

python读取excel,数字都是浮点型,日期格式是数字的解决办法
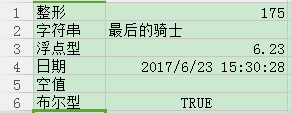
excel文件内容:
读取excel:
# coding=utf-8 import xlrd import sys reload(sys) sys.setdefaultencoding('utf-8') import traceback class excelHandle: def decode(self, filename, sheetname): try: filename = filename.decode('utf-8') sheetname = sheetname.decode('utf-8') except Exception: traceback.print_exc() return filename, sheetname def read_excel(self, filename, sheetname): filename, sheetname = self.decode(filename, sheetname) rbook = xlrd.open_workbook(filename) sheet = rbook.sheet_by_name(sheetname) rows = sheet.nrows cols = sheet.ncols all_content = [] for i in range(rows): row_content = [] for j in range(cols): cell = sheet.cell_value(i, j) row_content.append(cell) all_content.append(row_content) print('[' + ','.join("'" + str(element) + "'" for element in row_content) + ']') return all_content if __name__ == '__main__': eh = excelHandle() filename = r'G:\test\ctype.xls' sheetname = 'Sheet1' eh.read_excel(filename, sheetname)
输出:
['整形','175.0'] ['字符串','最后的骑士'] ['浮点型','6.23'] ['日期','42909.6461574'] ['空值',''] ['布尔型','1']
可以看到,数字一律按浮点型输出,日期却输出成一串小数?!布尔型输出0或1
代码稍做改动:来看一看表格的数据类型
for i in range(rows): row_content = [] for j in range(cols): ctype = sheet.cell(i, j).ctype #表格的数据类型 print(ctype) cell = sheet.cell_value(i, j) row_content.append(cell) all_content.append(row_content) print('[' + ','.join("'" + str(element) + "'" for element in row_content) + ']')
1 2 ['整形','175.0'] 1 1 ['字符串','最后的骑士'] 1 2 ['浮点型','6.23'] 1 3 ['日期','42909.6461574'] 1 0 ['空值',''] 1 4 ['布尔型','1']
python读取excel中单元格的内容返回的有5种类型,即上面例子中的ctype:
ctype: 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
所以,判断一下ctype,然后再做相应处理就可以了。
