Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
Hadoop综合大作业 要求:
1.将爬虫大作业产生的csv文件上传到HDFS
2.对CSV文件进行预处理生成无标题文本文件
3.把hdfs中的文本文件最终导入到数据仓库Hive中
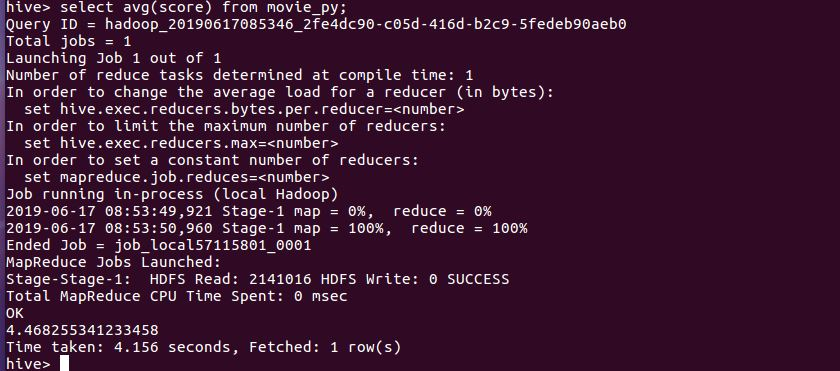
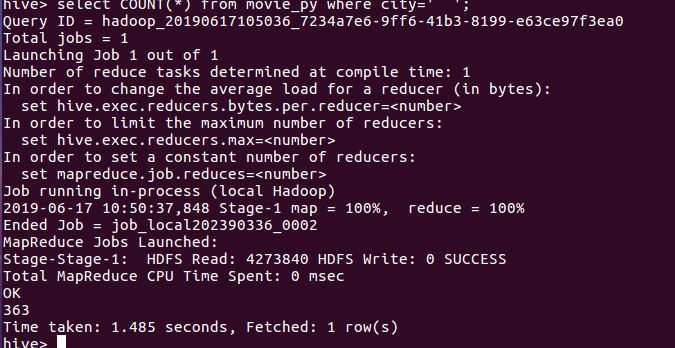
4.在Hive中查看并分析数据
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
数据预处理:
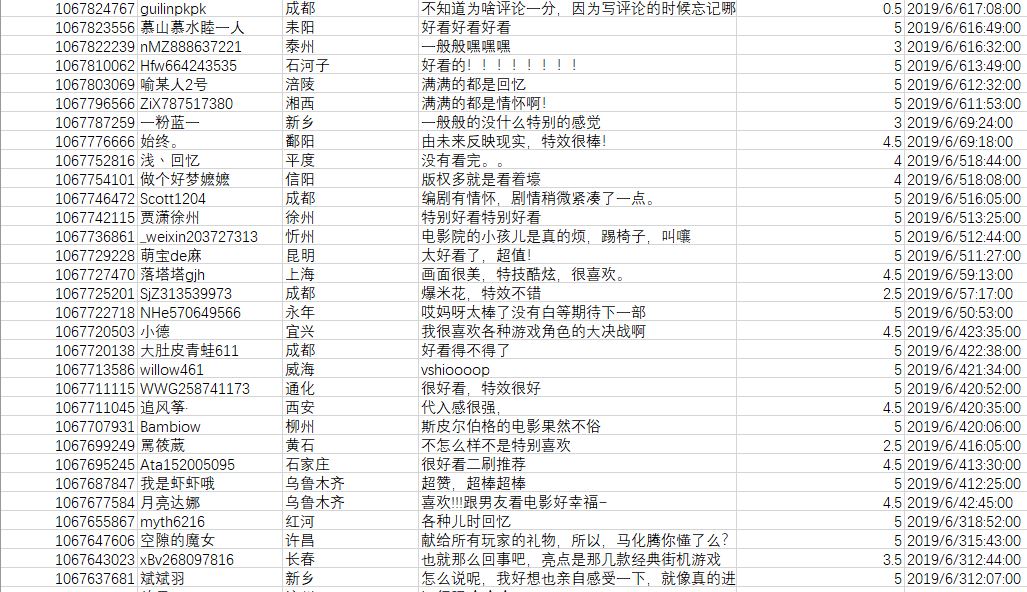
