
Link of the Paper: http://papers.nips.cc/paper/4470-im2text-describing-images-using-1-million-captioned-photographs.pdf
Main Points:
- A large novel data set containing images from the web with associated captions written by people, filtered so that the descriptions are likely to refer to visual content.
- A description generation method that utilizes global image representations to retrieve and transfer captions from their data set to a query image: authors achieve this by computing the global similarity ( a sum of gist similarity and tiny image color similarity ) of a query image to their large web-collection of captioned images; they find the closest matching image ( or images ) and simply transfer over the description from the matching image to the query image.
- A description generation method that utilizes both global representations and direct estimates of image content (objects, actions, stuff, attributes, and scenes) to produce relevant image descriptions.
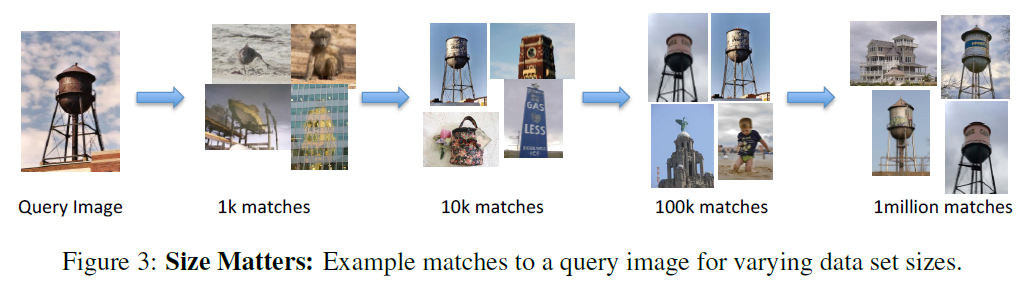
Other Key Points:
- Image captioning will help advance progress toward more complex human recognition goals, such as how to tell the story behind an image.
- An approach from Every picture tells a story: generating sentences for images produces image descriptions via a retrieval method, by translating both images and text descriptions to a shared meaning space represented by a single < object, action, scene > tuple. A description for a query image is produced by retrieving whole image descriptions via this meaning space from a set of image descriptions.
- The retrieval method relies on collecting and filtering a large data set of images from the internet to produce a novel web-scale captioned photo collection.
