gpt bert
Transformer 的结构
标准的 Transformer 模型主要由两个模块构成:
- Encoder(左边):负责理解输入文本,为每个输入构造对应的语义表示(语义特征),;
- Decoder(右边):负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列。

这两个模块可以根据任务的需求而单独使用:
- 纯 Encoder 模型:适用于只需要理解输入语义的任务,例如句子分类和命名实体识别;
- 纯 Decoder 模型:适用于生成式任务,例如文本生成;
- Encoder-Decoder 模型或 Seq2Seq 模型:适用于需要基于输入的生成式任务,例如翻译和摘要。
Transformer 家族
随着时间的推移,新的 Transformer 模型层出不穷,但是它们依然可以被归类到三种主要架构下:

Encoder 分支
纯 Encoder 模型只使用 Transformer 模型中的 Encoder 模块,也被称为自编码 (auto-encoding) 模型。在每个阶段,注意力层都可以访问到原始输入句子中的所有词语,即具有“双向 (Bi-directional)”注意力。纯 Encoder 模型通常通过破坏给定的句子(例如随机遮盖其中的单词),然后让模型进行重构来进行预训练,最适合处理那些需要理解整个句子语义的任务,例如句子分类、命名实体识别(词语分类)和抽取式问答。
BERT 是第一个基于 Transformer 结构的纯 Encoder 模型,它在提出时横扫了整个 NLP 界,在流行的 GLUE 基准(通过多个任务度量模型的自然语言理解能力)上超过了当时所有的最强模型。随后的一系列工作对 BERT 的预训练目标和架构进行调整以进一步提高性能。时至今日,纯 Encoder 模型依然在 NLP 行业中占据主导地位。
下面我们简略地介绍一下 BERT 模型以及各种变体:
- BERT:通过预测文本中被掩码的词语和判断一个文本是否跟随着另一个来进行预训练,前一个任务被称为遮盖语言建模 (Masked Language Modeling, MLM),后一个任务被称为下一句预测 (Next Sentence Prediction, NSP);
- DistilBERT:尽管 BERT 模型性能优异,但它的模型大小使其难以部署在低延迟需求的环境中。 通过在预训练期间使用知识蒸馏 (knowledge distillation) 技术,DistilBERT 在内存占用减少 40%、计算速度提高 60% 的情况下,依然可以保持 BERT 模型 97% 的性能;
- RoBERTa:BERT 之后的一项研究表明,通过修改预训练方案可以进一步提高性能。 RoBERTa 在更多的训练数据上,以更大的批次训练了更长的时间,并且放弃了 NSP 任务。与 BERT 模型相比,这些改变显著地提高了模型的性能;
- XLM:跨语言语言模型 (XLM) 探索了构建多语言模型的数个预训练目标,包括来自 GPT 模型的自回归语言建模和来自 BERT 的 MLM。此外,研究者还通过将 MLM 任务拓展到多语言输入,提出了翻译语言建模 (Translation Language Modeling, TLM)。XLM 模型基于这些任务进行预训练后,在数个多语言 NLU 基准和翻译任务上取得了最好的性能;
- XLM-RoBERTa:跟随 XLM 和 RoBERTa 的工作,XLM-RoBERTa (XLM-R) 模型通过升级训练数据使得多语言预训练更进一步。具体地,首先基于 Common Crawl 语料库创建了一个包含 2.5 TB 文本数据的语料,然后在该数据集上运用 MLM 训练了一个编码器。由于数据集没有包含平行对照文本,因此移除了 XLM 的 TLM 目标。最终,该模型大幅超越了 XLM 和多语言 BERT 变体;