对爬取的CSV文件进行处理和清洗,删除空白和没用的数据
清理重复的数据和无效数据
大数据分析:
1.将爬虫大作业产生的csv文件上传到HDFS
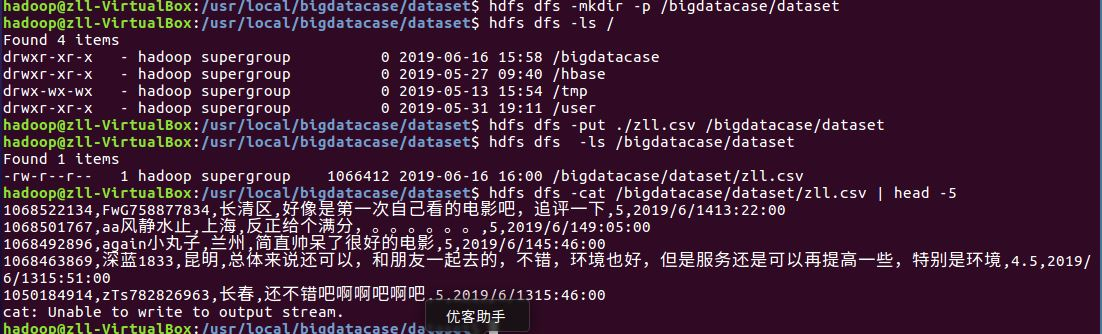
先用命令创建文件夹,并且将CSV文件复制粘贴到新建的文件夹中
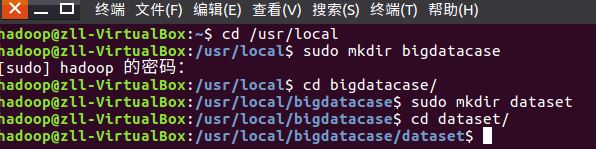
查看文件前5条信息,检查是否上传成功

2.对CSV文件进行预处理生成无标题文本文件
因为我爬取数据时并没有设置标题,前面对数据进行过处理,所以可以直接跳过这步。
3.把hdfs中的文本文件最终导入到数据仓库Hive中
