NS-VQA:结合符号推理和神经网络进行视觉问答

原文链接:https://arxiv.org/pdf/1810.02338.pdf
Motivation

本文与上两篇文章相同,即visual reasoning。对于图中问题的回答,人类的推理是清晰而可解释的。visual reasoning希望可以将VQA的推理过程清晰地表现出来。
Structure
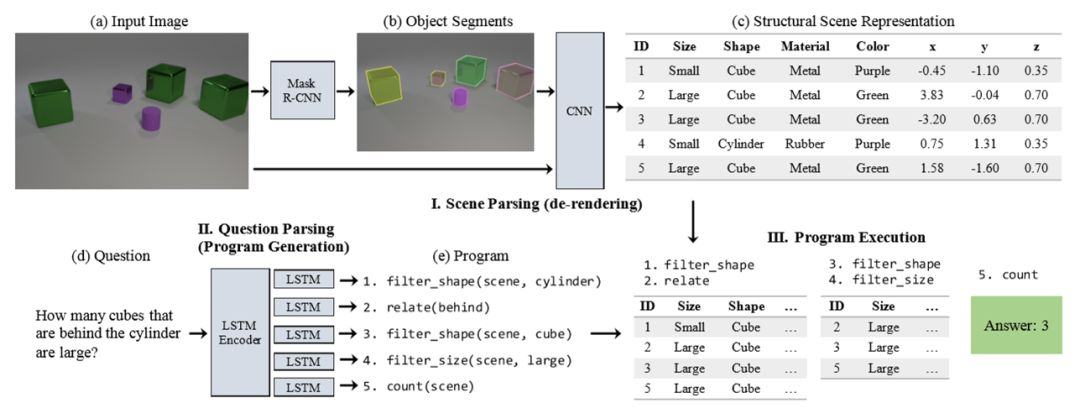
本文的模型包含三个部分。首先,场景解析器(即去渲染器)将输入的图片分割为不同物体(通过Mask R-CNN),然后通过CNN生成结构化的场景描述(即图中的表格,将每个物体的尺寸、形状、材料、颜色、位置进行提取);然后,问题解析器通过LSTM将问题转化为可执行的程序;最后,程序执行器将程序在结构化场景上运行,得到结果。后两个部分类似于上一篇Inferring and Executing Programs中的结构。
Experiments
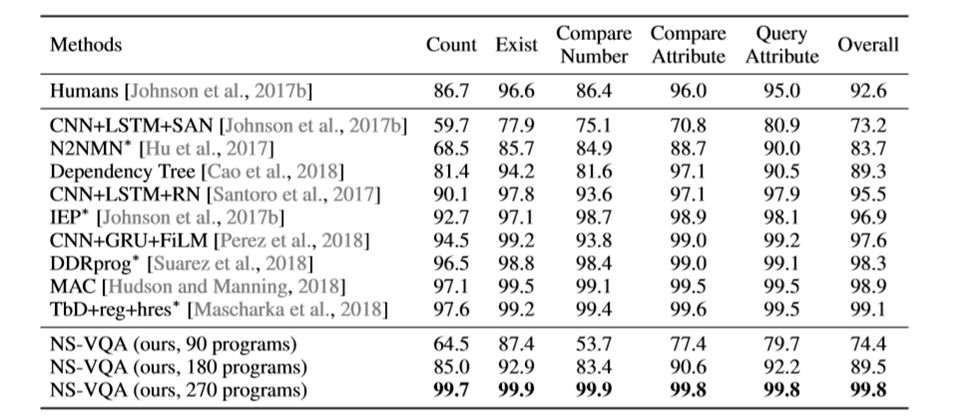
NS-VQA超过了现有的模型的表现,包括上周提到的MAC、IEP等。ground-truth program的数量到270时,准确率可以达到惊人的99.8%,甚至超过了人类的表现。
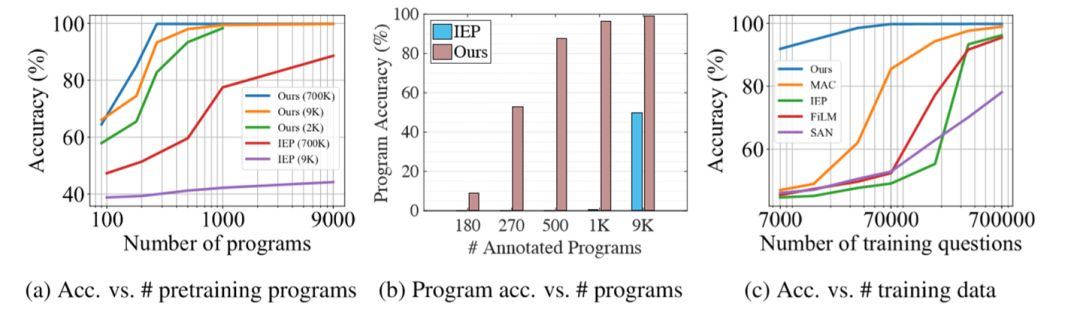

作者对模型的训练过程进行了实验。研究发现,NS-VQA在强化学习只需要大约500个programs即可达到state-of-the-art的准确率,表现出了很高的效率。而在相同的ground-truth program数量和训练数据数量上,NS-VQA超过了现有模型,达到了最佳效果。

作者展示了CLEVR数据集上的定性结果,蓝色代表正确程序/结果,红色代表错误。NS-VQA在程序生成的鲁棒性上超过了IEP的基准。
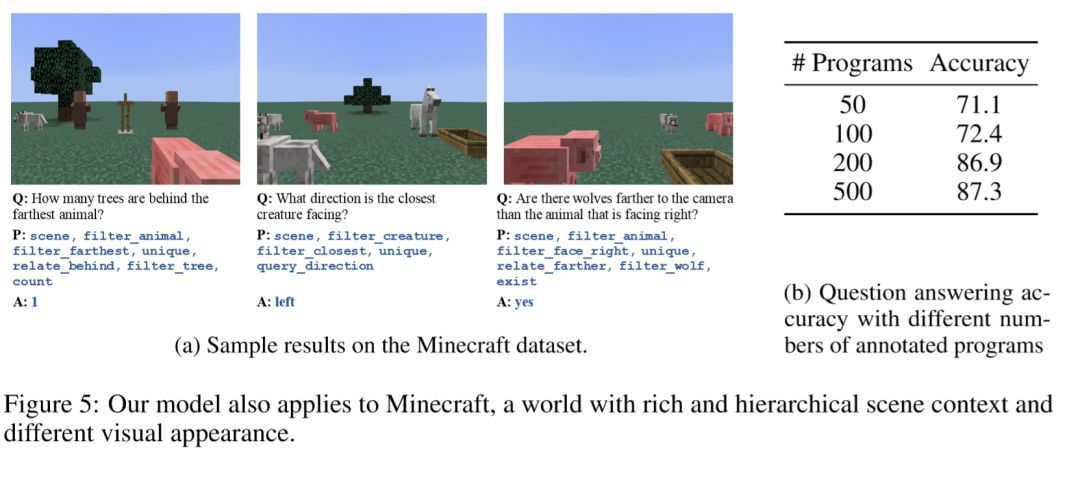
最后,作者还根据Minecraft游戏中的图片生成了一些视觉推理问题,制作为数据集,并在此数据集上进行了训练,测试训练效果。结果表明NS-VQA在Minecraft数据集上仍然可以达到比较好的效果。

