TextCaps竞赛总结

OCR analysis
我们的模型基于M4C-captioner模型,主要关注OCR的改进。为了直观地了解当前的OCR性能,我们对Rosetta的OCR结果和训练集的参考标题进行了分析,发现在所有字幕中的4006080个单词中,有198295个(4.95%)单词出现在Rosetta的OCR结果中。其余词汇中有2961855个词(73.93%)包含在词汇表中,这意味着剩下的22.04%的词无法用模型进行预测,从而设定了准确度的上限。这说明我们应该重点关注OCR的改进。

Pipeline
我们的模型以M4C-captioner为基础,使用ABCNet和CRAFT进行文本识别,使用四阶段STR框架进行文本识别。利用仿射变换将不规则文本区域调整为矩形。

Text Spotting
我们分别使用CRAFT和ABCNet两个模型进行文本检测。
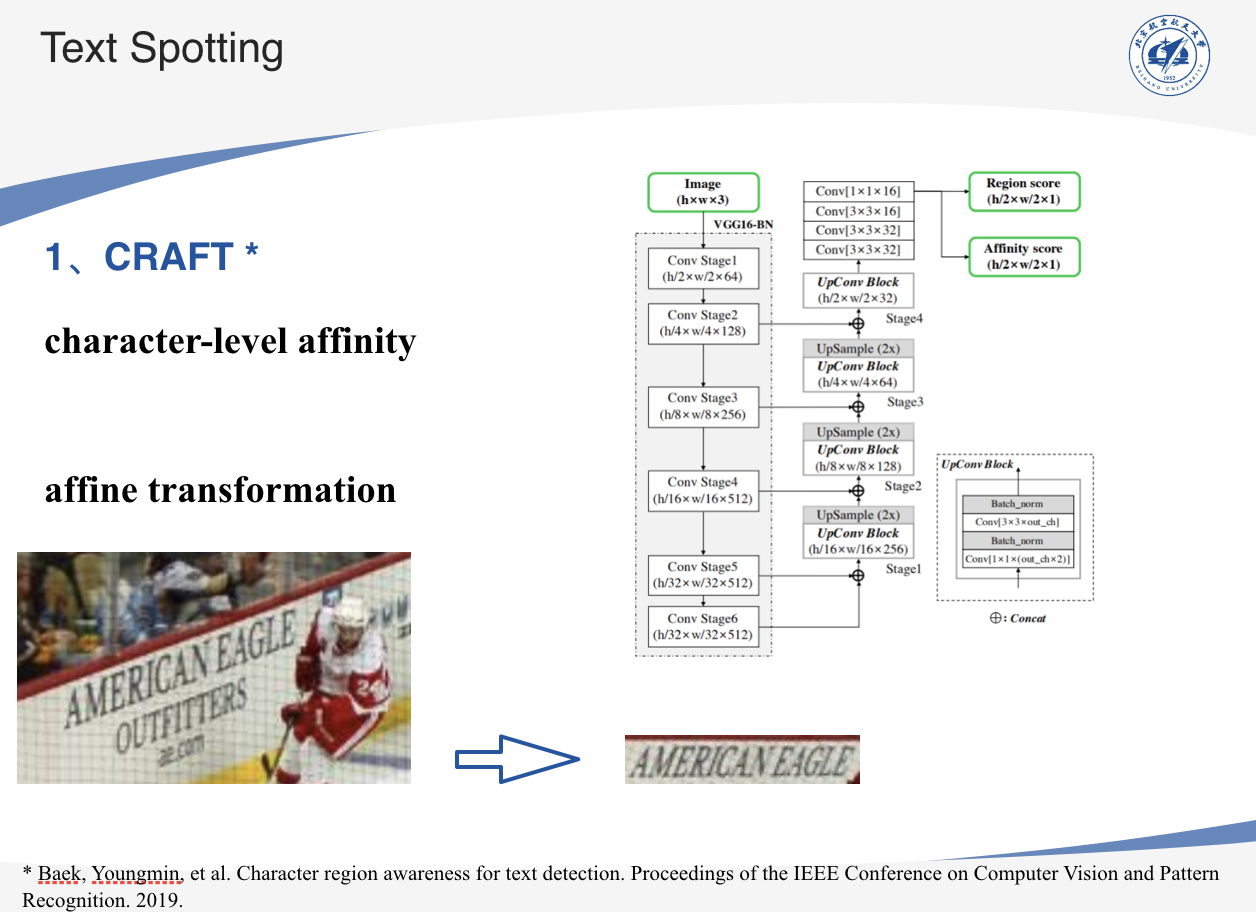
CRAFT
CRAFT可以通过探索字符级的相似度来有效地检测文本区域。利用仿射变换将文本区域的形状调整为规则的矩形。
ABCNet
ABCNet提出了一种利用自适应Bezier曲线拟合任意形状文本的方法。在原有OCR模型Rosetta的基础上,采用预训练的ABCNet模型对文本进行检测,在旋转后和曲线形状的文本上都取得了显著的效果。

