强化学习--DeepQnetwork 的一些改进
Double DQN
算Q值 与选Q值是分开的,2个网络。

Multi-step

Dueling DQN

如果更新了,即使有的action没有被采样到,也会更新Q值

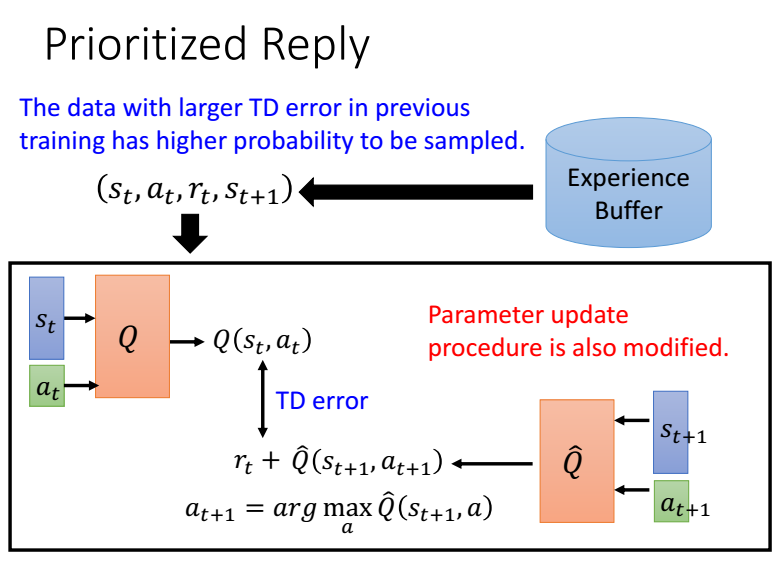
Prioritized Reply
Noisy Net
Epsilon Greedy 存在的问题是在一局游戏中,
即使是同一个agent也有可能坐车不不同的选择,这是不合理的,
所以在一局游戏中, 我们使用同一个q网络,在不回的回合给q网络
加入noise保证探索性。



算Q值 与选Q值是分开的,2个网络。
如果更新了,即使有的action没有被采样到,也会更新Q值
Epsilon Greedy 存在的问题是在一局游戏中,
即使是同一个agent也有可能坐车不不同的选择,这是不合理的,
所以在一局游戏中, 我们使用同一个q网络,在不回的回合给q网络
加入noise保证探索性。

