

CoreCLR源码探索(七) JIT的工作原理(入门篇)
很多C#的初学者都会有这么一个疑问, .Net程序代码是如何被机器加载执行的?
最简单的解答是, C#会通过编译器(CodeDom, Roslyn)编译成IL代码,
然后CLR(.Net Framework, .Net Core, Mono)会把这些IL代码编译成目标机器的机器代码并执行.
相信大多数的C#的书籍都是这样一笔带过的.
这篇和下篇文章会深入讲解JIT的具体工作流程,
和前面的GC篇一样, 实现中的很多细节都是无标准文档的, 用搜索引擎不会找到它们相关的资料.
因为内容相当多, 讲解JIT的文章将会分为两篇.
第一篇是入门篇, 看过这个系列之前的文章和CLR via C#, 了解一些编译原理的都可以看的明白.
第二篇是详解篇, 会分析JIT的具体实现流程, 算法和数据结构.
这篇的内容是基于CoreCLR 1.1.0分析的, 其他CLR中的实现不一定和这篇分析的实现完全一样.
微软最近提供了一篇JIT入门文档,
尽管里面写的相当潦草但是仍有很大的参考价值, 推荐同时参考这个文档.
JIT的作用介绍
相信很多C#程序员都知道, 我们编写的C#代码在经过编译后得出的exe或dll里面包含的并不是机器代码,
而是一种中间代码, 也称为MSIL(简称IL).
MSIL可以在不同的系统或者平台上执行, CLR中执行它们的模块就是这篇要讲的JIT.
如图所示

CoreCLR中的JIT代号是RyuJIT, RyuJIT可以把MSIL翻译为X86, X64或者ARM的机器代码.
使用JIT的好处有
- 同一个程序集可以在不同平台上运行
- 减少编译时间(编译到MSIL的时间比编译到机器代码的时间要短很多)
- 可以根据目标平台选择最优的代码(例如只在支持AVX指令的CPU使用AVX指令)
使用JIT的坏处有
- 增加运行负担
- 不能执行过多的优化(否则将会增加更多的运行负担)
- 部分平台上无法使用(例如iOS)
为了解决这些坏处而出现的技术有NGEN, AOT, CoreRT等, 但是使用它们以后同时也就失去了使用JIT的好处.
JIT的流程总览
以下的图片来源于微软提供的JIT入门文档:

总体上来说RyuJIT可以分为两个部分.
前端: 也就是图上的第一行, 负责把MSIL转换为JIT中的内部表现(IR)并且执行优化.
后端: 也就是图上的第二行, 负责准备生产机器代码, 分配寄存器等与平台相关的处理.
具体的步骤可以分为:

前端的步骤有(导入MSIL和优化):


后端的步骤有(平台相关的处理):

JIT的流程实例
只看上面的图你可能会一头雾水, 我们来看看实际的流程.
为了更容易理解这里我使用的是Debug模式.
以下的内容来源于CoreCLR的输出, 设置环境变量"COMPlus_JitDump=Main"并且使用Debug版的CoreCLR即可得到.
首先是C#代码, 非常简单的循环3次并且输出到控制台.
using System;
using System.Runtime.InteropServices;
namespace ConsoleApplication
{
public class Program
{
public static void Main(string[] args)
{
for (int x = 0; x < 3; ++x)
{
Console.WriteLine(x);
}
}
}
}
经过编译后会生成以下的IL, 下面我标记了运行堆栈的状态和简单的注释.
IL to import:
IL_0000 00 nop
IL_0001 16 ldc.i4.0 ; 运行堆栈 [ 0 ]
IL_0002 0a stloc.0 ; 运行堆栈 [ ], 保存到本地变量0 (x = 0)
IL_0003 2b 0d br.s 13 (IL_0012) ; 跳转到IL_0012
IL_0005 00 nop
IL_0006 06 ldloc.0 ; 运行堆栈 [ x ]
IL_0007 28 0c 00 00 0a call 0xA00000C ; 运行堆栈 [ ], 调用Console.WriteLine, 这里的0xA00000C是token
IL_000c 00 nop
IL_000d 00 nop
IL_000e 06 ldloc.0 ; 运行堆栈 [ x ]
IL_000f 17 ldc.i4.1 ; 运行堆栈 [ x, 1 ]
IL_0010 58 add ; 运行堆栈 [ x+1 ]
IL_0011 0a stloc.0 ; 运行堆栈 [ ], 保存到本地变量0 (x = x + 1)
IL_0012 06 ldloc.0 ; 运行堆栈 [ x ]
IL_0013 19 ldc.i4.3 ; 运行堆栈 [ x, 3 ]
IL_0014 fe 04 clt ; 运行堆栈 [ x<3 ]
IL_0016 0b stloc.1 ; 运行堆栈 [ ], 保存到本地变量1 (tmp = x < 3)
IL_0017 07 ldloc.1 ; 运行堆栈 [ tmp ]
IL_0018 2d eb brtrue.s -21 (IL_0005); 运行堆栈 [ ], 如果tmp为true则跳转到IL_0005
IL_001a 2a ret ; 从函数返回
RyuJIT的前端会把IL导入为中间表现(IR), 如下
Importing BB02 (PC=000) of 'ConsoleApplication.Program:Main(ref)'
[ 0] 0 (0x000) nop
[000004] ------------ * stmtExpr void (IL 0x000... ???)
[000003] ------------ \--* no_op void
[ 0] 1 (0x001) ldc.i4.0 0
[ 1] 2 (0x002) stloc.0
[000008] ------------ * stmtExpr void (IL 0x001... ???)
[000005] ------------ | /--* const int 0
[000007] -A---------- \--* = int
[000006] D------N---- \--* lclVar int V01 loc0
[ 0] 3 (0x003) br.s
[000010] ------------ * stmtExpr void (IL 0x003... ???)
[000009] ------------ \--* nop void
Importing BB03 (PC=005) of 'ConsoleApplication.Program:Main(ref)'
[ 0] 5 (0x005) nop
[000025] ------------ * stmtExpr void (IL 0x005... ???)
[000024] ------------ \--* no_op void
[ 0] 6 (0x006) ldloc.0
[ 1] 7 (0x007) call 0A00000C
[000029] ------------ * stmtExpr void (IL 0x006... ???)
[000027] --C-G------- \--* call void System.Console.WriteLine
[000026] ------------ arg0 \--* lclVar int V01 loc0
[ 0] 12 (0x00c) nop
[000031] ------------ * stmtExpr void (IL 0x00C... ???)
[000030] ------------ \--* no_op void
[ 0] 13 (0x00d) nop
[000033] ------------ * stmtExpr void (IL 0x00D... ???)
[000032] ------------ \--* no_op void
[ 0] 14 (0x00e) ldloc.0
[ 1] 15 (0x00f) ldc.i4.1 1
[ 2] 16 (0x010) add
[ 1] 17 (0x011) stloc.0
[000039] ------------ * stmtExpr void (IL 0x00E... ???)
[000035] ------------ | /--* const int 1
[000036] ------------ | /--* + int
[000034] ------------ | | \--* lclVar int V01 loc0
[000038] -A---------- \--* = int
[000037] D------N---- \--* lclVar int V01 loc0
Importing BB04 (PC=018) of 'ConsoleApplication.Program:Main(ref)'
[ 0] 18 (0x012) ldloc.0
[ 1] 19 (0x013) ldc.i4.3 3
[ 2] 20 (0x014) clt
[ 1] 22 (0x016) stloc.1
[000017] ------------ * stmtExpr void (IL 0x012... ???)
[000013] ------------ | /--* const int 3
[000014] ------------ | /--* < int
[000012] ------------ | | \--* lclVar int V01 loc0
[000016] -A---------- \--* = int
[000015] D------N---- \--* lclVar int V02 loc1
[ 0] 23 (0x017) ldloc.1
[ 1] 24 (0x018) brtrue.s
[000022] ------------ * stmtExpr void (IL 0x017... ???)
[000021] ------------ \--* jmpTrue void
[000019] ------------ | /--* const int 0
[000020] ------------ \--* != int
[000018] ------------ \--* lclVar int V02 loc1
Importing BB05 (PC=026) of 'ConsoleApplication.Program:Main(ref)'
[ 0] 26 (0x01a) ret
[000042] ------------ * stmtExpr void (IL 0x01A... ???)
[000041] ------------ \--* return void
我们可以看到IL被分成了好几组(BB02~BB05), 这里的BB是BasicBlock的缩写,
一个BasicBlock中有多个语句(Statement), 一个语句就是一棵树(GenTree).
上面的文本对应了以下的结构(又称HIR结构):

