FIFO: 基于自然语言查询的视频检索与定位

原文链接:
http://openaccess.thecvf.com/content_ECCV_2018/papers/Dian_SHAO_Find_and_Focus_ECCV_2018_paper.pdf
Motivation
根据自然语言文本检索视频是当今关键的技术之一。短视频平台的兴起给这项任务带来了更多的挑战:视频的长度和内容多样性显著增加。传统的检索方法将整个视频编码为一个feature vector,忽略了局部的特征,从而不具备根据文本进行时间定位(temporal localization)的能力。
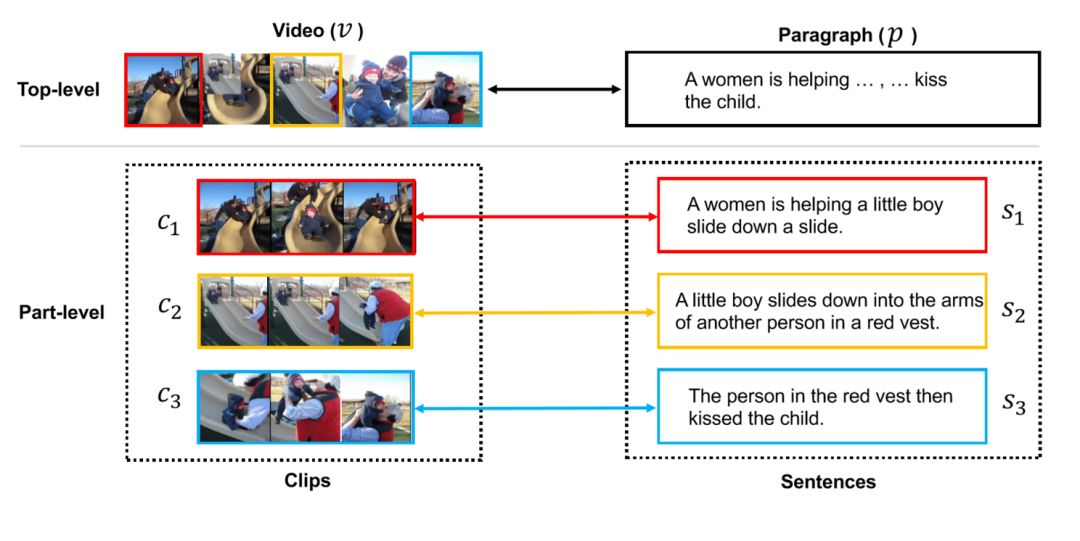
上图解释了全局(Top-level)与局部(part-level)的概念。在全局水平上,一个完整视频与一个文本段落进行匹配;而在局部水平上,段落中的每一句话分别对应于视频中的某一个片段(clip)。
Framework Overview


作者提出了FIFO网络,主要任务是:首先根据文本段落选定一定数量的候选视频(Find,全局),然后对每个候选视频进行片段定位(Clip Localization)以辨别每一句话与视频片段的联系(Focus,局部),最后根据Focus的计算结果调整最初的检索结果。
Clip Localization
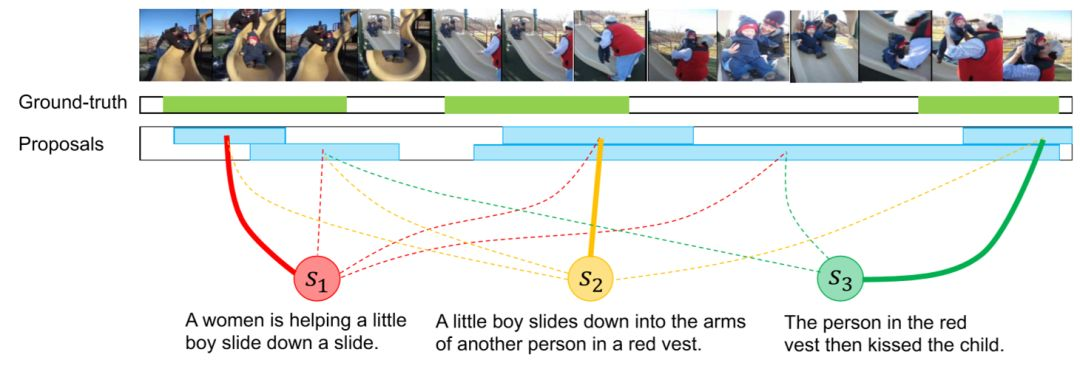
