Structured Multimodal Attentions for TextVQA

原文链接:https://arxiv.org/pdf/2006.00753
Motivation

对于TextVQA任务,作者提出了一种基于结构化的文本-物体图的模型。图中文本和物体作为节点,节点之间的联系作为边。
Pipeline
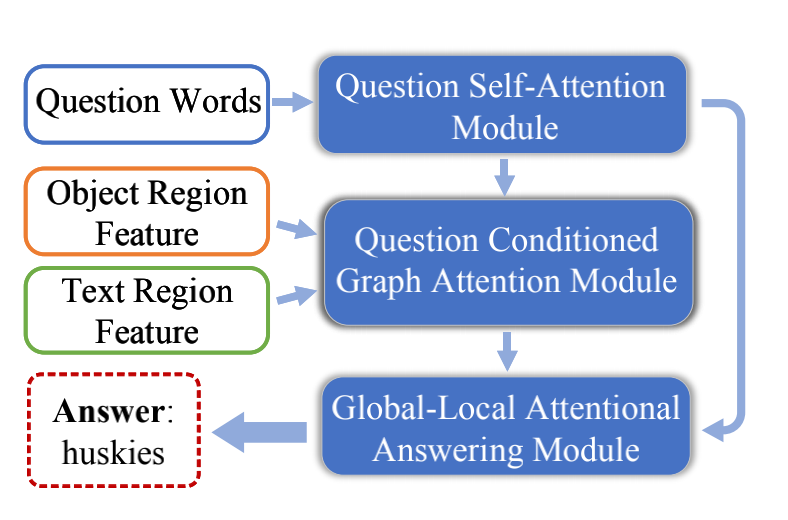
TextVQA任务需要三个步骤:reading,reasoning,answering,该模型专注于后两个步骤。
1、Question self-attention module:问题拆解为物体、文本、物体-物体、物体-文本、文本-物体、文本-文本六种特征,用来在下一步对图进行更新。
2、Question consitioned graph attention module建立和更新图。以文本和物体作为节点建立网络,节点之间连接由相对距离决定。利用上述问题特征在图上进行推理,推断节点的重要性和节点之间的关系。物体-文本的问题特征用来更新物体-文本边,物体的问题特征用来更新物体节点。