想要把数据导入到数据库Hive中,首先要通过命令把服务全部开启
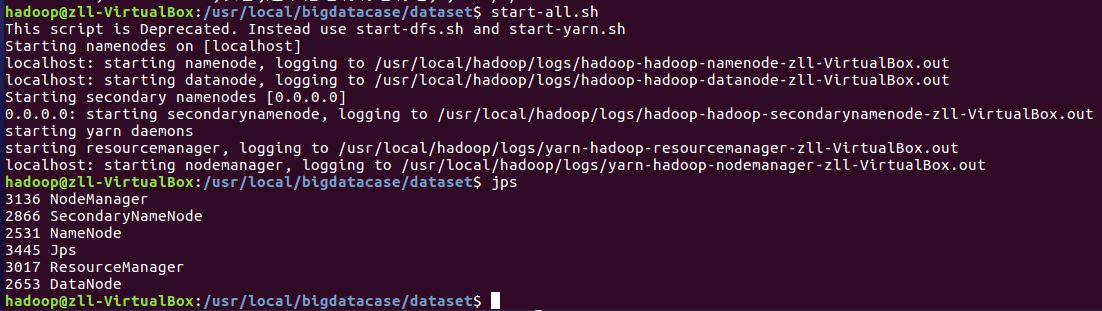
然后把CSV文件导入到数据仓库Hive中,并在Hive中查看并分析数据

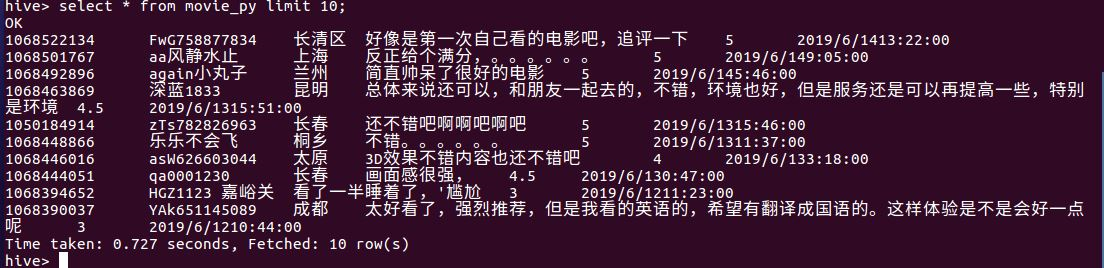
查看数据表是否正常
4.用Hive对爬虫大作业产生的进行数据分析
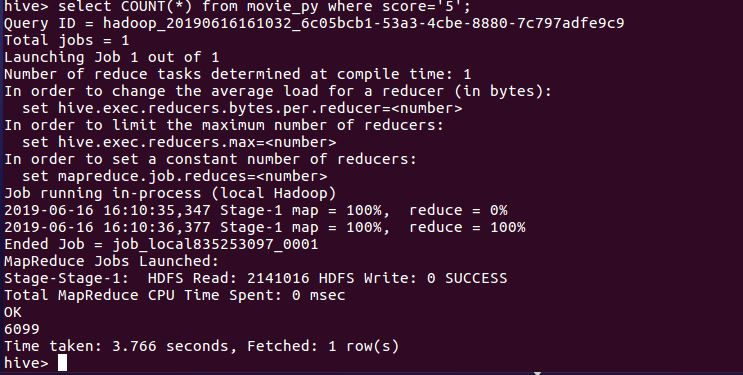
5分评分数
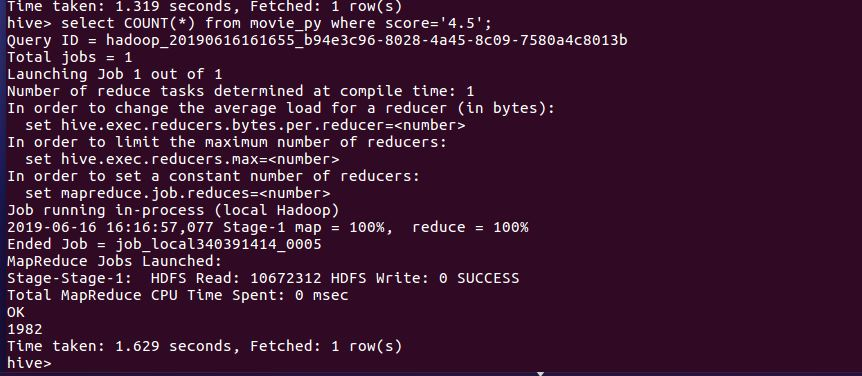
4.5分评分数
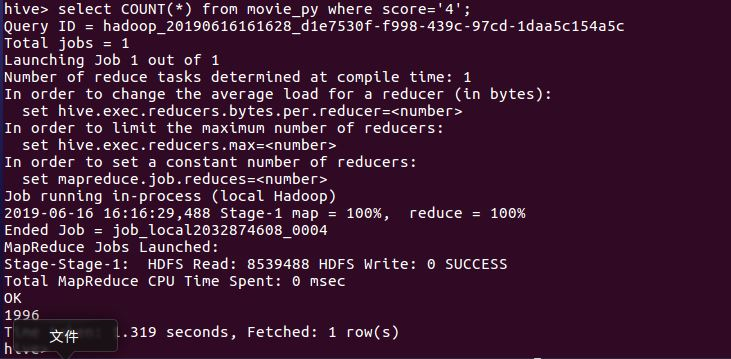
4分评分数