上图展示了片段定位的过程。给定视频与文本,使用一种语义敏感的方法选出候选片段(Clip Proposal).每句话可能与多个片段相联系,其中相关性最大的用粗线表示。
Feature Extraction

视频与文本段落分别用T个snippet(连续6帧的视频小片段)的特征和M个句子的特征表示,通过two-stream CNN产生。
Clip Proposal

对于语句Si和第j个snippet,用夹角的余弦值作为Fj与Si的语义相关度。用这种方法为段落中的每个句子选定与其相关的snippet,连续的一些snippet成为一个clip,由此产生候选的一系列clip。
Cross-domain Matching
如图,目标为最大化左边的式子,其中Xij是语句i和片段j是否相关(待优化的目标参数),Rij是语句i和片段j的语义相关性。
优化Xij时需满足两个条件:(1)每个特定语句至多与Umax个片段相关;(2)每个片段最多与一句话相关。
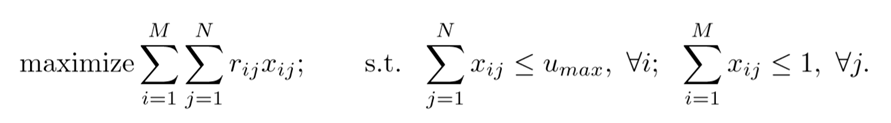
Rij由下图左式定义,其中Gj为视频片段j的特征,由右式定义,Cj为当前片段中的snippet集合,Ft为第t个snippet的特征。
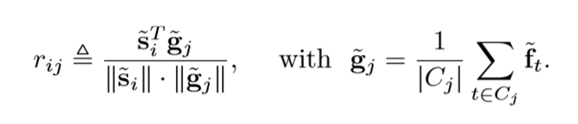
本部分中的优化目标得分称为Sp(V,P),是part-level的相关度。
FIFO
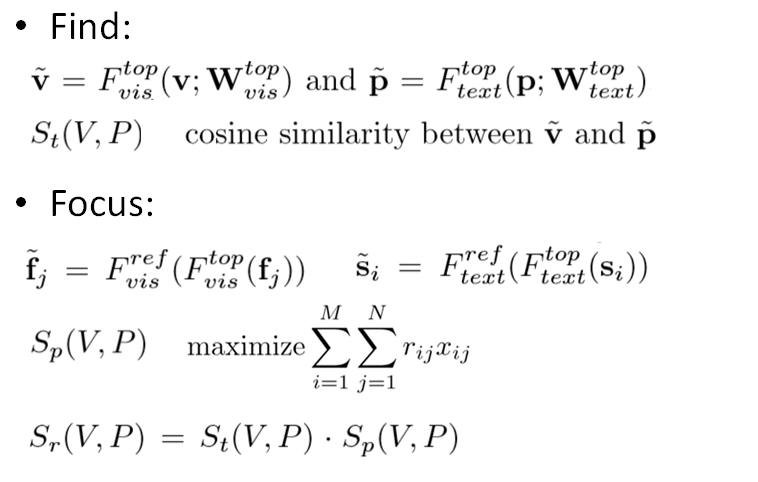