3、Global-local attention answering module迭代生成变长答案。问题、物体、文本、局部OCR embedding一起输入,从OCR和固定词汇表中选取回答。
Question Self-Attention Module
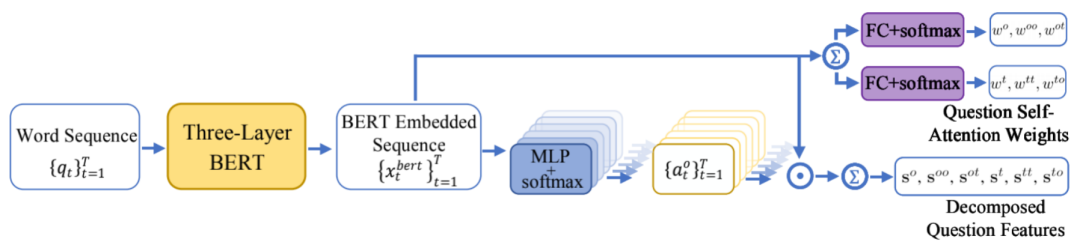
如图,该模块用于将问题序列分解为六种问题特征,并生成自注意力权重,用于下一步运算。
图中t, to, tt, o, ot, oo代表六种特征(节点/边):
object nodes, text nodes;object-object edges, object-text edges, text-object edges, text-text edges
问题的单词序列首先经过三层的BERT进行embedding得到xt序列,然后通过不同运算得到自注意力权重和分解的问题特征。其中自注意力权重由下式计算,仅由问题本身决定,用于下一步计算节点的注意力权重。
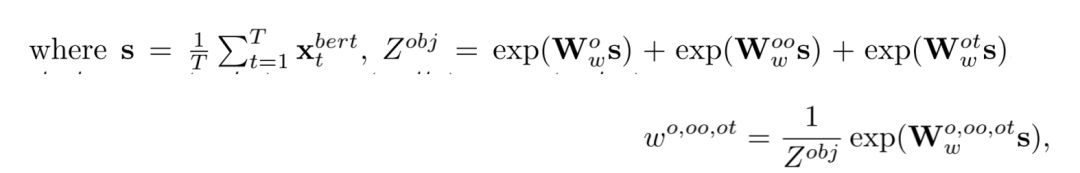
xt经过六个不同的MLP+softmax得到六种注意力权重(对应t, to, tt, o, ot, oo),对原先的xt做加权和,得到分解的问题特征s:
