of the previously generated or read words Wt-1. Using U, our goal is to compute P(wt | V, Wt-1, Ut-1) and P(V | Wt-1, Ut-1). Combining these two likelihoods together our global objective is to maximize, P(wt, V | Wt-1, Ut-1) = P(wt | V, Wt-1, Ut-1)P(V | Wt-1, Ut-1). That is, we want to maximize the likelihood of the word wt and the observed visual features V given the previous words and their visual interpretation. Note that in previous papers, the objective was only to compute P(wt | V, Wt-1) and not P(V | Wt-1).
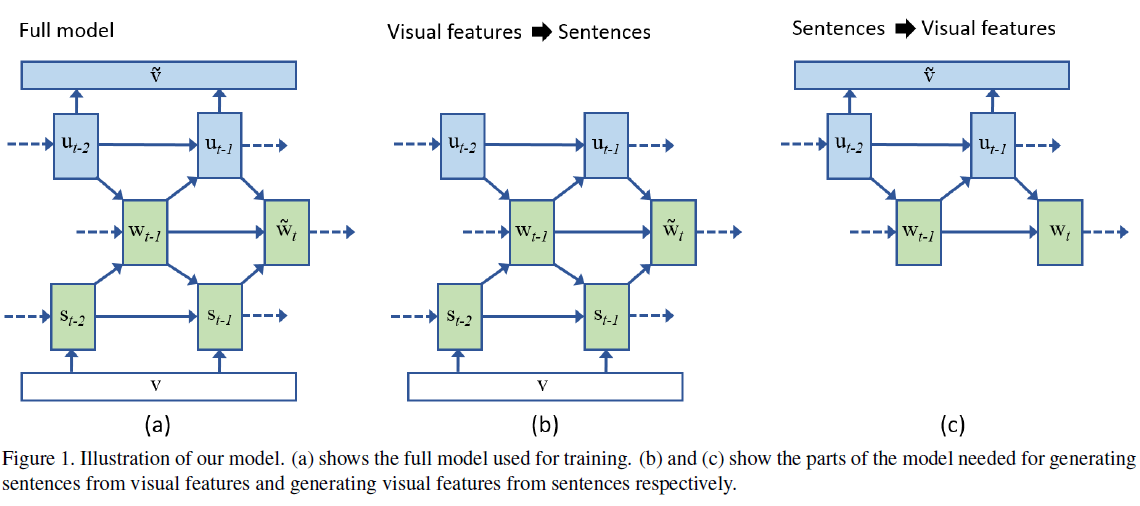
Other Key Points:
- Previous approaches project both semantics and visual features to a common embedding, they are not able to perform the inverse projection. That is, they cannot generate novel sentences or visual depictions from the embedding.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号