BasicBlock: 保存了一组语句, BasicBlock内原则上跳转指令只会出现在最后一个语句
Statement: 一个语句就是一棵树, 在内部Statement也是一个GenTree的子类(GenTreeStmt)
GenTree: 组成树的节点, 有很多不同的类型例如GenTreeUnOp(unary op), GenTreeIntCon(int constant)
有人可能会好奇为什么上面的BasicBlock从02开始, 这是因为01是内部用的block, 里面会保存函数开始时运行的内部处理.
接下来RyuJIT的前端会不断的修改HIR结构, 做出各种变形和优化:
Trees before IR Rationalize
-------------------------------------------------------------------------------------------------------------------------------------
BBnum descAddr ref try hnd preds weight [IL range] [jump] [EH region] [flags]
-------------------------------------------------------------------------------------------------------------------------------------
BB01 [00000000024701F8] 1 1 [???..???) i internal label target
BB02 [0000000002473350] 1 BB01 1 [???..???)-> BB04 ( cond ) internal
BB03 [0000000002473460] 1 BB02 0.5 [???..???) internal
BB04 [0000000002473240] 2 BB02,BB03 1 [???..???) i internal label target
BB05 [0000000002470470] 1 BB04 1 [000..005)-> BB07 (always) i
BB06 [0000000002470580] 1 BB07 1 [005..012) i label target gcsafe bwd
BB07 [0000000002470690] 2 BB05,BB06 1 [012..01A)-> BB06 ( cond ) i label target bwd
BB08 [00000000024707A0] 1 BB07 1 [01A..01B) (return) i
-------------------------------------------------------------------------------------------------------------------------------------
------------ BB01 [???..???), preds={} succs={BB02}
***** BB01, stmt 1
( 0, 0) [000001] ------------ * stmtExpr void (IL ???... ???)
N001 ( 0, 0) [000000] ------------ \--* nop void
------------ BB02 [???..???) -> BB04 (cond), preds={BB01} succs={BB03,BB04}
***** BB02, stmt 2
( 9, 16) [000055] ------------ * stmtExpr void (IL ???... ???)
N005 ( 9, 16) [000054] ------------ \--* jmpTrue void
N003 ( 1, 1) [000045] ------------ | /--* const int 0
N004 ( 7, 14) [000046] J------N---- \--* == int
N002 ( 5, 12) [000044] ------------ \--* indir int
N001 ( 3, 10) [000043] ------------ \--* const(h) long 0x7f95ea870610 token
------------ BB03 [???..???), preds={BB02} succs={BB04}
***** BB03, stmt 3
( 14, 5) [000056] ------------ * stmtExpr void (IL ???... ???)
N001 ( 14, 5) [000047] --C-G-?----- \--* call help void HELPER.CORINFO_HELP_DBG_IS_JUST_MY_CODE
------------ BB04 [???..???), preds={BB02,BB03} succs={BB05}
------------ BB05 [000..005) -> BB07 (always), preds={BB04} succs={BB07}
***** BB05, stmt 4
( 1, 1) [000004] ------------ * stmtExpr void (IL 0x000...0x000)
N001 ( 1, 1) [000003] ------------ \--* no_op void
***** BB05, stmt 5
( 1, 3) [000008] ------------ * stmtExpr void (IL 0x001...0x002)
N001 ( 1, 1) [000005] ------------ | /--* const int 0
N003 ( 1, 3) [000007] -A------R--- \--* = int
N002 ( 1, 1) [000006] D------N---- \--* lclVar int V01 loc0
***** BB05, stmt 6
( 0, 0) [000010] ------------ * stmtExpr void (IL 0x003...0x003)
N001 ( 0, 0) [000009] ------------ \--* nop void
------------ BB06 [005..012), preds={BB07} succs={BB07}
***** BB06, stmt 7
( 1, 1) [000025] ------------ * stmtExpr void (IL 0x005...0x005)
N001 ( 1, 1) [000024] ------------ \--* no_op void
***** BB06, stmt 8
( 15, 7) [000029] ------------ * stmtExpr void (IL 0x006...0x00C)
N005 ( 15, 7) [000027] --C-G------- \--* call void System.Console.WriteLine
N003 ( 1, 1) [000026] ------------ arg0 in rdi \--* lclVar int V01 loc0
***** BB06, stmt 9
( 1, 1) [000031] ------------ * stmtExpr void (IL 0x00C... ???)
N001 ( 1, 1) [000030] ------------ \--* no_op void
***** BB06, stmt 10
( 1, 1) [000033] ------------ * stmtExpr void (IL 0x00D...0x00D)
N001 ( 1, 1) [000032] ------------ \--* no_op void
***** BB06, stmt 11
( 3, 3) [000039] ------------ * stmtExpr void (IL 0x00E...0x011)
N002 ( 1, 1) [000035] ------------ | /--* const int 1
N003 ( 3, 3) [000036] ------------ | /--* + int
N001 ( 1, 1) [000034] ------------ | | \--* lclVar int V01 loc0