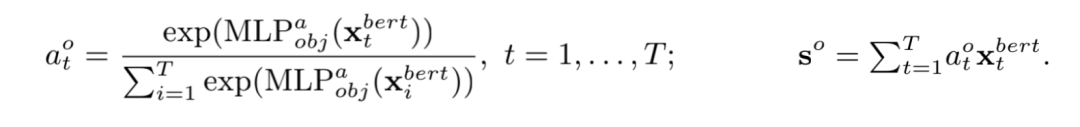
Question Conditioned Graph Attention Module
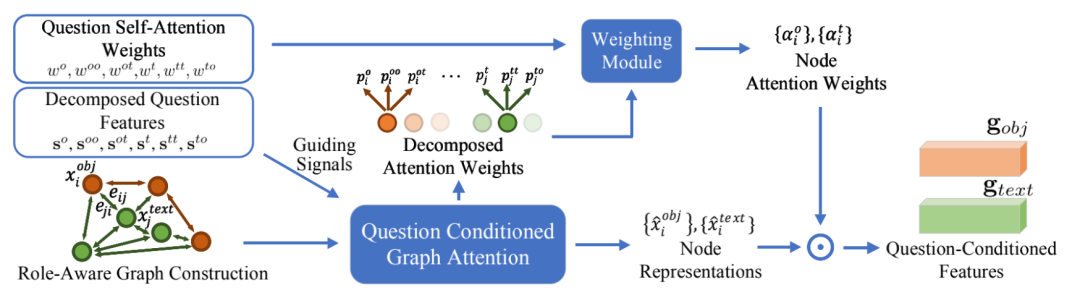
该模块构建图并进行更新,然后加权得到以问题作为条件的物体和文本特征。
Role-aware Heterogeneous Graph Construction

首先建立起异质图,包含物体集O、文本集T、边集E,以空间距离为基础连接边。边eij由节点oi和oj的长宽、维度相关。
Question Conditioned Graph Attention

使用不同的问题特征来更新图的对应部分(例如用Soo更新oo边),六种注意力pm使用不同的方式计算,但整体上都是以物体特征、文本特征、边的特征和上一步中的分解问题特征作为输入进行计算。
物体节点注意力:对于物体i,使用Faster R-CNN的特征和边界框的位置作为输入,经过线性变换、layer norm、利用问题特征进行ReLU、点积、softmax,得到最终的poi。

