hadoop streaming anaconda python 计算平均值
原始Liunx 的python版本不带numpy ,安装了anaconda 之后,使用hadoop streaming 时无法调用anaconda python ,
后来发现是参数没设置好。。。
进入正题:
环境:
4台服务器:master slave1 slave2 slave3。
全部安装anaconda2与anaconda3, 主环境py2 。anaconda2与anaconda3共存见:Ubuntu16.04 Liunx下同时安装Anaconda2与Anaconda3
安装目录:/home/orient/anaconda2
Hadoop 版本2.4.0
数学原理:
设有一组数字,这组数字的均值和方差如下:
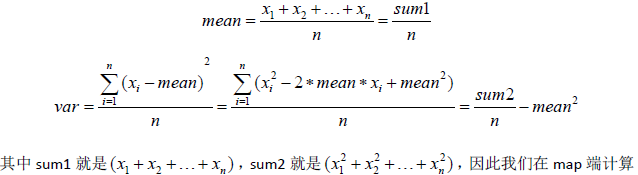
每个部分的{count(元素个数)、sum1/count、sum2/count},然后在reduce端将所有map端传入的sum1加起来在除以总个数n得到均值mean;将所有的sum2加起来除以n再减去均值mean的平方,就得到了方差var.
数据准备:
inputFile.txt 一共100个数字 全部数据 下载:
0.970413
0.901817
0.828698
0.197744
0.466887
0.962147
0.187294
0.388509
0.243889
0.115732
0.616292
0.713436
0.761446
0.944123
0.200903
编写mrMeanMapper.py
1 #!/usr/bin/env python
2 import sys
3 from numpy import mat, mean, power
4
5 def read_input(file):
6 for line in file:
7 yield line.rstrip()
8
9 input = read_input(sys.stdin)#creates a list of input lines
10 input = [float(line) for line in input] #overwrite with floats
11 numInputs = len(input)
12 input = mat(input)
13 sqInput = power(input,2)
14
15 #output size, mean, mean(square values)
16 print "%d\t%f\t%f" % (numInputs, mean(input), mean(sqInput)) #calc mean of columns
17 print >> sys.stderr, "report: still alive"
编写mrMeanReducer.py
1 #!/usr/bin/env python
2 import sys
3 from numpy import mat, mean, power
4
5 def read_input(file):
6 for line in file:
7 yield line.rstrip()
8
9 input = read_input(sys.stdin)#creates a list of input lines
10
11 #split input lines into separate items and store in list of lists
12 mapperOut = [line.split('\t') for line in input]
13
14 #accumulate total number of samples, overall sum and overall sum sq
15 cumVal=0.0
16 cumSumSq=0.0
17 cumN=0.0
18 for instance in mapperOut:
19 nj = float(instance[0])
20 cumN += nj
21 cumVal += nj*float(instance[1])
22 cumSumSq += nj*float(instance[2])
23
24 #calculate means
25 mean = cumVal/cumN
26 meanSq = cumSumSq/cumN
27
28 #output size, mean, mean(square values)
29 print "%d\t%f\t%f" % (cumN, mean, meanSq)
30 print >> sys.stderr, "report: still alive"
本地测试mrMeanMapper.py ,mrMeanReducer.py
cat inputFile.txt |python mrMeanMapper.py |python mrMeanReducer.py

我把 inputFile.txt,mrMeanMapper.py ,mrMeanReducer.py都放在了同一目录下 ~/zhangle/Ch15/hh/hh
所有的操作也都是这此目录下!!!
将inputFile.txt上传到hdfs
zhangle/mrmean-i 是HDFS上的目录
hadoop fs -put inputFile.txt zhangle/mrmean-i
运行Hadoop streaming
1 hadoop jar /usr/programs/hadoop-2.4.0/share/hadoop/tools/lib/hadoop-streaming-2.4.0.jar \
2 -input zhangle/mrmean-i \
3 -output zhangle/output12222 \
4 -file mrMeanMapper.py \
5 -file mrMeanReducer.py \
6 -mapper "/home/orient/anaconda2/bin/python mrMeanMapper.py" \
7 -reducer "/home/orient/anaconda2/bin/python mrMeanReducer.py"
参数解释:
第一行:/usr/programs/hadoop-2.4.0/share/hadoop/tools/lib/hadoop-streaming-2.4.0.jar 是我Hadoop streaming 所在的目录
第二行: zhangle/mrmean-i 是刚才将inputFile.txt 上传的目录
第三行:zhangle/mrmean-out12222 是结果输出目录,也是在HDFS上
第四行: mrMeanMapper.py是当前目录下的mapper程序
第五行: mrMeanRdeducer.py是当前目录下的reducer程序
第六行: /home/orient/anaconda2/bin/python 是anaconda2目录下的python ,如果去掉,会直接调用自带的python,自带python没有安装numpy等python包。!!
第七行: 同第六行。
查看运行结果:
hadoop fs -cat zhangle/output12222/part-00000

问题解决
1. 出现“Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1”的错误
解决方法:
在hadoop上实施MapReduce之前,一定要在本地运行一下你的python程序,看
-
首先进入包含map和reduce两个py脚本文件和数据文件inputFile.txt的文件夹中。然后输入一下命令,看是否执行通过:
-
cat inputFile.txt |python mrMeanMapper.py |python mrMeanReducer.py
2.出现错误:“Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 2”,或者出现jar文件找不到的情况,或者出现输出文件夹已经存在的情况。
- Mapper.py和Reduce.py的最前面要加上:#!/usr/bin/env python 这条语句
- 在Hadoop Streaming命令中,请确保按以下的格式来输入
-
1 hadoop jar /usr/programs/hadoop-2.4.0/share/hadoop/tools/lib/hadoop-streaming-2.4.0.jar \ 2 -input zhangle/mrmean-i \ 3 -output zhangle/output12222 \ 4 -file mrMeanMapper.py \ 5 -file mrMeanReducer.py \ 6 -mapper "/home/orient/anaconda2/bin/python mrMeanMapper.py" \ 7 -reducer "/home/orient/anaconda2/bin/python mrMeanReducer.py" - 要确保jar文件的路径正确,hadoop 2.4版本的该文件是保存在:$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.4.0.jar中,不同的hadoop版本可能略有不同HDFS中的输出文件夹(这里是HDFS下的/user/hadoop/mr-ouput13),一定要是一个新的(之前不存在)的文件夹,因为即使上条Hadoop Streaming命令没有执行成功,仍然会根据你的命令来创建输出文件夹,而后面再输入Hadoop Streaming命令如果使用相同的输出文件夹时,就会出现“输出文件夹已经存在的错误”;参数 –file后面是map和reduce的脚本,路径可以是详细的绝对路径,,也可以是当前路径,当前路径下一定要有mapper,reducer 函数,但是在参数 -mapper 和-reducer之后,需要指定python脚本的环境目录,而且用引号引起来。
3.出现错误:“Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 127”.
脚本环境的问题 在第六行与第七行 加上python 环境目录即可。
参考:
http://www.cnblogs.com/lzllovesyl/p/5286793.html
http://www.zhaizhouwei.cn/hadoop/190.html
http://blog.csdn.net/wangzhiqing3/article/details/8633208

 浙公网安备 33010602011771号
浙公网安备 33010602011771号