N005 ( 3, 3) [000038] -A------R--- \--* = int
N004 ( 1, 1) [000037] D------N---- \--* lclVar int V01 loc0
------------ BB07 [012..01A) -> BB06 (cond), preds={BB05,BB06} succs={BB08,BB06}
***** BB07, stmt 12
( 10, 6) [000017] ------------ * stmtExpr void (IL 0x012...0x016)
N002 ( 1, 1) [000013] ------------ | /--* const int 3
N003 ( 6, 3) [000014] ------------ | /--* < int
N001 ( 1, 1) [000012] ------------ | | \--* lclVar int V01 loc0
N005 ( 10, 6) [000016] -A------R--- \--* = int
N004 ( 3, 2) [000015] D------N---- \--* lclVar int V02 loc1
***** BB07, stmt 13
( 7, 6) [000022] ------------ * stmtExpr void (IL 0x017...0x018)
N004 ( 7, 6) [000021] ------------ \--* jmpTrue void
N002 ( 1, 1) [000019] ------------ | /--* const int 0
N003 ( 5, 4) [000020] J------N---- \--* != int
N001 ( 3, 2) [000018] ------------ \--* lclVar int V02 loc1
------------ BB08 [01A..01B) (return), preds={BB07} succs={}
***** BB08, stmt 14
( 0, 0) [000042] ------------ * stmtExpr void (IL 0x01A...0x01A)
N001 ( 0, 0) [000041] ------------ \--* return void
上面的内容目前可以不用理解, 我贴出来只是为了说明HIR结构经过了转换和变形.
接下来就会进入RyuJIT的后端, RyuJIT的后端会根据HIR结构生成LIR结构:
Trees after IR Rationalize
-------------------------------------------------------------------------------------------------------------------------------------
BBnum descAddr ref try hnd preds weight [IL range] [jump] [EH region] [flags]
-------------------------------------------------------------------------------------------------------------------------------------
BB01 [00000000024701F8] 1 1 [???..???) i internal label target LIR
BB02 [0000000002473350] 1 BB01 1 [???..???)-> BB04 ( cond ) internal LIR
BB03 [0000000002473460] 1 BB02 0.5 [???..???) internal LIR
BB04 [0000000002473240] 2 BB02,BB03 1 [???..???) i internal label target LIR
BB05 [0000000002470470] 1 BB04 1 [000..005)-> BB07 (always) i LIR
BB06 [0000000002470580] 1 BB07 1 [005..012) i label target gcsafe bwd LIR
BB07 [0000000002470690] 2 BB05,BB06 1 [012..01A)-> BB06 ( cond ) i label target bwd LIR
BB08 [00000000024707A0] 1 BB07 1 [01A..01B) (return) i LIR
-------------------------------------------------------------------------------------------------------------------------------------
------------ BB01 [???..???), preds={} succs={BB02}
N001 ( 0, 0) [000000] ------------ nop void
------------ BB02 [???..???) -> BB04 (cond), preds={BB01} succs={BB03,BB04}
N001 ( 3, 10) [000043] ------------ t43 = const(h) long 0x7f95ea870610 token
/--* t43 long
N002 ( 5, 12) [000044] ------------ t44 = * indir int
N003 ( 1, 1) [000045] ------------ t45 = const int 0
/--* t44 int
+--* t45 int
N004 ( 7, 14) [000046] J------N---- t46 = * == int
/--* t46 int
N005 ( 9, 16) [000054] ------------ * jmpTrue void
------------ BB03 [???..???), preds={BB02} succs={BB04}
N001 ( 14, 5) [000047] --C-G-?----- call help void HELPER.CORINFO_HELP_DBG_IS_JUST_MY_CODE
------------ BB04 [???..???), preds={BB02,BB03} succs={BB05}
------------ BB05 [000..005) -> BB07 (always), preds={BB04} succs={BB07}
( 1, 1) [000004] ------------ il_offset void IL offset: 0
N001 ( 1, 1) [000003] ------------ no_op void
( 1, 3) [000008] ------------ il_offset void IL offset: 1
N001 ( 1, 1) [000005] ------------ t5 = const int 0
/--* t5 int
N003 ( 1, 3) [000007] DA---------- * st.lclVar int V01 loc0
( 0, 0) [000010] ------------ il_offset void IL offset: 3
N001 ( 0, 0) [000009] ------------ nop void
------------ BB06 [005..012), preds={BB07} succs={BB07}
( 1, 1) [000025] ------------ il_offset void IL offset: 5
N001 ( 1, 1) [000024] ------------ no_op void
( 15, 7) [000029] ------------ il_offset void IL offset: 6
N003 ( 1, 1) [000026] ------------ t26 = lclVar int V01 loc0
/--* t26 int arg0 in rdi
N005 ( 15, 7) [000027] --C-G------- * call void System.Console.WriteLine
( 1, 1) [000031] ------------ il_offset void IL offset: 12