文本节点注意力:类似于M4C,使用FastText、Faster R-CNN、PHOC、bounding box、RecogCNN的特征作为输入,类似于上述方法得到pot。
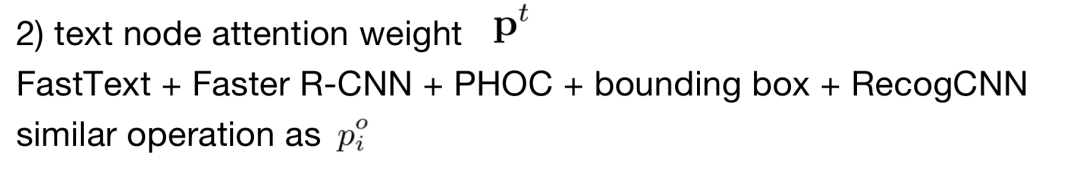
边注意力:对于节点oi的每一条邻边,使用eij和xiobj计算该边的注意力权重qijoo;然后使用qijoo作为权重,xijoo作为输入,经过类似上述方法得到pioo。
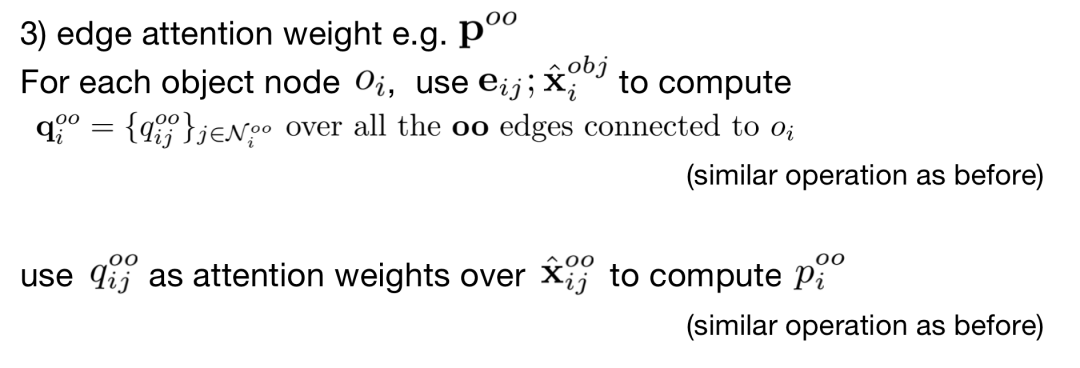
Weighting Module
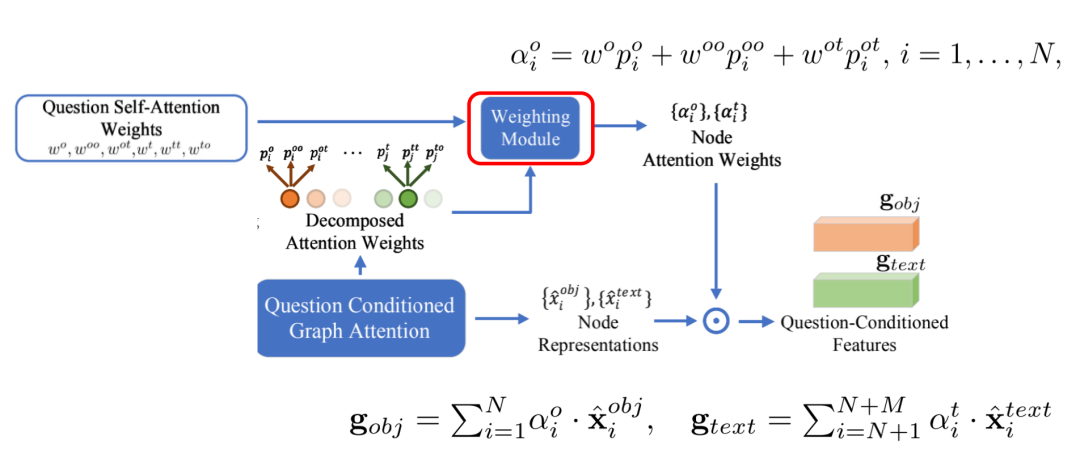
使用第一步计算出的问题自注意力权重作为权重,对分解的注意力权重p进行加权求和,得到每个节点的注意力权重(物体节点使用po、poo、pot,文本节点使用pt、ptt、pto),然后对节点特征做加权和得到最终的图片和文本特征gobj、gtext。
Global-Local Attentional Answering Module
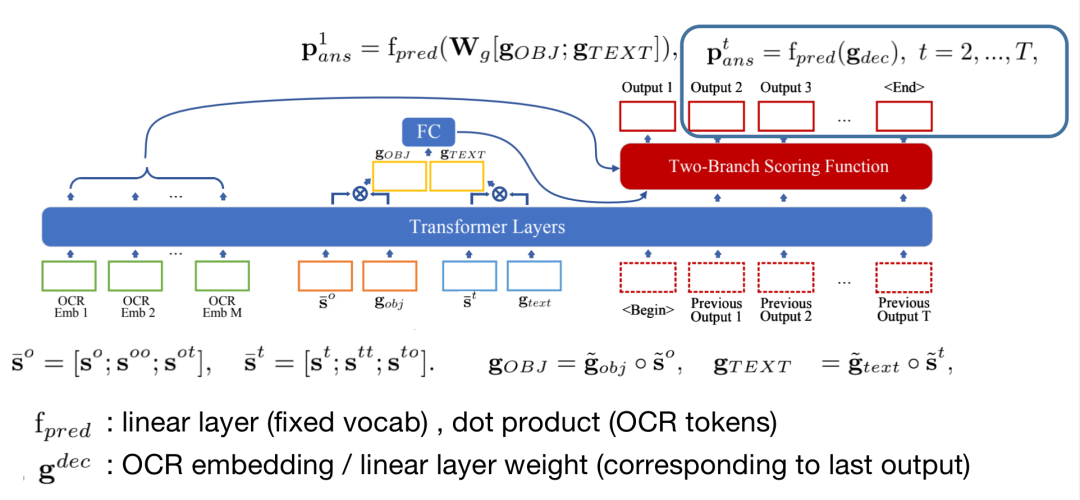