- ALBERT:ALBERT 模型通过三处变化使得 Encoder 架构更高效:首先,它将词嵌入维度与隐藏维度解耦,使得嵌入维度很小以减少模型参数;其次,所有模型层共享参数,这进一步减少了模型的实际参数量;最后,将 NSP 任务替换为句子排序预测,即预测两个连续句子的顺序是否被交换。这些变化使得可以用更少的参数训练更大的模型,并在 NLU 任务上取得了优异的性能;
- ELECTRA:标准 MLM 预训练的一个缺陷是,在每个训练步骤中,只有被遮盖掉词语的表示会得到更新。ELECTRA 使用了一种双模型方法来解决这个问题:第一个模型(通常很小)继续按标准的遮盖语言模型一样工作,预测被遮盖的词语;第二个模型(称为鉴别器)则预测第一个模型的输出中哪些词语是被遮盖的,因此判别器需要对每个词语进行二分类,这使得训练效率提高了 30 倍。对于下游任务,鉴别器也像标准 BERT 模型一样进行微调;
- DeBERTa:DeBERTa 模型引入了两处架构变化。首先,每个词语都被表示为两个向量,一个用于记录内容,另一个用于记录相对位置。通过将词语的内容与相对位置分离,自注意力层 (Self-Attention) 层就可以更好地建模邻近词语对的依赖关系。另一方面,词语的绝对位置也很重要(尤其对于解码),因此 DeBERTa 在词语解码头的 softmax 层之前添加了一个绝对位置嵌入。DeBERTa 是第一个在 SuperGLUE 基准(更困难的 GLUE 版本)上击败人类基准的模型。
Decoder 分支
纯 Decoder 模型只使用 Transformer 模型中的 Decoder 模块。在每个阶段,对于某个给定的词语,注意力层只能访问句子中位于它之前的词语,即只能迭代地基于已经生成的词语来逐个预测后面的词语,因此也被称为自回归 (auto-regressive) 模型。纯 Decoder 模型的预训练通常围绕着预测句子中下一个单词展开。纯 Decoder 模型最适合处理那些只涉及文本生成的任务。
对 Transformer Decoder 模型的探索在在很大程度上是由 OpenAI 带头进行的,通过使用更大的数据集进行预训练,以及将模型的规模扩大,纯 Decoder 模型的性能也在不断提高。
下面我们就来简要介绍一下一些生成模型的演变:
- GPT:GPT 结合了新颖高效的 Transformer Decoder 架构和迁移学习,通过根据前面单词预测下一个单词的预训练任务,在 BookCorpus 数据集上进行了训练。GPT 模型在分类等下游任务上取得了很好的效果。
- GPT-2:受简单且可扩展的预训练方法的启发,OpenAI 通过扩大原始模型和训练集创造了 GPT-2,它能够生成篇幅较长且语义连贯的文本。由于担心被误用,该模型分阶段进行发布,首先公布了较小的模型,然后发布了完整的模型。
- CTRL:像 GPT-2 这样的模型虽然可以续写文本(也称为 prompt),但是用户几乎无法控制生成序列的风格。因此,条件 Transformer 语言模型 (Conditional Transformer Language, CTRL) 通过在序列开头添加特殊的“控制符”使得用户可以控制生成文本的风格,并且只需要调整控制符就可以生成多样化的文本。
- GPT-3:在成功将 GPT 扩展到 GPT-2 之后,通过对不同规模语言模型行为的分析表明,存在幂律来约束计算、数据集大小、模型大小和语言模型性能之间的关系。因此,GPT-2 被进一步放大 100 倍,产生了具有 1750 亿个参数的 GPT-3。除了能够生成令人印象深刻的真实篇章之外,该模型还展示了小样本学习 (few-shot learning) 的能力:只需要给出很少新任务的样本(例如将文本转换为代码),GPT-3 就能够在未见过的新样本上完成任务。但是 OpenAI 并没有开源这个模型,而是通过 OpenAI API 提供了调用接口;