N001 ( 1, 1) [000030] ------------ no_op void
( 1, 1) [000033] ------------ il_offset void IL offset: 13
N001 ( 1, 1) [000032] ------------ no_op void
( 3, 3) [000039] ------------ il_offset void IL offset: 14
N001 ( 1, 1) [000034] ------------ t34 = lclVar int V01 loc0
N002 ( 1, 1) [000035] ------------ t35 = const int 1
/--* t34 int
+--* t35 int
N003 ( 3, 3) [000036] ------------ t36 = * + int
/--* t36 int
N005 ( 3, 3) [000038] DA---------- * st.lclVar int V01 loc0
------------ BB07 [012..01A) -> BB06 (cond), preds={BB05,BB06} succs={BB08,BB06}
( 10, 6) [000017] ------------ il_offset void IL offset: 18
N001 ( 1, 1) [000012] ------------ t12 = lclVar int V01 loc0
N002 ( 1, 1) [000013] ------------ t13 = const int 3
/--* t12 int
+--* t13 int
N003 ( 6, 3) [000014] ------------ t14 = * < int
/--* t14 int
N005 ( 10, 6) [000016] DA---------- * st.lclVar int V02 loc1
( 7, 6) [000022] ------------ il_offset void IL offset: 23
N001 ( 3, 2) [000018] ------------ t18 = lclVar int V02 loc1
N002 ( 1, 1) [000019] ------------ t19 = const int 0
/--* t18 int
+--* t19 int
N003 ( 5, 4) [000020] J------N---- t20 = * != int
/--* t20 int
N004 ( 7, 6) [000021] ------------ * jmpTrue void
------------ BB08 [01A..01B) (return), preds={BB07} succs={}
( 0, 0) [000042] ------------ il_offset void IL offset: 26
N001 ( 0, 0) [000041] ------------ return void
我们可以看到在LIR结构里, BasicBlock包含的是GenTree节点的有序列表, 原来是树结构的节点现在都连成了一串.
LIR结构跟最终生成的机器代码结构非常的相似.
接下来RyuJIT的后端会给LIR结构中的GenTree节点分配寄存器, 并且根据LIR结构生成汇编指令列表:
Instructions as they come out of the scheduler
G_M21556_IG01: ; func=00, offs=000000H, size=0016H, gcrefRegs=00000000 {}, byrefRegs=00000000 {}, byref, nogc <-- Prolog IG
IN001b: 000000 55 push rbp
IN001c: 000001 4883EC10 sub rsp, 16
IN001d: 000005 488D6C2410 lea rbp, [rsp+10H]
IN001e: 00000A 33C0 xor rax, rax
IN001f: 00000C 8945F4 mov dword ptr [rbp-0CH], eax
IN0020: 00000F 8945F0 mov dword ptr [rbp-10H], eax
IN0021: 000012 48897DF8 mov gword ptr [rbp-08H], rdi
G_M21556_IG02: ; func=00, offs=000016H, size=0014H, gcrefRegs=00000000 {}, byrefRegs=00000000 {}, byref, isz
IN0001: 000016 48B8100687EA957F0000 mov rax, 0x7F95EA870610
IN0002: 000020 833800 cmp dword ptr [rax], 0
IN0003: 000023 7405 je SHORT G_M21556_IG03
[02479BA8] ptr arg pop 0
IN0004: 000025 E8D6E0B578 call CORINFO_HELP_DBG_IS_JUST_MY_CODE
G_M21556_IG03: ; func=00, offs=00002AH, size=0009H, gcrefRegs=00000000 {}, byrefRegs=00000000 {}, byref, isz
IN0005: 00002A 90 nop
IN0006: 00002B 33FF xor edi, edi
IN0007: 00002D 897DF4 mov dword ptr [rbp-0CH], edi
IN0008: 000030 90 nop
IN0009: 000031 EB13 jmp SHORT G_M21556_IG05
G_M21556_IG04: ; func=00, offs=000033H, size=0013H, gcrefRegs=00000000 {}, byrefRegs=00000000 {}, byref
IN000a: 000033 90 nop
IN000b: 000034 8B7DF4 mov edi, dword ptr [rbp-0CH]
[02479BC0] ptr arg pop 0
IN000c: 000037 E864F7FFFF call System.Console:WriteLine(int)
IN000d: 00003C 90 nop
IN000e: 00003D 90 nop
IN000f: 00003E 8B45F4 mov eax, dword ptr [rbp-0CH]
IN0010: 000041 FFC0 inc eax
IN0011: 000043 8945F4 mov dword ptr [rbp-0CH], eax
G_M21556_IG05: ; func=00, offs=000046H, size=0019H, gcrefRegs=00000000 {}, byrefRegs=00000000 {}, byref, isz
IN0012: 000046 8B7DF4 mov edi, dword ptr [rbp-0CH]
IN0013: 000049 83FF03 cmp edi, 3
IN0014: 00004C 400F9CC7 setl dil
IN0015: 000050 400FB6FF movzx rdi, dil
IN0016: 000054 897DF0 mov dword ptr [rbp-10H], edi
IN0017: 000057 8B7DF0 mov edi, dword ptr [rbp-10H]
IN0018: 00005A 85FF test edi, edi
IN0019: 00005C 75D5 jne SHORT G_M21556_IG04
IN001a: 00005E 90 nop
G_M21556_IG06: ; func=00, offs=00005FH, size=0006H, epilog, nogc, emitadd
IN0022: 00005F 488D6500 lea rsp, [rbp]
IN0023: 000063 5D pop rbp
IN0024: 000064 C3 ret
最后Emitter把这些指令编码成机器代码就完成了JIT的编译工作.
JIT的数据结构
以下的图片来源于微软提供的JIT入门文档:
第一张是HIR的数据结构
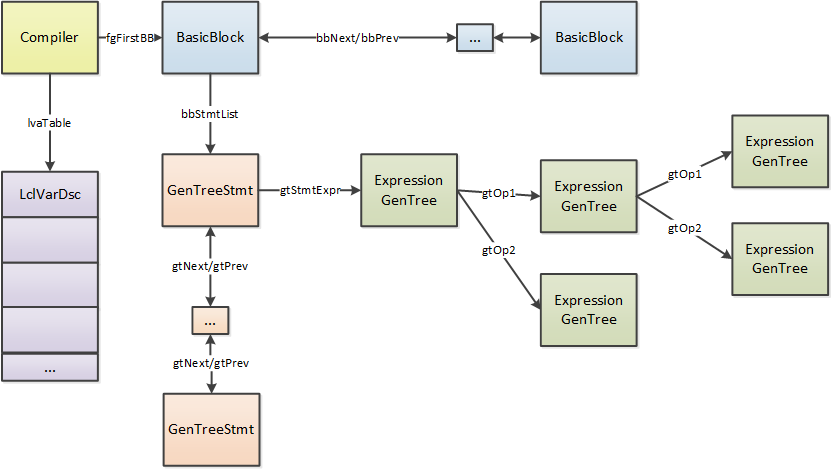
第二张是LIR的数据结构