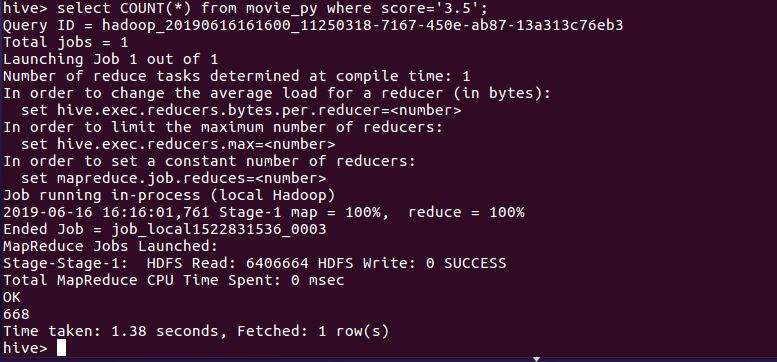
3.5分评分数
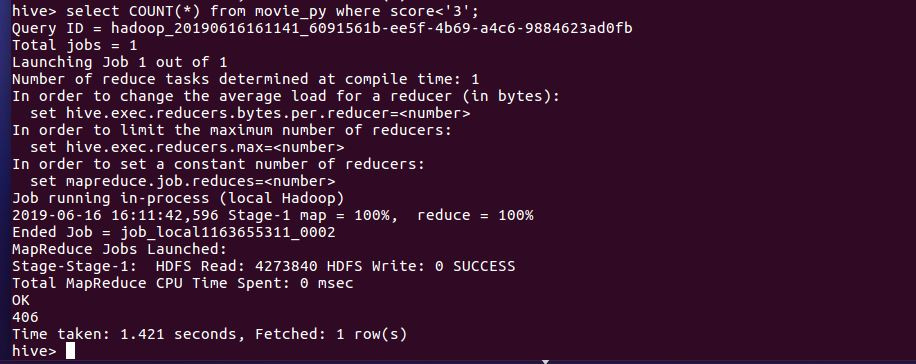
评分小于3分的数量
这次爬取的数据一共11604条,其中给满分好评的有6099条,占总数的52.7%;其中4.5分的有1982条,占17.1%;其中4分的有1996,占17.2%,给3分以下的仅仅只有3.8%,去除一些恶意的差评,将小于3分的人数与5分人数抵消,给满分的用户还有一半。
如果以4分以上作为好评,二这部电影的好评数高达87%,按照现今的电影情况,能有如此高的好评确实不多。
这足以说明这部电影口碑极好,深受喜欢。
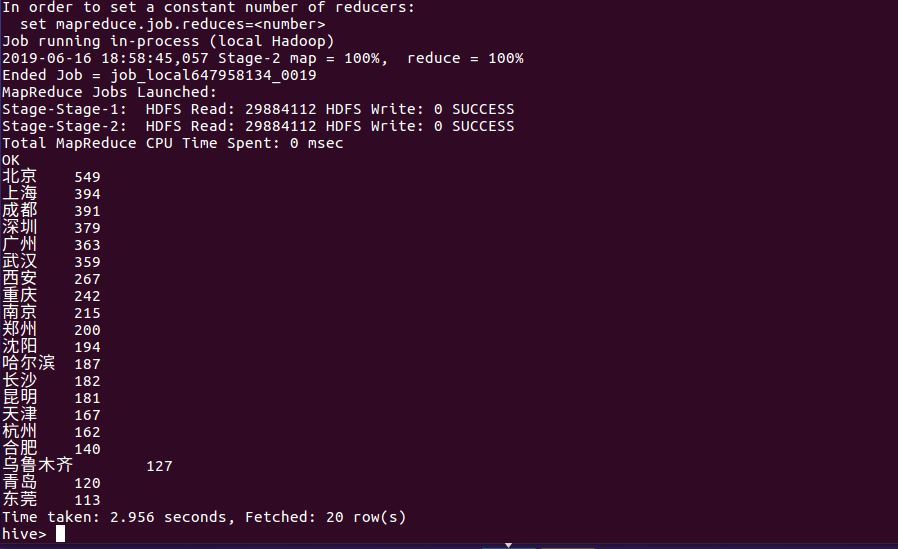