答案预测模块与M4C类似,上一步计算出的文本物体特征g、第一步计算出的分解问题特征s、OCR embedding作为输入,通过transformers进行特征融合。g经过线性变换后通过fpred得到答案的第一个单词,其中fpred是两分支的打分函数(对于固定词汇表使用线性变换层,对于OCR单词使用点积)。
预测出第一个单词后,此后的每个单词仅由前一步的单词作为输入进行计算,即gdec,其值为OCR embedding(若前一个单词来自OCR)或线性层的权重(若前一个单词来自词汇表)。gdec通过transformers后经过打分函数fpred得到这一步的预测单词。
Experiments
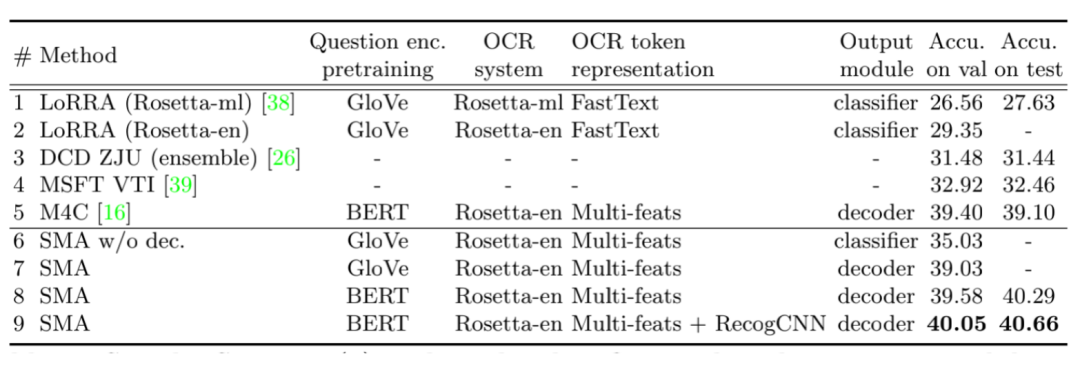
通过ablation study,作者发现将classifier更换为decoder(支持生成多个单词)后精度上升了4%,使用BERT进行embedding后上升了0.5%,增加RecogCNN特征后又上升了1%,最终超过了此前的SoTA M4C的精度。
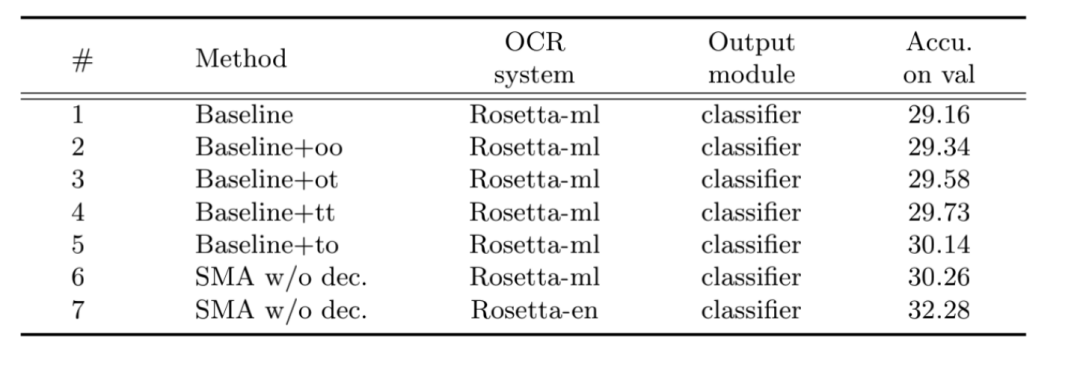