- GPT-Neo / GPT-J-6B:由于 GPT-3 没有开源,因此一些旨在重新创建和发布 GPT-3 规模模型的研究人员组成了 EleutherAI,GPT-Neo 和 GPT-J-6B 就是由 EleutherAI 训练的类似 GPT 的模型。当前公布的模型具有 1.3、2.7 和 60 亿个参数,在性能上可以媲美 OpenAI 提供的较小版本的 GPT-3 模型。
Encoder-Decoder 分支
Encoder-Decoder 模型(又称 Seq2Seq 模型)同时使用 Transformer 架构的两个模块。在每个阶段,Encoder 的注意力层都可以访问初始输入句子中的所有单词,而 Decoder 的注意力层则只能访问输入中给定词语之前的词语(已经解码生成的词语)。这些模型可以使用编码器或解码器模型的目标来完成预训练,但通常会包含一些更复杂的任务。例如,T5 通过使用 mask 字符随机遮盖掉输入中的文本片段(包含多个词)进行预训练,训练目标则是预测出被遮盖掉的文本。Encoder-Decoder 模型最适合处理那些需要根据给定输入来生成新句子的任务,例如自动摘要、翻译或生成式问答。
下面我们简单介绍一些在自然语言理解 (NLU) 和自然语言生成 (NLG) 领域的 Encoder-Decoder 模型:
- T5:T5 模型将所有 NLU 和 NLG 任务都转换为文本到文本任务来统一解决,这样就可以运用 Encoder-Decoder 框架来完成任务。例如,对于文本分类问题,将文本作为输入送入 Encoder,然后 Decoder 生成文本形式的标签。T5 采用原始的 Transformer 架构,在 C4 大型爬取数据集上,通过遮盖语言建模以及将所有 SuperGLUE 任务转换为文本到文本任务来进行预训练。最终,具有 110 亿个参数的最大版本 T5 模型在多个基准上取得了最优性能。
- BART:BART 在 Encoder-Decoder 架构中结合了 BERT 和 GPT 的预训练过程。首先将输入句子通过遮盖词语、打乱句子顺序、删除词语、文档旋转等方式进行破坏,然后通过 Encoder 编码后传递给 Decoder,并且要求 Decoder 能够重构出原始的文本。这使得模型可以灵活地用于 NLU 或 NLG 任务,并且在两者上都实现了最优性能。
- M2M-100:一般翻译模型是按照特定的语言对和翻译方向来构建的,因此无法用于处理多语言。事实上,语言对之间可能存在共享知识,这可以用来处理稀有语言之间的翻译。M2M-100 是第一个可以在 100 种语言之间进行翻译的模型,并且对小众的语言也能生成高质量的翻译。该模型使用特殊的前缀标记(类似于 BERT 的
[CLS])来指示源语言和目标语言。 - BigBird:由于注意力机制 O(n2)�(�2) 的内存要求,Transformer 模型只能处理一定长度范围内的文本。 BigBird 通过使用线性扩展的稀疏注意力形式解决了这个问题,从而将可处理的文本长度从大多数 BERT 模型的 512 大幅扩展到 4096,这对于处理文本摘要等需要保存长距离依赖关系的任务特别有用。
GPT (Unsupervised-Pretrain + Finetune)
1 摘要
论文地址:Improving Language Understandingby Generative Pre-Training
2 方法
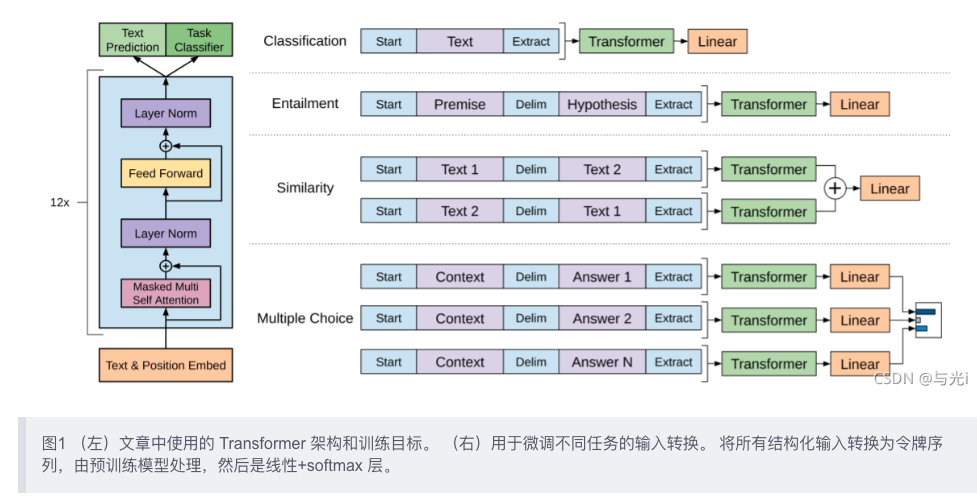
GPT 采用两阶段过程,第一个阶段是利用语言模型进行预训练(无监督形式),第二阶段通过 Fine-tuning 的模式解决下游任务(监督模式下)。模型的结构如图1。
- 自然语言推理(Natural Language Inference 或者 Textual Entailment):判断两个句子是包含关系(entailment),矛盾关系(contradiction),或者中立关系(neutral);