第三张是CoreCLR中实际的数据结构(HIR和LIR会共用GenTree节点).

JIT的触发
在相当多的.NET书籍中都提到过, CLR中的JIT是懒编译的, 那么具体是如何实现的?
JIT针对每个函数都会提供一个"桩"(Stub), 第一次调用时会触发JIT编译, 第二次调用时会跳转到第一次的编译结果.
流程参考下图:

JIT之前的桩(例子)
0x7fff7c21f5a8: e8 2b 6c fe ff callq 0x7fff7c2061d8
JIT之后的桩(例子)
0x7fff7c21f5a8: e9 a3 87 3a 00 jmp 0x7fff7c5c7d50
具体的汇编代码分析我会在下一篇中给出, 目前你只需要理解"桩"起到的是一个路由的作用.
目前的CoreCLR触发了JIT编译后, 会在当前线程中执行JIT编译.
如果多个线程同时调用了一个未JIT的函数, 其中一个线程会执行编译, 其他线程会等待编译完成.
CoreCLR会对正在JIT编译的函数分配一个线程锁(ListLockEntry)来实现这一点.
JIT会为准备的函数创建一个Compiler实例, Compiler实例储存了BasicBlock列表等编译时需要的信息.
一个正在编译的函数对应一个Compiler实例, 函数编译后Compiler实例会被销毁.
接下来我会对JIT的各项步骤进行一个简单的说明.
Frontend
Importer
Importer负责读取和解析IL(byte array), 并根据IL生成JIT使用的内部表现IR(BasicBlock, Statement, GenTree).
BasicBlock会根据它们的跳转类型连接成一个图(graph).
第一个BasicBlock是内部使用的, 会添加一些函数进入的初始化处理(但不要和汇编中的prolog混淆).
下图是Importer的实例:

Inliner
如果函数符合内联的条件, 则Inliner会把函数的IR嵌入到它的调用端函数(callsite), 并且对本地变量和参数进行修整.
执行内联后接下来的步骤将在调用端函数中完成.
内联的条件有很多, 判断逻辑也相当的复杂, 这里我只列出一部分:
- 未开启优化时不内联
- 函数是尾调用则不内联
- 函数是虚函数时不内敛
- 函数是helper call时不内联
- 函数是indirect call时(编译时无法确认地址)时不内联
- 未设置COMPlus_AggressiveInlining环境变量且函数在catch或者filter中时不内联
- 之前尝试内联失败时不内联
- 同步函数(CORINFO_FLG_SYNCH)不内联
- 函数需要安全检查(CORINFO_FLG_SECURITYCHECK)时不内联
- 如果函数有例外处理器则不内联
- 函数无内容(大小=0)则不内联
- 函数参数是vararg时不内联
- 函数中的本地变量数量大于MAX_INL_LCLS(32)时不内联
- 函数中的参数数量大于MAX_INL_LCLS时不内联
- 函数中的本地变量(包含内部变量)有512个以上, 则标记内联失败
- 如果出现循环inline, 例如A inline B, B inline A, 则标记内联失败
- 如果层数大于InlineStrategy::IMPLEMENTATION_MAX_INLINE_DEPTH(1000), 则标记内联失败
- 如果函数有返回类型但无返回表达式(包含throw), 则标记内联失败
- 如果初始化内联函数所在的class失败, 则标记内联失败
- 如果内联函数估算体积 > 调用函数的指令体积 * 系数(DetermineMultiplier), 则标记内联失败
- 等等
下图是Inliner的实例:

Morph
Morph会对Importer导入的HIR进行变形, 这个步骤包含了很多处理, 这里我只列出一部分:
- 在第一个BasicBlock插入内部使用的代码
- 删除无法到达的BasicBlock(死代码)
- 如果有多个return block并且需要合并, 则生成一个新的return block并且让原来的block指向它
- 对本地的struct变量进行promotion, 把各个字段提取出来作为单独的变量
- 对各个节点进行修改
- 标记节点是否需要检查null
- 标记节点是否需要检查边界
- 根据节点添加断言
- 例如
a = 5即可断言a等于5,b = new X()即可断言b != null
- 例如
- 需要时添加cast
- 对于平台不支持的操作转换为helper call, 例如(1f+1f)转换为float_add(1f, 1f)
- 进行简单的优化, 例如(常量+常量)转换为(常量)
- 转换一些表达式, 例如(1 op 2 == 0)转换为(1 (rev op) 2)
- 如果表达式带有溢出检查(checked), 则添加对应的throw block, 只添加一次
- 添加检查数组边界的代码
- 尾调用(tail call)优化
- 等等
经过Morph变形后的HIR将会包含更多信息, 对IL中隐式的处理(例如边界检查和溢出检查)也添加了显式的代码(GenTree).
下图是Morph的实例:

图中的comma表示的是逗号式, 例如(X(), 123)这个式会先评价X()然后结果使用123,
上图中的comma会先把数组保存到一个临时变量, 执行边界检查, 然后再访问数组中的元素然后输出到控制台.
Flowgraph Analysis
Flowgraph Analysis会对BasicBlock进行流程分析,
找出BasicBlock有哪些前任block(predecessor)和后继block(successor), 并且标记BasicBlock的引用次数.
如果一个block是多个block的跳转目标, 则这个block有多个preds,
如果一个block的跳转类型是jtrue(条件成立时跳转到目标block, 否则到下一个block), 则这个block有两个succs.
并且计算DOM(dominator)树,
例如出现 A -> B, A -> C, B -> D, C -> D, 则D的dominator不是B或C而是A, 表示执行D必须经过A,
参考Wikipedia和论文.

例如在这张图中:
- block 1的preds是[], succs是[2]
- block 2的preds是[1, 5], succs是[3, 4, 6]
- block 3的preds是[2], succs是[5]
- block 4的preds是[2], succs是[5]
- block 5的preds是[3, 4], succs是[2]
- block 6的preds是[2], succs是[]
计算出来的DOM(dominator)树为:

然后会根据流程分析的结果进行一些优化:
优化 while 到 do while:
优化前 jmp test; loop: ...; test: cond; jtrue loop;
优化后 cond; jfalse done; loop: ...; test: cond; jtrue loop; done: ...;
优化循环中数组的边界检查:
优化前 for (var x = 0; x < a.Length; ++x) { b[x] = a[x]; },
优化后
if (x < a.Length) {
if ((a != null && b != null) && (a.Length <= b.Length)) {
do {
var tmp = a[x]; // no bounds check
b[x] = tmp; // no bounds check
x = x + 1;
} while (x < a.Length);
} else {
do {
var tmp = a[x];
b[x] = tmp;
x = x + 1;
} while (x < a.Length);
}
}
优化次数是常量的循环:
优化前 for (var x = 0; x < 3; ++x) { DoSomething(); }
优化后 DoSomething(); DoSomething(); DoSomething();
注意循环次数过多或者循环中的代码过长则不会执行这项优化.
LclVar sorting & Tree Ordering
这个步骤会标记函数中本地变量的引用计数, 并且按引用计数排序本地变量表.
然后会对tree的运行运行顺序执行标记, 例如 a() + b(), 会标记a()先于b()执行.
(与C, C++不同, .Net中对操作参数的运行顺序有很严格的规定, 例如a+b和f(a, b)的运行顺序都是已规定的)
经过运行顺序标记后其实就已经形成了LIR结构.
LIR结构中无语句(Statement)节点, 语句节点经过在后面的Rationalization后会变为IL_OFFSET节点, 用于对应的IL偏移值,
最终VisualStudio等IDE可以根据机器代码地址=>IL偏移值=>C#代码偏移值来下断点和调试.
下图是Tree Ordering的实例, 红线表示连接下一个节点:

Optimize
SSA & VN
RyuJIT为了实现更好的优化, 会对GenTree节点分配SSA序号和VN.
要说明什么是SSA, 可以拿Wikipedia上的代码做例子:

这里有4个BasicBlock和3个变量(x, y, w), 变量的值会随着执行而改变,
我们很难确定两个时点的y是否同一个y, 这为代码优化带来了障碍.

为了解决这个问题我们为每个变量都标记一个版本号, 修改一次它的值就会出现一个新的版本.
这就是SSA(Static single assignment form), 一个变量+版本只能有一个值, 这时我们可以很简单的确定两个时点的y是否同一个y.
但是上图有一个问题, 最后一个BasicBlock使用的y在编译时是无法确定来源于哪个版本的.

为了解决这个问题, SSA引入了Φ(Phi)函数, 最后一个BasicBlock的开头添加一个新的版本y3 = Φ(y1, y2).
而VN(Value Number)则是基于SSA的标记, 会根据给GenTree分配一个唯一的ID, 例如x = 3和w = 3时, x和w的VN会相等.
下图是标记SSA和VN的实例:

Loop Optimizations
上面的"Flowgraph Analysis"提到的针对循环的一些优化, 在生成了SSA和VN以后我们可以做出进一步的优化.
例如这样的循环:
var a = SomeFunction();
for (var x = 0; x < 3; ++x) {
Console.WriteLine(a * 3);
}
注意a * 3这个表达式, 它每次循环都是一样的并且无副作用, 也就是我们可以提取(hoist)它到循环外面:
var a = SomeFunction();
var tmp = a * 3;
for (var x = 0; x < 3; ++x) {
Console.WriteLine(tmp);
}
这样a * 3我们就只需要计算一次了, 但需要注意的是这种优化会增加一个临时变量, 所以实际不一定会执行.
Copy Propagation
这项优化会替换具有相同VN的本地变量,
例如var tmp = a; var b = tmp + 1;, 因为我们确定tmp和a的值(VN)是一致的, 可以优化为var b = a + 1.
在执行这项优化后, 多余的临时变量将不再需要, 例如上面的tmp变量如果引用计数为0即可删除.
CSE
这项优化会替换具有相同VN的表达式, 比起Copy Propagation这项优化的效果更强大.
例如:
var a = SomeFunction();
var b = (a + 5) * a;
var c = (a + 5) + a;
注意a + 5这个表达式出现了两次, 这两次对应的GenTree的VN都是一样的,
因为它们无副作用(不会修改到全局状态), JIT可以把这段代码优化为:
var a = SomeFunction();
var tmp = a + 5;
var b = tmp * a;
var c = tmp + a;
和上面的Loop Optimizations一样, 这种优化会增加一个临时变量, 所以实际不一定会执行.
Assertion Propagation
在上面的Morph中JIT根据语句添加了一些断言, 在生成VN后JIT可以传播这些断言.
例如:
var x = 1; // x确定为1
var y = x + 2;
传播断言后:
var x = 1; // x确定为1
var y = x + 2; // y确定为3
Range Check Elimination
因为断言已经传播, 这项优化可以根据断言和VN来判断哪些数组的边界检查是多余的.
例如:
var length = 100;
var index = 99;
var a = new int[length]; // a的长度确定为100
var b = a[index]; // 确定访问不会越界, 所以这里的边界检查可以去掉
Backend
Rationalization
这个步骤会正式把HIR转换为LIR, 后面的步骤使用的都是LIR形式.
前面的HIR中存在着一些问题, 例如ASG(=)节点:

看出问题了吗?lclVar在LIR中如果不访问后面的节点, 无法确定是读取变量还是写入变量.
Rationalizer会修改这些有问题的GenTree, 让后面的处理更加简单.
上面的lclVar =会修改为st.lclVar, 与lclVar区别开来.
Lowering
这个步骤会修改LIR中的GenTree节点, 让它更接近最终生成的机器代码形式.
以下是部分会转换的GenTree节点:
- ARR_LENGTH(获取数组长度), 会转换为IND(arr + ArrLenOffset), IND相当于C中的deref(*ptr)
- 计算式, 可能时转换为LEA, 例如
((v07 << 2) + v01) + 16可以转换为lea(v01 + v07*4 + 16) - LONG, 如果当前cpu是x86(32位)则需要分为两个变量操作
- SWITCH, 切割SWITCH到
if else和jmp jumpTable[x-offset] - CALL, 对于参数添加putarg节点(指定需要放到哪个寄存器或者推入堆栈)
- STMT, 转换为IL_OFFSET, 让机器代码地址跟IL偏移值可以对应起来
在完成了对GenTree节点的修改后, Lowering会对每个节点确定来源(src)和目标(dst)的寄存器数量.
例如lclVar节点需要一个目标寄存器, lclVar + lclVar节点需要两个来源寄存器和一个目标寄存器.
除了设置需要的寄存器数量外, Lowering还会标记哪些节点是contained,
标记为contained的节点代表它是上级节点的一部分, 生成指令时不需要针对contained节点单独生成.
典型的contained节点是常量, 例如b = a + 1可以生成add rbx, 1; mov rdi, rbx;, 这里的1并不需要一条单独的指令.
下图是Lowering的实例:

