


linux 三剑客之awk
awk命令格式和选项
语法格式
awk [options] ‘program’ var=value file…
awk [options] -f programfile var=value file…
awk [options] 'BEGIN{ action;… } pattern{ action;… } END{ action;… }' file
常用命令选项
-F fs fs 指定输入分隔符,fs可以时字符串或正则表达式
-v var=value 赋值一个用户定义变量,将外部变量传递给awk
-f scriptfile 从脚本文件中读取awk命令
awk脚本
awk脚本是由模式和操作组成的。
模式与操作
模式
模式可以是以下任意一种:
正则表达式:使用通配符的扩展集
关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试
模式匹配表达式:用运算符~(匹配)和~!不匹配
BEGIN 语句块, pattern语句块, END语句块
操作
操作由一个或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大刮号内,主要部分是:变量或数组赋值、输出命令、内置函数、控制流语句。
awk脚本基本格式
awk 'BEGIN{ commands } pattern{ commands } END{ commands }' file
一个awk脚本通常由BEGIN, 通用语句块,END语句块组成,三部分都是可选的。 脚本通常是被单引号或双引号包住。
awk 'BEGIN{ i=0 } { i++ } END{ print i }' filename
awk执行过程分析
第一步: 执行BEGIN { commands } pattern 语句块中的语句
BEGIN语句块:在awk开始从输入输出流中读取行之前执行,在BEGIN语句块中执行如变量初始化,打印输出表头等操作。
第二步:从文件或标准输入中读取一行,然后执行pattern{ commands }语句块。它逐行扫描文件,从第一行到最后一行重复这个过程,直到全部文件都被读取完毕。
pattern语句块:pattern语句块中的通用命令是最重要的部分,它也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行。{ }类似一个循环体,会对文件中的每一行进行迭代,通常将变量初始化语句放在BEGIN语句块中,将打印结果等语句放在END语句块中。
第三步:当读至输入流末尾时,执行END { command }语句块
END语句块:在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块。
AWK内置变量
$n : 当记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段
$0: 这个变量包含执行过程中当前行的文本内容
ARGC : 命令行参数的数目。
ARGIND : 命令行中当前文件的位置(从0开始算)。
ARGV : 包含命令行参数的数组。
CONVFMT : 数字转换格式(默认值为%.6g)。
ENVIRON : 环境变量关联数组。
ERRNO : 最后一个系统错误的描述。
FIELDWIDTHS : 字段宽度列表(用空格键分隔)
FILENAME : 当前输入文件的名。
NR : 表示记录数,在执行过程中对应于当前的行号
FNR : 同NR :,但相对于当前文件。
FS : 字段分隔符(默认是任何空格)。
IGNORECASE : 如果为真,则进行忽略大小写的匹配。
NF : 表示字段数,在执行过程中对应于当前的字段数。 print $NF答应一行中最后一个段
OFMT : 数字的输出格式(默认值是%.6g)
OFS : 输出字段分隔符(默认值是一个空格)。
ORS : 输出记录分隔符(默认值是一个换行符)。
RS : 记录分隔符(默认是一个换行符)。
RSTART : 由match函数所匹配的字符串的第一个位置。
RLENGTH : 由match函数所匹配的字符串的长度。
SUBSEP : 数组下标分隔符(默认值是34)。
将外部变量值传递给awk
借助 -v 选项,可以将来自外部值(非stdin)传递给awk
VAR=10000
echo | awk -v VARIABLE=$VAR '{ print VARIABLE }'