- 问答和常识推理(Question answering and commonsense reasoning):类似于多选题,输入一个文章,一个问题以及若干个候选答案,输出为每个答案的预测概率;
- 语义相似度(Semantic Similarity):判断两个句子是否语义上市是相关的;
- 分类(Classification):判断输入文本是指定的哪个类别。
2.1 非监督预训练

2.2 监督微调

-----BERT------
BERT 的预训练过程由两个阶段组成,分别是掩码语言模型和下一句预测任务。其中,掩码语言模型与 GPT-1 类似,也是通过随机掩盖输入序列中的一些词,然后让模型预测这些被掩盖的词。下一句预测任务则是要求模型在给定两个句子的情况下,判断这两个句子是否是连续的。这两个任务的结合使得 BERT 可以学习到更丰富的语言表示,从而可以在多个自然语言处理任务上进行微调。
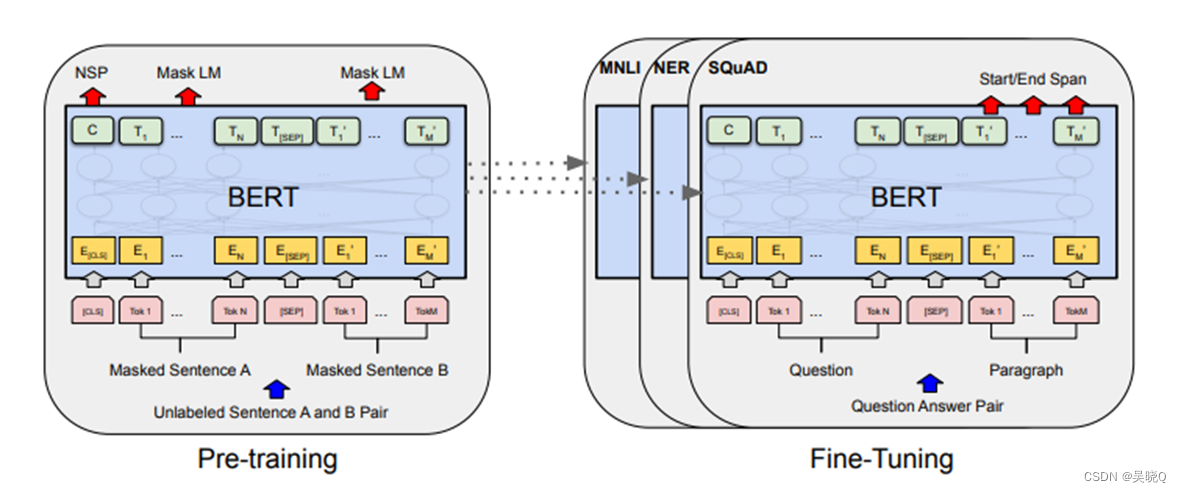
• BERT 的结构也类似于 Transformer ,但与 GPT-1 不同的是, BERT 采用了双向编码器。这意味着在处理输入序列时, BERT 可以同时考虑每个词前后的上下文信息。此外, BERT 还引入了一个特殊的 [CLS] 标记,用于表示整个输入序列的语义信息。这个标记在下游任务中可以用于分类和回归等任务。
• BERT 的表现已经在多个自然语言处理任务上进行了测试,包括文本分类、问答系统、命名实体识别等。结果表明, BERT 在多个任务上都取得了优秀的表现,并且在一些任务上超过了人类水平。 BERT 的发布被认为是自然语言处理领域的一次里程碑,它的成功也推动了后续更高级别的预训练语言模型的发展。
GPT与BERT
GPT和BERT都是基于神经网络的自然语言处理模型,但它们有以下不同点:
-
架构:GPT是一个生成式语言模型,它使用Transformer架构,只使用单向上下文进行预测;而BERT是一个双向的语言表示模型,也使用Transformer架构,使用双向上下文对输入文本进行编码。
-
预训练任务:GPT使用了一个语言建模任务来预训练参数,即如果给定前面的文本,预测下一个单词是什么;而BERT则使用了两个任务:掩码语言模型任务和下一句预测任务。掩码语言模型任务需要模型预测被遮挡了的词是什么,下一句预测任务要求模型判断两个句子是否连续。
-
目标:GPT旨在生成连贯的文本,如文章和故事,而BERT的目标是学习语言表示,让模型能够适应各种自然语言处理任务。
-
建模方式:GPT大多数情况下使用单向上下文来预测下一个单词,这使得GPT有很好的生成能力,能够连续生成文本;而BERT在处理双向上下文时需要采用特别的预训练方式,以避免模型知道未来的信息
每次提到ELMO、GPT、BERT的区别,最常见的就是下图:
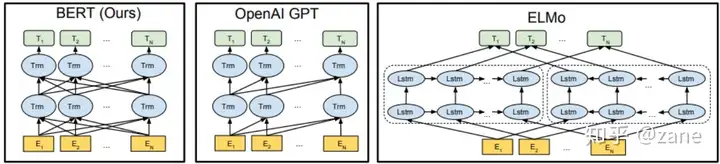
GPT与BERT区别:
BERT是基于Transformer的Encoder构建的,而GPT是基于Transformer的Decoder构建的。这就导致GPT类似于传统的语言模型,即一次只输出一个单词进行序列预测,也就是下一词预测。因为Decoder部分与RNN思想还是比较类似的,尤其是其中Masked attention部分,能够屏蔽来自未来的信息,因此GPT是单向的模型,无法考虑语境的下文。
BERT基于Encoder,可以很好地考虑上下文信息,这样预训练任务就从下一词预测自然而然地转换成了结合了前后语义的单词预测。因此BERT改变了预训练的方式,即采用MLM和NSP两种任务进行训练。因为Encoder得到的是每个输入单词对应的向量,因此将单词缺失位置对应的输出向量投入一个线性分类器即可预测。
GPT进行的是单向语言模型的训练,而Bert想要构造一个深层双向语言模型,以你为在直觉上深层的双向模型大概率会由于传统的“前向”模型(比如GPT)或者“前向 拼接 后向”的模型(比如ELMO),而且能更好地同时考虑上下文的信息进行预测,从而学到更好的预训练语言模型。
