HDFS 机架感知与副本放置策略
HDFS 机架感知与副本放置策略
机架感知(RackAwareness)
通常,大型 Hadoop 集群会分布在很多机架上,在这种情况下,
- 希望不同节点之间的通信能够尽量发生在同一个机架之内,而不是跨机架。
- 为了提高容错能力,名称节点会尽可能把数据块的副本放到多个机架上。
综合考虑这两点的基础上 Hadoop 设计了机架感知功能
外在脚本实现机架感知
HDFS 不能够自动判断集群中各个 DataNode 的网络拓扑情况。这种机架感知需要 net.topology.script.file.name 属性定义的可执行文件(或者脚本)来实现,文件提供了 DataNode 的IP 地址与机架 rackid 之间的映射关系。NameNode 通过这个映射关系,获得集群中各个 DataNode 机器的机架 rackid。如果 topology.script.file.name 没有设定,则每个 DataNode 的 IP地址都会默认映射成 default-rack,即可同一个机架。
为了获取机架 rackid,可以写一个小脚本来定义 DataNode 的 IP 地址(或DNS域名),并把想要的机架 rackid 打印到标准输出 stdout
这个脚本必须要在配置文件 hadoop-site.xml 里通过属性 ’net.topology.script.file.name’ 来指定。
<property>
<name>net.topology.script.file.name</name>
<value>/root/apps/hadoop-3.2.1/topology.py</value>
</property>
用 Python 语言编写的脚本范例:
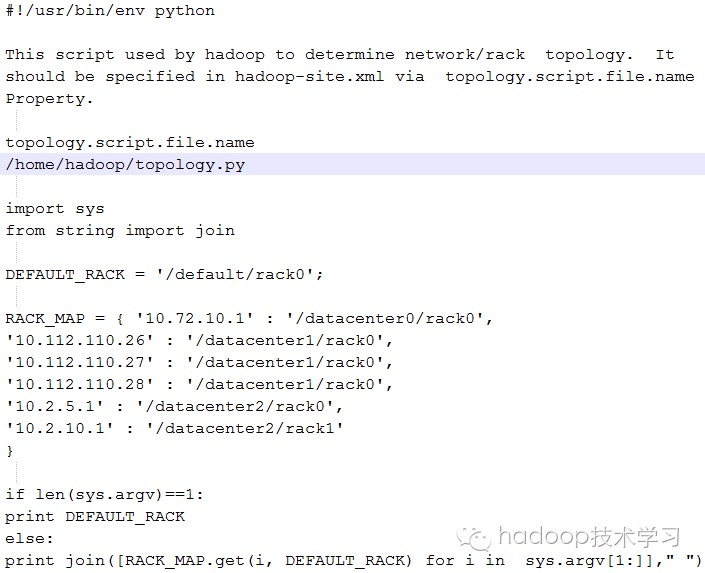
内部Java类实现机架感知
该处采用配置 topology.node.switch.mapping.impl 来实现机架感知,需在 core-site.xml 配置文件中加入以下配置项:
<property>
<name>topology.node.switch.mapping.impl</name>
<value>com.dmp.hadoop.cluster.topology.JavaTestBasedMapping</value>
</property>
还需编写一个JAVA类,一个示例如下所示:
public class JavaTestBasedMapping implements DNSToSwitchMapping {
//key:ip value:rack
private staticConcurrentHashMap<String,String> cache = new ConcurrentHashMap<String,String>();
static {
//rack0 16
cache.put("192.168.5.116","/ht_dc/rack0");
cache.put("192.168.5.117","/ht_dc/rack0");
cache.put("192.168.5.118","/ht_dc/rack0");
cache.put("192.168.5.120","/ht_dc/rack0");
cache.put("192.168.5.121","/ht_dc/rack0");
cache.put("host116","/ht_dc/rack0");
cache.put("host117","/ht_dc/rack0");
cache.put("host118","/ht_dc/rack0");
cache.put("host120","/ht_dc/rack0");
cache.put("host121","/ht_dc/rack0");
}
@Override
publicList<String> resolve(List<String> names) {
List<String>m = new ArrayList<String>();
if (names ==null || names.size() == 0) {
m.add("/default-rack");
return m;
}
for (Stringname : names) {
Stringrack = cache.get(name);
if (rack!= null) {
m.add(rack);
}
}
return m;
}
}
将上述Java类打成jar包,加上执行权限;然后放到$HADOOP_HOME/lib目录下运行。
网络拓扑(NetworkTopology)
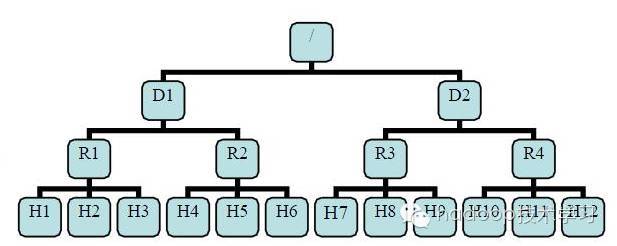
有了机架感知,NameNode 就可以画出上图所示的 DataNode 网络拓扑图。D1,R1都是交换机,最底层是 DataNode。则H1 的 rackid=/D1/R1/H1,H1 的 parent 是R1,R1 的是 D1。这些机架 rackid 信息可以通过 net.topology.script.file.name配置。有了这些机架 rackid 信息就可以计算出任意两台 DataNode 之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
副本放置策略(BPP:blockplacement policy)
- 第一个 block 副本放在和客户端所在的 node 里(如果client不在集群范围内,则这第一个node是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node)。
- 第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
- 第三个副本和第二个在同一个机架,随机放在不同的node中。
如果还有更多的副本,则在遵循以下限制的前提下随机放置。
- 1个节点最多放置1个副本
- 如果副本数少于2倍机架数,不可以在同一机架放置超过2个副本
当发生数据读取的时候,NameNode 节点首先检查客户端是否位于集群中。如果是的话,就可以按照由近到远的优先次序决定由哪个 DataNode 节点向客户端发送它需要的数据块。也就是说,对于拥有同一数据块副本的节点来说,在网络拓扑中距离客户端近的节点会优先响应。
Hadoop 的副本放置策略在可靠性(block 在不同的机架)和带宽(一个管道只需要穿越一个网络节点)中做了一个很好的平衡。
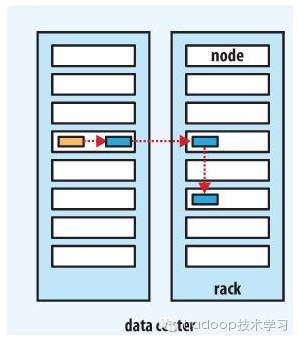
下图是副本数量为3的情况下一个管道的三个 DataNode的分布情况