
[Paper Reading] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
论文链接:https://arxiv.org/pdf/1502.03044.pdf
代码链接:https://github.com/kelvinxu/arctic-captions & https://github.com/yunjey/show-attend-and-tell & https://github.com/jazzsaxmafia/show_attend_and_tell.tensorflow
主要贡献
在这篇文章中,作者将“注意力机制(Attention Mechanism)”引入了神经机器翻译(Neural Image Captioning)领域,提出了两种不同的注意力机制:‘Soft’ Deterministic Attention Mechanism & ‘Hard’ Stochastic Attention Mechanism。下图展示了"Show, Attend and Tell"模型的整体框架。
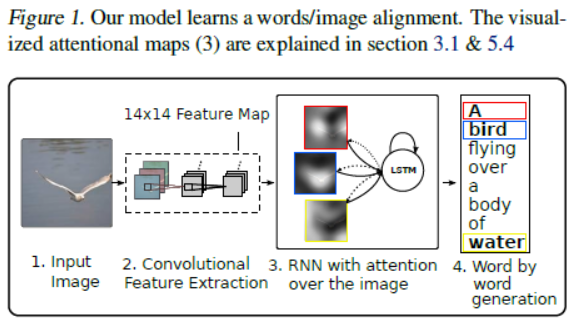
注意力机制的关键点在于,如何从图像的特征向量ai中计算得到上下文向量zt。对于每一个位置i,注意力机制能够产生一个权重eti。在Hard Attention机制中,权重αti所扮演的角色是图像区域向量ai在t时刻被选中作为解码器的信息的概率,有且只有一个区域会被选中,为此,引入变量st,i,当区域i被选中时为1,否则为0;在Soft Attention机制中,权重αti所扮演的角色是图像区域向量ai在t时刻输入解码器的信息中所占的比例。(参考Attention机制论文阅读——Soft和Hard Attention,Multimodal —— 看图说话(Image Caption)任务的论文笔记(二)引入attention机制)
实验细节
- 在文章中,作者提出使用在ImageNet数据集上预训练好、不进行微调的VGGNet提取图像特征,将block5_conv4(Conv2D)提取到的feature map(14×14×512)reshape为196×512(L×D,L=196,D=512,即196个图像区域,每个区域特征向量的维度是512)的图像区域向量ai。
To create the annotations ai used by our decoder, we used the Oxford VGGnet pretrained on ImageNet without finetuning.
In our experiments we use the 14×14×512 feature map of the fourth convolutional layer before max pooling. This means our decoder operates on the flattened 196×512 (i.e L × D) encoding.
- 在文章中,作者指出,解码器LSTM初始的细胞状态(init_c)与隐层状态(init_h)由从图像中提取到的特征向量及两个独立的多层感知机(Multi-Layer Perception, MLP)决定。
The initial memory state and hidden state of the LSTM are predicted by an average of the annotation vectors fed through two separate MLPs(init,c and init,h).
版权声明:本文为博主原创文章,欢迎转载,转载请注明作者及原文出处!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号