gpt2

https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
https://blog.csdn.net/u012526436/article/details/87882985
https://zhuanlan.zhihu.com/p/527783286
gpt-3
3. GPT-3:海量参数
截止编写此文前,GPT-3是目前最强大的语言模型,仅仅需要zero-shot或者few-shot,GPT-3就可以在下游任务表现的非常好。除了几个常见的NLP任务,GPT-3还在很多非常困难的任务上也有惊艳的表现,例如撰写人类难以判别的文章,甚至编写SQL查询语句,React或者JavaScript代码等。而这些强大能力的能力则依赖于GPT-3疯狂的
亿的参数量,
TB的训练数据以及高达
万美元的训练费用。
3.1 In-context learning
In-context learning是这篇论文中介绍的一个重要概念,要理解in-context learning,我们需要先理解meta-learning(元学习)[9, 10]。对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解。元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
这里的介绍使用的是MAML(Model-Agnostic Meta-Learning)算法[10],正常的监督学习是将一个批次的数据打包成一个batch进行学习。但是元学习是将一个个任务打包成batch,每个batch分为支持集(support set)和质询集(query set),类似于学习任务中的训练集和测试集。

图3:meta-learning的伪代码
对一个网络模型
,其参数表示为
,它的初始化值被叫做meta-initialization。MAML的目标则是学习一组meta-initialization,能够快速应用到其它任务中。MAML的迭代涉及两次参数更新,分别是内循环(inner loop)和外循环(outer loop)。内循环是根据任务标签快速的对具体的任务进行学习和适应,而外学习则是对meta-initialization进行更新。直观的理解,我用一组meta-initialization去学习多个任务,如果每个任务都学得比较好,则说明这组meta-initialization是一个不错的初始化值,否则我们就去对这组值进行更新,如图4所示。目前的实验结果表明元学习距离学习一个通用的词向量模型还是有很多工作要做的。
图4:meta-learning的可视化结果
而GPT-3中据介绍的in-context learning(情境学习)则是元学习的内循环,而基于语言模型的SGT则是外循环,如图5所示。
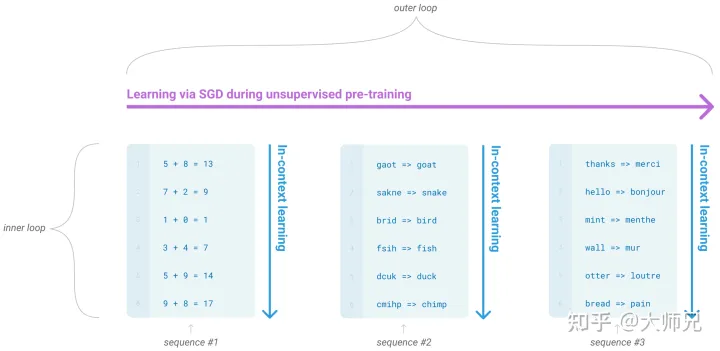
图5:GPT-3中的内循环和外循环
而另外一个方向则是提供容量足够大的transformer模型来对语言模型进行建模。而近年来使用大规模的网络来训练语言模型也成为了非常行之有效的策略(图6),这也促使GPT-3一口气将模型参数提高到
亿个。
从理论上讲GPT-3也是支持fine-tuning的,但是fine-tuning需要利用海量的标注数据进行训练才能获得比较好的效果,但是这样也会造成对其它未训练过的任务上表现差,所以GPT-3并没有尝试fine-tuning。
https://zhuanlan.zhihu.com/p/527825405
https://zhuanlan.zhihu.com/p/350017443

 浙公网安备 33010602011771号
浙公网安备 33010602011771号