这是评论用户最多的前二十个城市,前面实际个都是国内发展得特别好的一线城市。
这不仅从侧面反映出这些城市的人流量高,生活水平高,同时也说明了电影在这些城市的宣传力度。
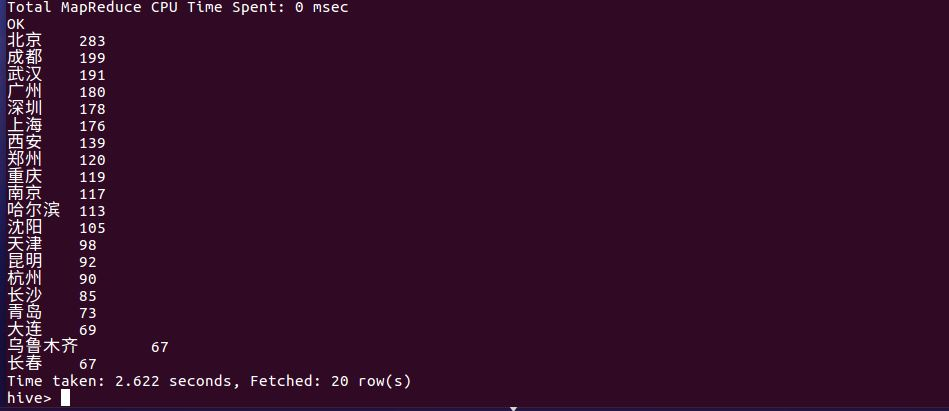
这是5分满分好评数量最多的前二十个城市。
与前面评论数最多的城市相比较,变化并不明显,总体来前二十城市的满分评分也接近50%以上。
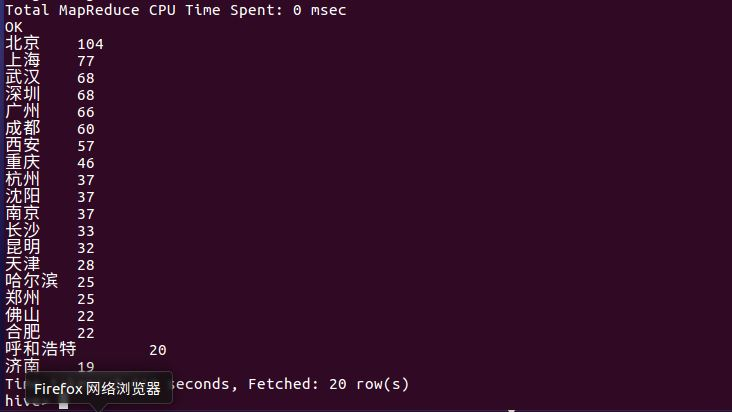
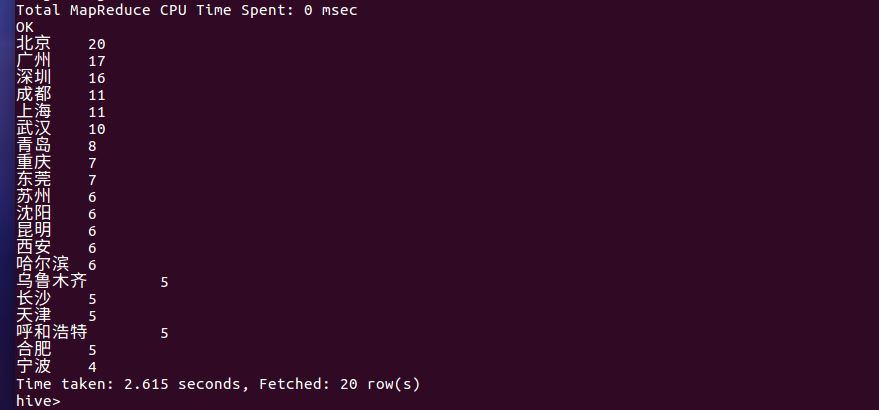
评论数最多的那几天都是电影的热映期,用户对于该电影的关注度还是挺不错的,而且愿意对这部电影提出自己的意见。