去除Question Conditioned Graph Attention Module后得到baseline,然后在此基础上分别添加oo、ot、tt、to四种关系,结果发现text-object的效果最好,符合对于该任务的直观理解。
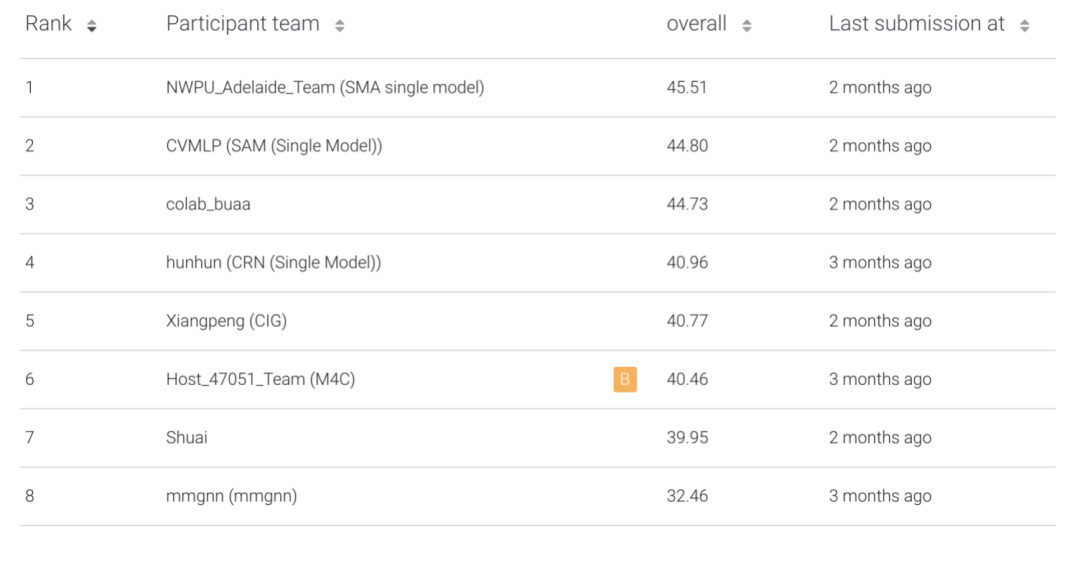
通过多数据集预训练和其他优化,作者团队在TextVQA竞赛中取得冠军。(值得一提的是,我们的队伍取得了季军)
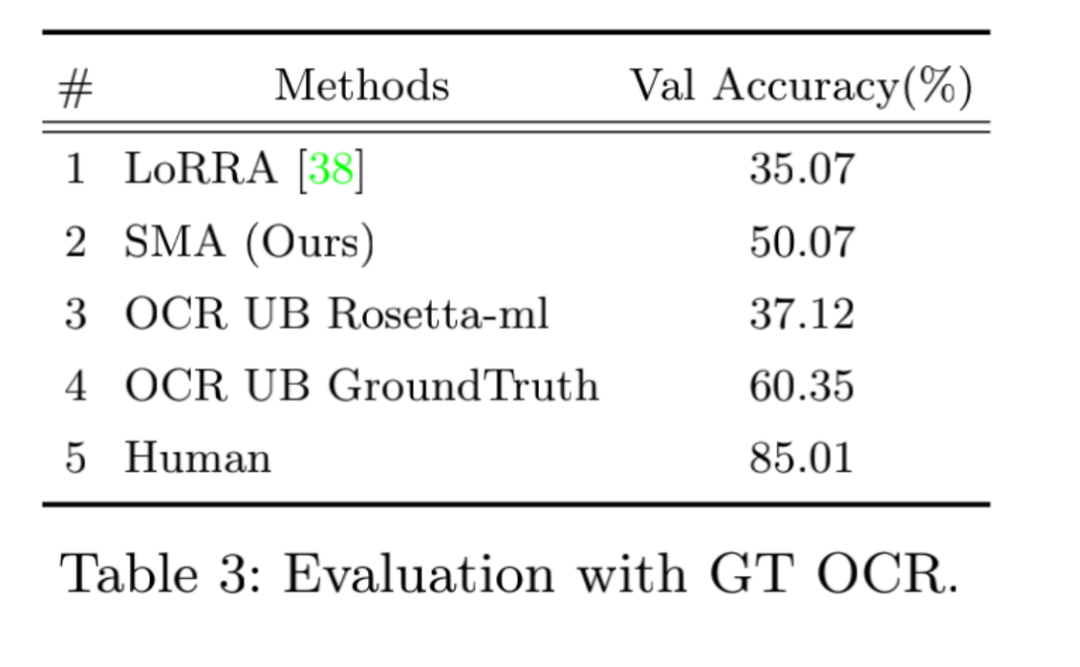
AWT人工标注了所有OCR单词,从而获得了精度的上界,使得可以只研究模型的推理能力而不必考虑OCR识别能力带来的差异。
Visualization
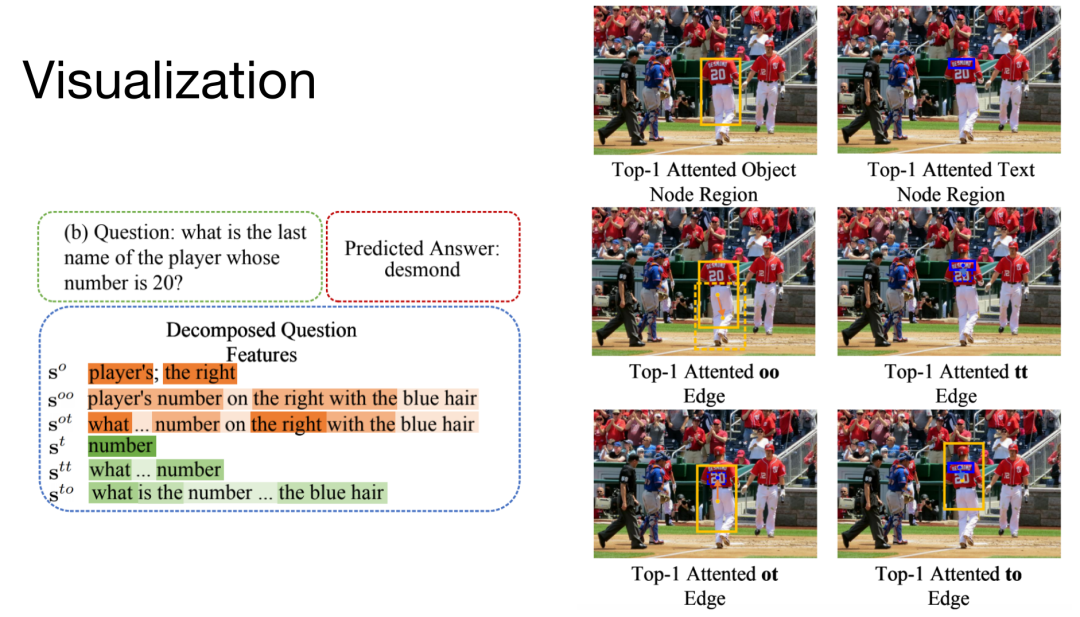
以上是一个可视化效果示例。问题中的物体包括player、right,文本为number。核心的ot关系为player whose number is 20,核心的to关系是last name of player。右图中黄框代表物体节点,蓝框代表文本节点,箭头代表边。实线代表与答案最相关的节点,虚线代表一般节点。