下面介绍FIFO网络的整体结构。在top-level的Find部分,对于视频v和段落p,使用F_top_vis和F_top_text两个网络进行embedding得到特征v~和p~。Top-level的优化目标得分St(V,P)设定为v~与p~的夹角余弦值。
在part-level对特征进行调整,为此训练了网络F_ref_vis和F_ref_text,然后将得到的fj~与si~代入到上一部分的Sp(V,P)表达式中进行优化。最后,将top-level的优化目标调整为Sr(V,P),定义为前面两个优化目标分数的乘积,从而对Find的结果进行调整。
其中,用作embedding的网络通过优化下面的损失函数来训练。α和β作为超参数,分别设定为0.2和0.1。c+为IoU大于0.7的任一候选片段,L为IoU小于0.3的负样本数量,St与sr均为余弦相似度。
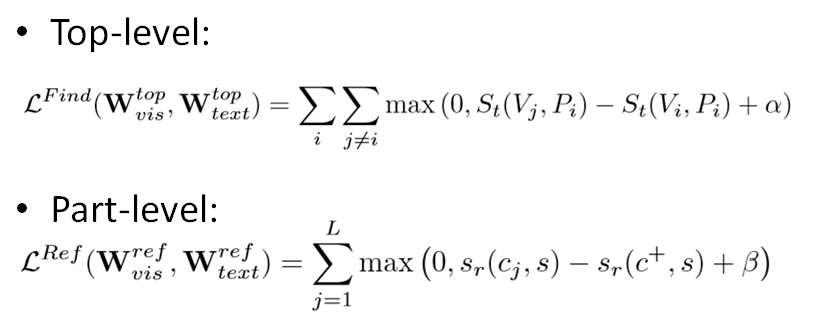
Experiments
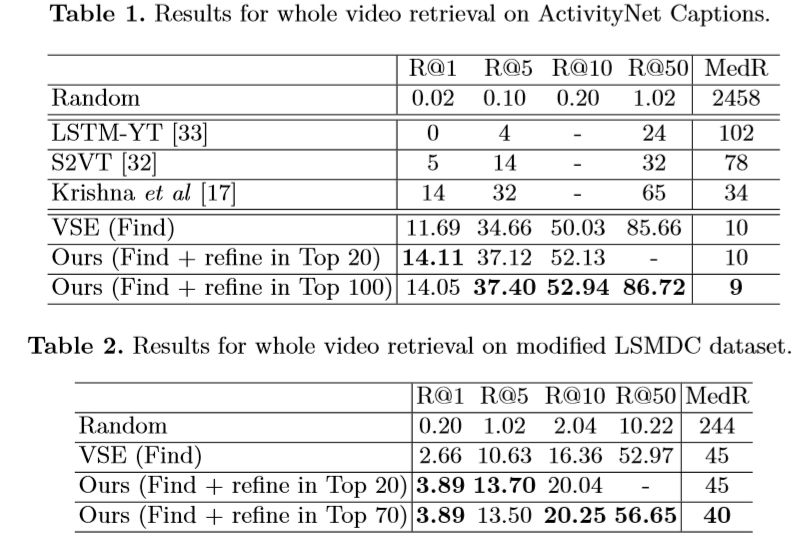
在ActivityNet Captions和LSMDC两个数据集上,作者将FIFO网络与同期其他模型以及未经过refine步骤的(即只进行了Find)的模型的top-level效果进行比对。其中R@N代表(经过多次实验)前N个候选片段中ground-truth样本的比例,MedR代表ground-truth样本的排序的中位数。