Text Recognizing
对于文本识别,我们使用基于四阶段STR框架的深度文本识别基准。首先利用TPS变换将原始图像转化为归一化图像。然后,利用ResNet提取图像的视觉特征,将其重塑为一个序列,并利用BiLSTM捕获上下文信息。最后,模型根据先前的特征预测字符序列。

Results
OCR结果

我们将经过新方法得到的OCR结果与Rosetta的结果进行合并,结果如表格所示,可以看到加入新方法后OCR文本数接近原来的三倍。
测试集结果
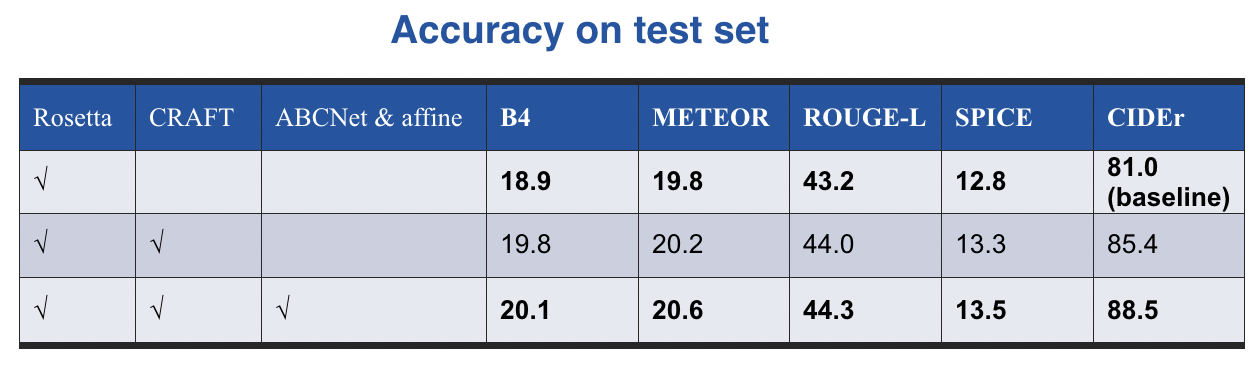
我们在测试集上对新加入的方法进行了实验,结果如上表。相对于baseline的M4C-captioner模型,加入CRAFT后CIDEr增加了4.4%,加入ABCNet和仿射变换后又提高了3.1%。结果表明,新的OCR方法有助于性能的提高。当我们使用所有新的OCR方法(CRAFT、ABCNet和仿射变换)时,可以获得最佳性能。
Future Work
我们也有一些可能在未来起作用的想法。
1、在做预测时考虑OCR的置信度。这是因为自信度越高的词越容易被识别,也越有可能是需要包含在标题中的关键信息。
2、我们还发现在预测的标题中存在重复现象,例如这张幻灯片上的例子。覆盖机制(coverage mechanism)可能有助于避免这种冗余。