LSRA
在Lowering确认了寄存器需求以后, JIT还需要给这些节点实际的分配寄存器.
分配寄存器的算法有Graph coloring和LSRA等, RyuJIT使用的是LSRA, 和论文中的算法很相似.
使用LSRA算法可以让JIT中分配寄存器所需的计算量更少, 但是分配的结果(执行效率)会比Graph coloring差一些.
在LSRA中有以下概念:
- RefPosition: 记录定义或使用变量的位置, 如果是Def或者Use则有所属的Interval
- Interval: 同一个变量对应的使用期间, 包含多个RefPosition
- LocationInfo: 代码位置, 在构建时会对LIR中的GenTree分配位置, 位置总会+2
下图是LSRA的实例:
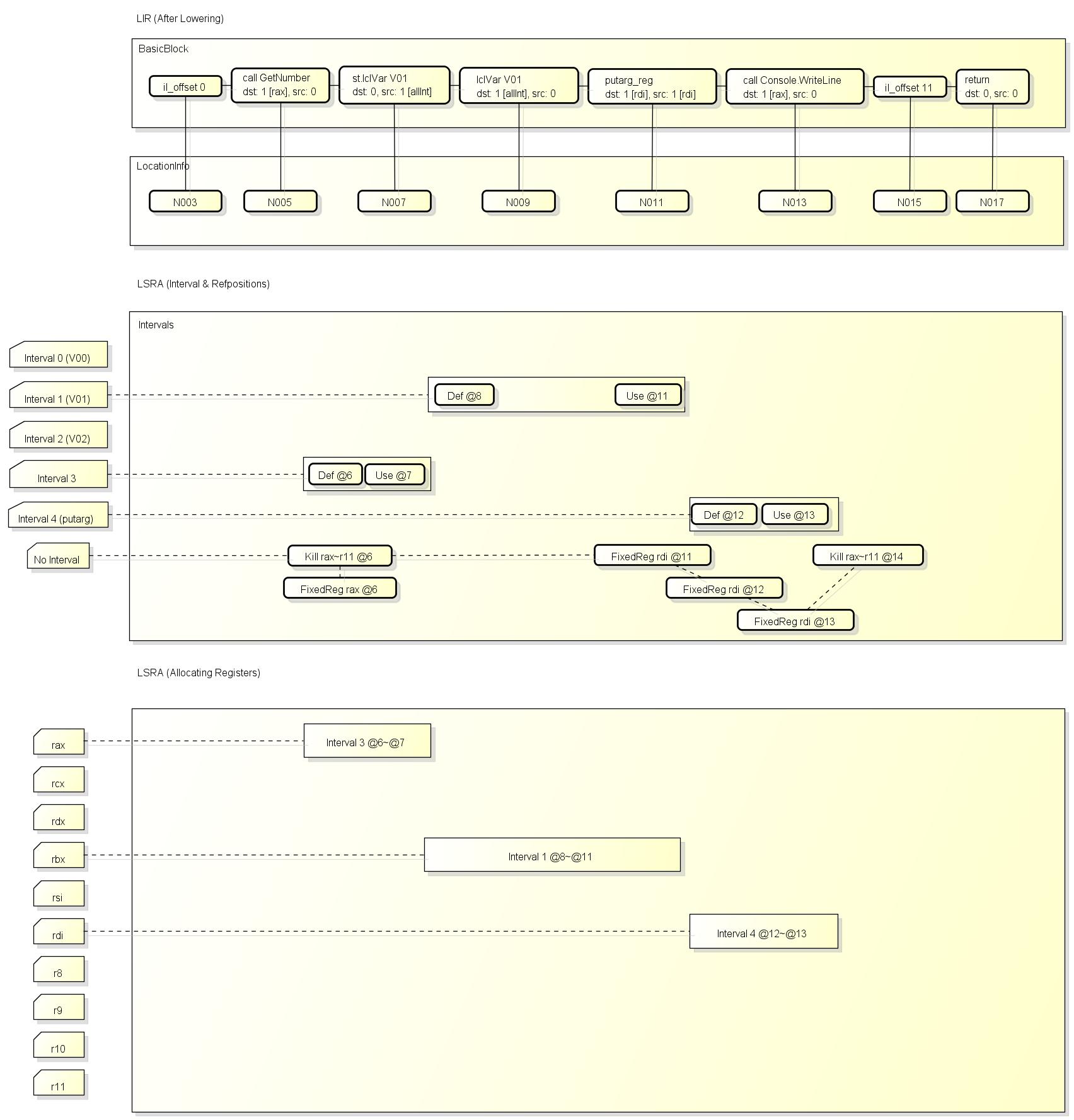
在这张图中, Interval 0~2 是本地变量, 这里只有V01被使用, Interval 3~4是虚拟变量, 用于表示函数返回的结果或传入的参数.
DEF表示Interval被写入, USE表示Interval被读取,
Kill无对应的Interval, 只用于表示指定的寄存器的值是否在某个位置后被破坏,
FixedReg也无对应的Interval, 只用于表示对应的位置使用了固定的寄存器.
在确认Interval和RefPosition后, LSRA会开始分配寄存器,
一个寄存器在同一时间只能被一个Interval使用, 图上的寄存器都未出现Interval重叠的情况,
如果出现Interval重叠, 寄存器中的值会保存(spill)到堆栈上的变量.
如果一个变量从未被spill, 则该变量可以不使用堆栈保存, 如图上的V01可以一直存在rbx中, 不需要保存在内存里,
这可以带来很大幅度的性能提升.
LSRA会积极的使用Callee Saved Register(RBX, RBP, R12, R13, R14, R15)暂存变量,
这些寄存器在调用(call)其它函数后原来的值仍然会被保留, 不需要spill.
CodeGen
在以上步骤都完成后, JIT会根据cpu平台(x86, x64, arm)生成不一样的汇编指令.
在CodeGen中有以下概念:
- instrDesc: 汇编指令的数据, 一个instrDesc实例对应一条汇编指令
- insGroup: 汇编指令的组, 一个insGroup包含一个或多个instrDesc, 跳转指令的目标只能是IG的第一条指令
下图是CodeGen的实例:

如图所示, CodeGen会按LIR中的节点和LSRA分配的寄存器信息生成汇编指令, 并且会对指令进行分组储存在不同的IG中.
进入函数的prolog和离开函数的epilog指令也会在这里添加.
CodeGen还会对汇编指令的大小进行估算, 确定最多需要分配多少内存才可以编码这些指令.
Emiiter
在最后, Emiiter会从LoaderHeap中分配内存, 并且根据instrDesc编码机器代码.
下图是Emitter的实例:

除了写入机器代码外, Emiiter还会写入以下的信息:
- phdrDebugInfo: 包含了机器代码地址到IL偏移值的索引
- phdrJitEHInfo: 包含了函数中的例外信息
- phdrJitGCInfo: 包含了函数中需要GC扫描的变量的信息
- unindInfos: 包含了函数的堆栈回滚信息(在什么位置使用了多大的堆栈空间)
最终写入的函数在内存中的结构如下:

机器代码的前面是函数头信息(CodeHeader), 函数头信息指向真正的函数头信息(RealCodeHeader), 真正的头信息中包含了上面提到的信息.
我们可以实际在Visual Studio中确认这一点:

图中的0x7ffa46d0d898就是CodeHeader的内容, 也是指向RealCodeHeader的指针.
后面的55 57 56 ...是机器代码, 表示push rbp; push rdi; push rsi; ....

打开0x7ffa46d0d898可以看到RealCodeHeader的内容.
参考链接
- https://github.com/dotnet/coreclr/blob/master/Documentation/botr/ryujit-tutorial.md
- https://github.com/dotnet/coreclr/blob/release/1.1.0/Documentation/botr/ryujit-overview.md
- https://github.com/dotnet/coreclr/blob/release/1.1.0/Documentation/building/viewing-jit-dumps.md
- https://en.wikipedia.org/wiki/Dominator_(graph_theory)
- https://www.cs.rice.edu/~keith/EMBED/dom.pdf
- https://en.wikipedia.org/wiki/Static_single_assignment_form
- https://en.wikipedia.org/wiki/Global_value_numbering
- https://en.wikipedia.org/wiki/Graph_coloring
- https://www.usenix.org/legacy/events/vee05/full_papers/p132-wimmer.pdf
这篇是JIT的入门+科普教程, 为了让内容更加易懂我省略了大量的实现细节, 也没有贴出CoreCLR中的代码.
在下一篇我将结合CoreCLR中的代码讲解JIT的具体工作流程, 内容会比这一篇难很多, 绝大多数C#程序员只要理解这一篇就很足够了.
