


Seq2Seq ---学习笔记
应用场景:机器翻译
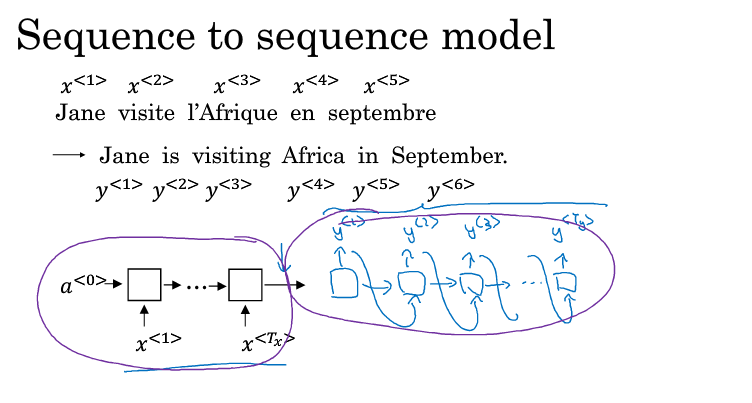
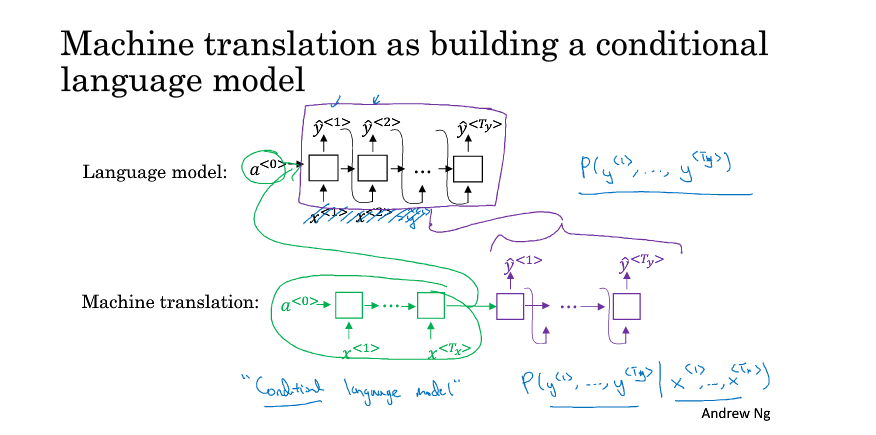
与language model 不同
MT model 的a<0> 是由encoder 生成的。
language model 的 a<0> 是 初始化的。
greedy search
为什么不用 greedy search ?
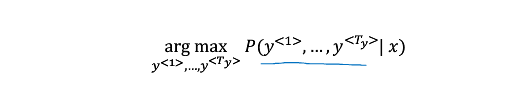

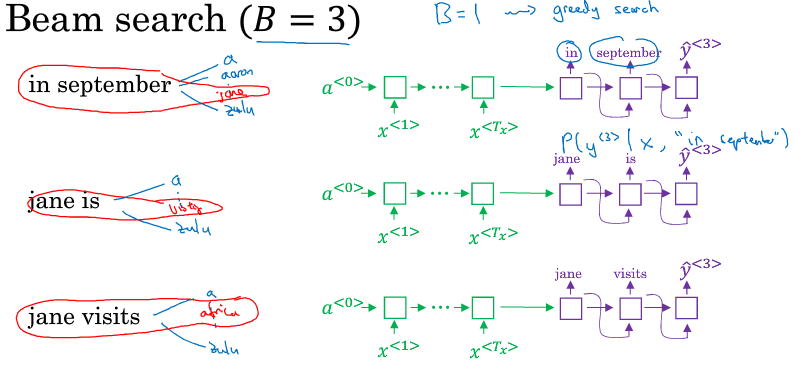
Beam Search
B=3 的意思是,每次greedy search 选出3个词,然后在根据当前3个词,分别生成下一个词,下一个词也生成3个 循环下去。
Beam Search 改进
都是概率,很小的概率相乘,值更小,很多0的,影响精度,不如取个log,
取完log 还有一个问题,这样单纯的概率相乘是倾向于生成短句子的。
因为短句子的概率是最大的。单词越多 概率越小。
所以归一化 ,除以tg的a次方
当a==0 :其实是没有归一化的。
a==1:完全取决于长度。
a 是一个超参数。

beam search 虽然快,但是不能保证结果是正确(概率最大)的。

Beam search 的误差
我们通过分析,要判断是rnn encoder 的误差 还是 beam search 的误差,从而决定如如何去改进。
rnn 产生的误差,我们就改善网络。
beam search 的误差,我们可以加大B.