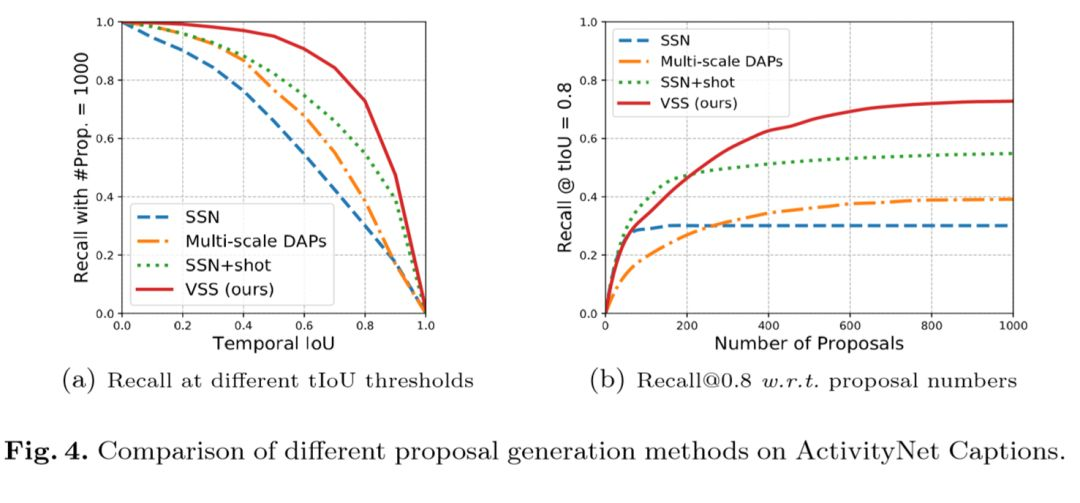
作者随后评估了他们的候选区域生成方法(visual semantic similarity, VSS)的效果。左图表示了不同IoU阈值下,不同模型的召回率。右图表示随着候选数量的增加,召回率的变化趋势。可见VSS的效果超过了其他模型。
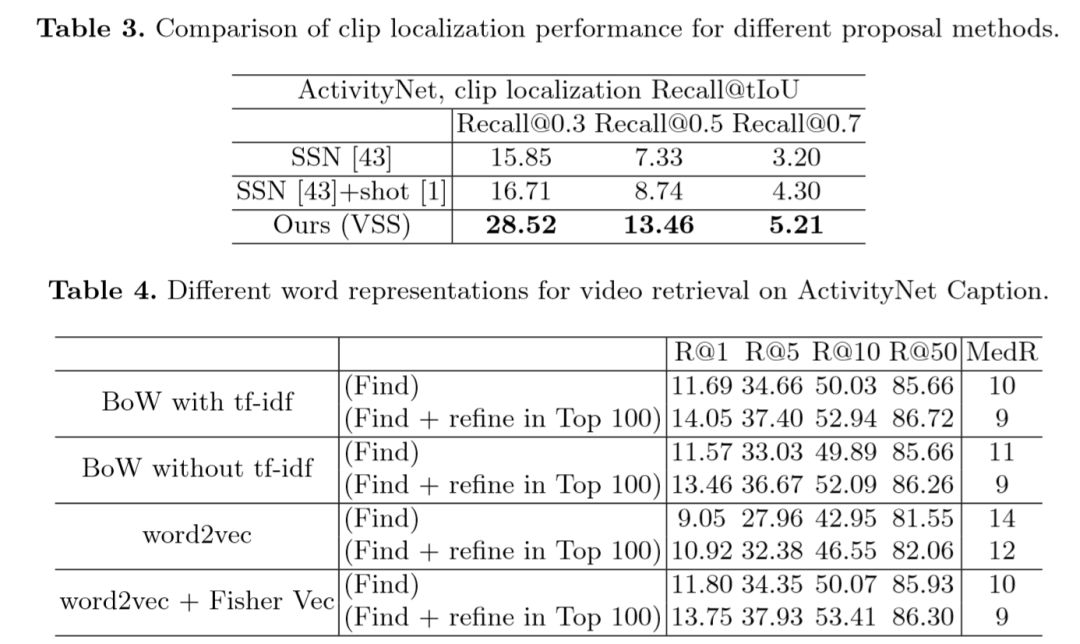
在表3中,作者比较了不同候选区域生成方法的效果,VSS取得了最好的成绩。表4中比较了不同的文本embedding方法的效果,可见Fisher Vector以及tf-idf带来了更好的效果。
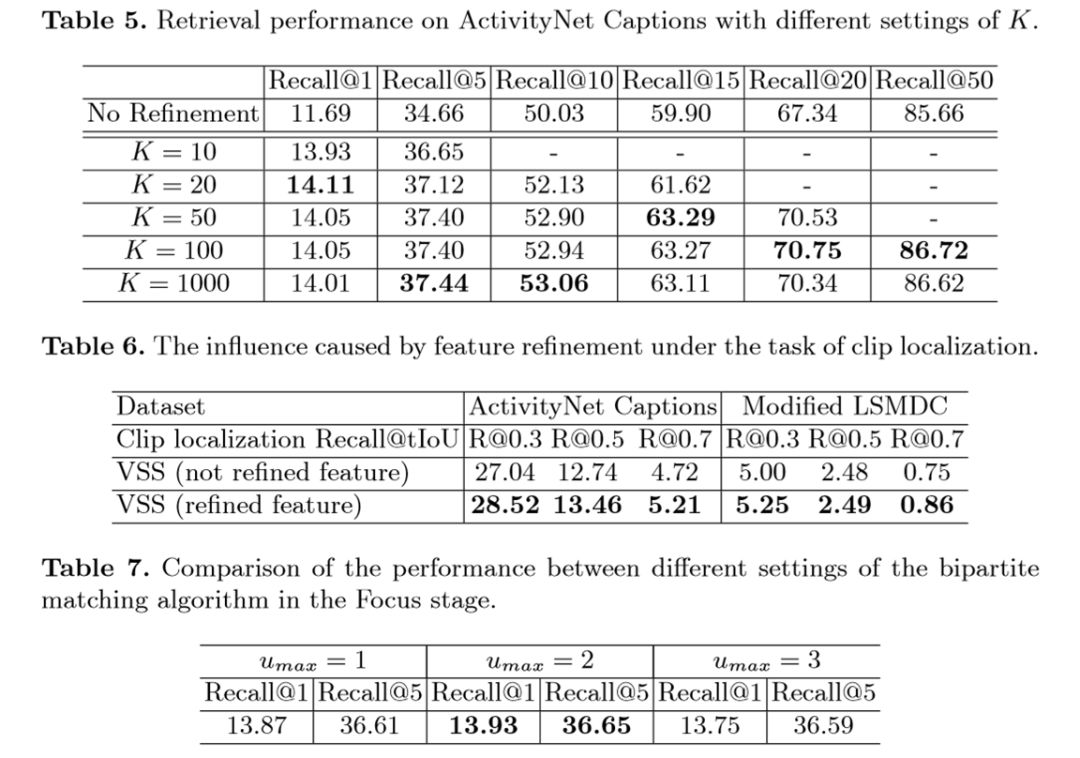
表5显示了超参数K对召回率的影响。K代表在Find步骤中产生的候选视频的数量。更大的K通常能带来更好的效果,但也会产生更大的计算成本。实验发现随着K增大,召回率逐渐趋于饱和。
表6显示了Focus步骤中调整特征(利用F_ref_vis和F_ref_text)带来了更好的效果。
表7比较了Clip Proposa步骤中不同Umax值的效果,在Umax=2(即一个语句最多与两个视频片段相关)时召回率最高。
Qualitative Results

最后作者展示了片段定位的量化效果,不同片段用不同颜色表示。第一个样例中结果较为准确,第二个样例中红色片段出现了偏差。

