

centos7配置hadoop3.1.2
本以为照着网上的教程不会出错,还是弄了2天才搞好。
根据上一篇 vmware10配置jkd ssh免密 ,现在直接配置hadoop,我选择的是hadoop3.1.2
1.下载地址
2.通过ssh命令工具,上传到master主机,我上传到root/目录下
3.host配置,让可以通过主机名称来访问。
vim /etc/hosts
#修改完后 立即生效(如果出现command not found 忽略)
. /etc/hosts
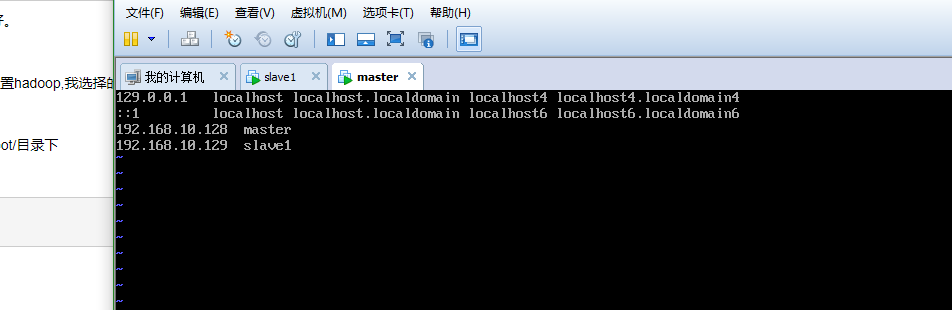
如图是我增加的2台机器。 192.168.10.128 作为master主机,192.168.10.129作为slave机器。当前配置的机器为mater
4.复制这个配置到slave1机器(当前由于slave1机器还没有上一步的操作,只能用ip名复制)
scp -r /etc/hosts root@192.168.10.129:/etc/hosts/
经过了这一步,就可以在master机器上以slave1来访问192.168.10.129的机器了
5.解压hadoop并配置
cd /root tar -xvf hadoop-3.1.2 #生成软链接 ln -sf hadoop-3.1.2 hadooop
#配置环境
vim /etc/profile
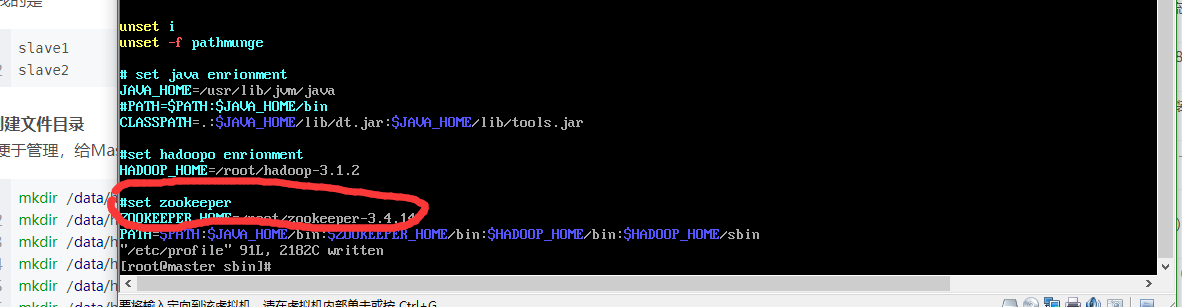
划红线内的不用管
还有一个地方要配置:
vim /root/hadooop/etc/hadoop/hadoop-env.sh
结尾处如图,加:export JAVA_HOME=/usr/lib/jvm/java

6.hadoop配置文件
先创建文件目录
mkdir /data/hdfs/tmp mkdir /data/hdfs/var mkdir /data/hdfs/logs mkdir /data/hdfs/dfs mkdir /data/hdfs/data mkdir /data/hdfs/name mkdir /data/hdfs/checkpoint mkdir /data/hdfs/edits
cd /root/hadoop-3.1.2/etc/hadoop
依次修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml以及workers文件。
a.core-site.xml