定义内部变量接收外部变量
var1="aaa"
var2="bbb"
echo | awk '{ print v1,v2 }' v1=$var1 v2=$var2
当输入来自文件时
awk '{ print v1,v2 }' v1=$var1 v2=$var2 filename
awk运算
算术运算:(+,-,*,/,&,!,……,++,--)
所有用作算术运算符进行操作时,操作数自动转为数值,所有非数值都变为0
赋值运算:(=, +=, -=,*=,/=,%=,……=,**=)
逻辑运算符: (||, &&)
关系运算符:(<, <=, >,>=,!=, ==)
正则运算符:(~,~!)(匹配正则表达式,与不匹配正则表达式)
循环结构
for循环
for(expr1;expr2;expr3) {statement;…}
for(变量 in 数组)
特殊用法:能够遍历数组中的元素
语法:for(var in array) {for-body}
例子
awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}' /etc/grub2.cfg
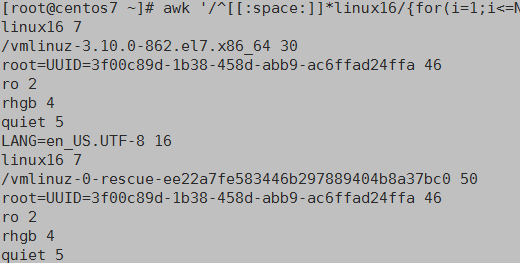
显示出文件的每行字母数
while循环
语法:while(condition){statement;…}
条件“真”,进入循环;条件“假”,退出循环
do...while循环
- 语法:do {statement;…}while(condition)
其他相关语句
break:退出程序循环
continue: 进入下一次循环
next:读取下一个输入行
exit:退出主输入循环,进入END,若没有END或END中有exit语句,则退出脚本。
Awk数组(数组大多为关联数组)
可使用任意字符串;字符串要使用双引号括起来
如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为“空串”
遍历数组:for(var in array) {for-body}
例awk '{ip[$1]++}END{for(i in ip) {print i,ip[i]}}' access_log
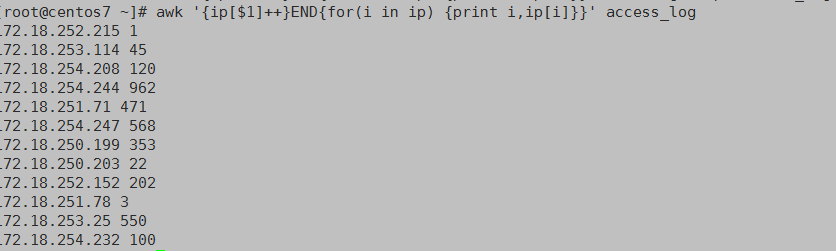
Awk函数
一,算术函数
|
Rand() |
返回任意数组你,其中0<=n<=1 |
|
Int(x) |
返回x的截断至整数的值 |
|
Sqrt(x) |
返回x的平方根 |
|
log( x ) |
返回 x 的自然对数 |
|
exp( x ) |
返回 x 幂函数。 |
|
sin( x ) |
返回 x 的正弦;x 是弧度 |
|
cos( x ) |
返回 x 的余弦;x 是弧度 |
|
atan2( y, x ) |
返回 y/x 的反正切。 |
例子:
awk 'BEGIN{srand(); for (i=1;i<=10;i++)print int(rand()*100) }'
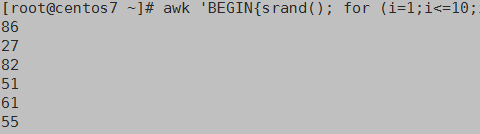
二:字符串函数
|
length([s]) |
返回指定字符串的长度 |
|
sub(r,s,[t]) |
对t字符串进行搜索r表示的模式匹配的内容,并将第一个匹配的内容替换为s |
|
gsub(r,s,[t |
对t字符串进行搜索r表示的模式匹配的内容,并全部替换为s所表示的内容 |
|
split(s,array,[r]) |
以r为分隔符,切割字符串s,并将切割后的结果保存至array所表示的数组 中,第一个索引值为1,第二个索引值为2,… |
例:echo "2008:08:08 08:08:08" | awk 'sub(/:/,“-",$1)
![]()
把第一个:改成了 —
echo "2008:08:08 08:08:08" | awk ‘gsub(/:/,“-",$0)
![]()
把所有的:改成了—
三;自定义函数
格式
function name ( parameter, parameter, ... ) {
statements
return expression
}
例:
function max(v1,v2) {
v1>v2?var=v1:var=v2
return var
}
BEGIN{a=3;b=2;print max(a,b)}
Function max()