<property> <name>fs.checkpoint.period</name> <value>3600</value> </property> <property> <name>fs.checkpoint.size</name> <value>67108864</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/data/hdfs/tmp</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property>
b.hdfs-site.xml
<property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/data/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/data/hdfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <property> <name>dfs.namenode.http-address</name> <value>master:50070</value> <description> The address and the base port where the dfs namenode web ui will listen on. If the port is 0 then the server will start on a free port. </description> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>/data/hdfs/checkpoint</value> </property> <property> <name>dfs.namenode.checkpoint.edits.dir</name> <value>/data/hdfs/edits</value> </property>
c.mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tarcker</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property>
d.yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandle</value> </property> <property> <name>yarn.resourcemanager.resource-tarcker.address</name> <value>master:8025</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8040</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property>
7.把master上配置好的hadoop复制到slave1机器 (每台机器上都要配置hadoop哦)
scp -r /root/hadoop-3.1.2 root@slave1:/root/
#还有环境变量
scp -r /etc/profile root@slave1:etc/profile/
8.关掉防火墙
由于hadoop中的程序都是网络服务,需要监听端口,这些端口默认会被linux防火墙挡住。因此要把hadoop中的端口一个个打开,或者把防火墙关掉。由于都是内网,所以关掉就好了。
sudo firewall-cmd –state 查看防火墙状态 如果是running表示是开启的
sudo systemctl stop firewalld.service 关闭防火墙 再查看应该是not running 就是 已经关闭了。但在下一次开机时还会自启动,因此 sudo systemctl disable firewalld.service 禁止开机时防火墙自启。
9.启动hadoop
#先格式化(每台机器都做)
hdfs namenode –format
#如果环境变量没有配置好,则
cd /root/hadoop/sbin/
./start-all.sh
我的机子出现了错误:

分别编辑开始和关闭脚本
vim sbin/start-yarn.sh
vim sbin/stop-yarn.sh
在顶部空白处添加内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
还有一个hdfs的错误,同理修改
vim sbin/start-yarn.sh
vim sbin/stop-yarn.sh
都加入如下:
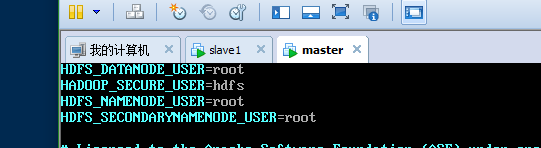
这里编辑好了之后,也要拷贝到slave1机器
cd /root/hadoop/sbin/ scp -r start-dfs.sh root@slave1:/root/hadoop/sbin/ scp -r stop-dfs.sh root@slave1:/root/hadoop/sbin/ scp -r start-yarn.sh root@slave1:/root/hadoop/sbin/ scp -r stop-yarn.sh root@slave1:/root/hadoop/sbin/
#重新启动 ./stop-all.sh ./start-all.sh jps
master:
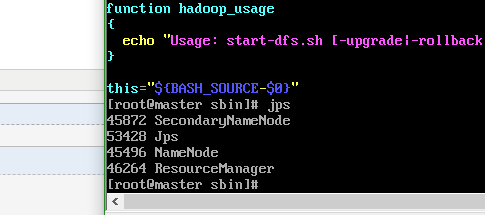
slave1:

如此就大功告成了。
测试:http://192.168.10.128:50070
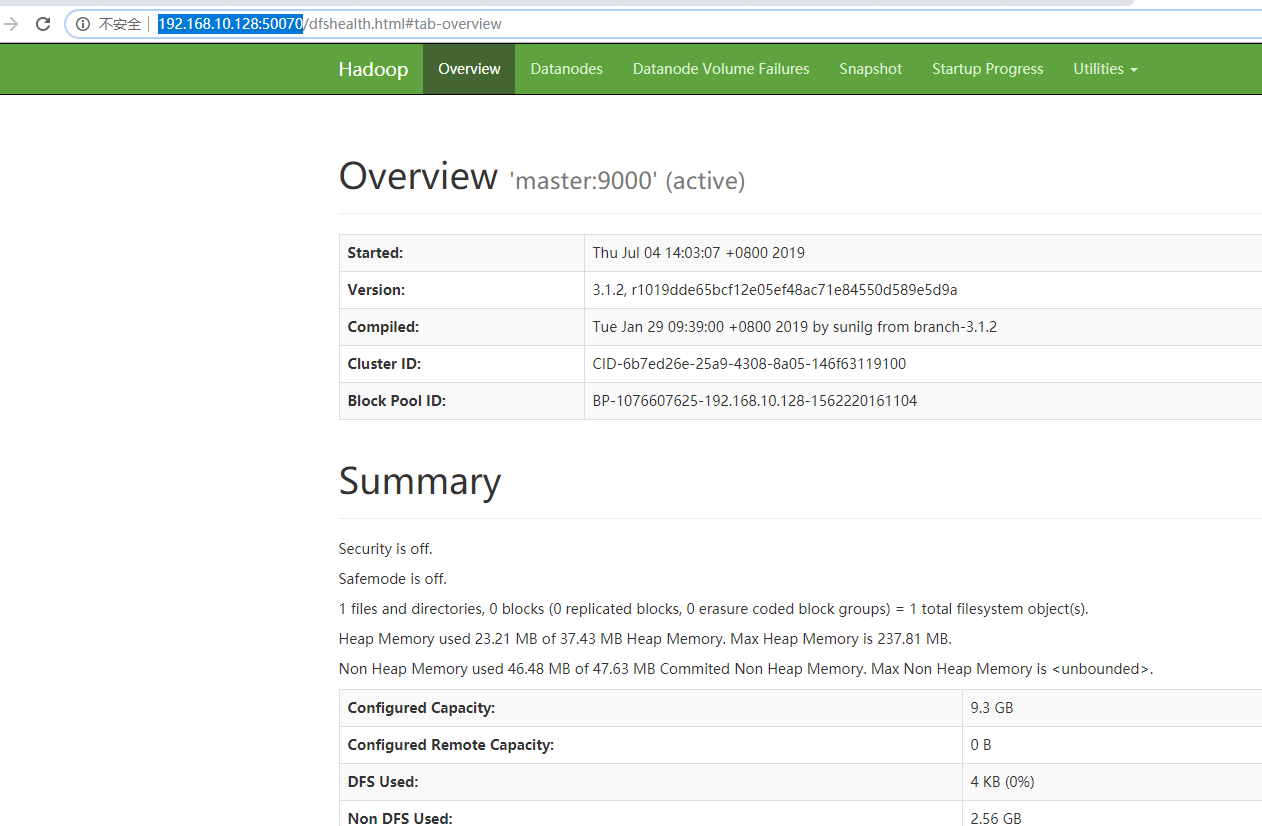
注意:我之前在网上看到hdfs-site.xml的配置,里面有这样的配置:<value>file:/data/hdfs/data</value>,结果发现namenode一直启动不了
后面去查看日志:
cd /root/hadoop/logs tail -f 100 hadoop-root-namenode-master.log
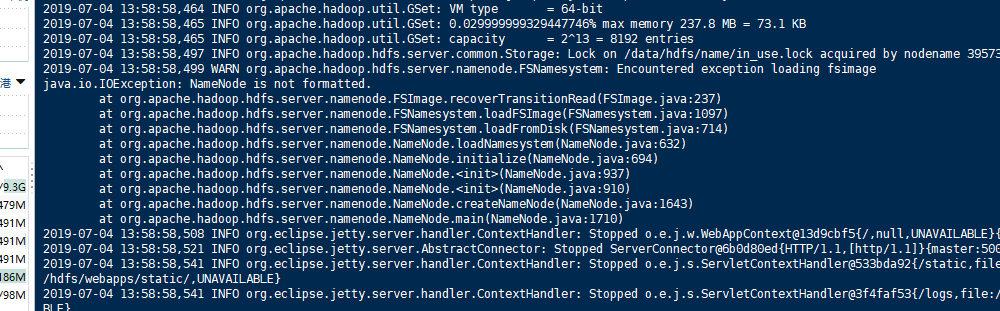
namenode格式化不成功。
修改后:<value>/data/hdfs/data</value>
重新格式化:hdfs namenode –format
重启就可以了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!