HDFS 简介
HDFS 简介
集群与分布式
集群
- 集群是由多个完成相同功能的服务器节点组成的集合
- 集群中每个服务器节点处理相同的任务或存储相同的数据
- 集群的关键特性是可扩展性和高可用性(支持负载均衡、错误恢复)
分布式
- 分布式是将一个系统拆分为多个不同的子系统,每个子系统运行在一个服务器节点上,最终共同完成系统的功能
- 分布式中每个服务器节点处理不同的任务或存储不同的数据
- 分布式的关键特性是高性能和高可靠性
分布式软件系统上运行的单个服务器节点可以通过搭建集群,从而获得系统的高性能、高可靠、可扩展和高可用的特性。
HDFS 是什么
HDFS 即 分布式文件系统(Hadoop Distributed File System),是 Hadoop 三大核心组件之一,它的设计目标是把超大数据集存储到网络中的多台普通商用计算机上, 并为大数据分布式运算框架提供高可靠性和高吞吐率的数据存储服务。
分布式文件系统要比普通磁盘文件系统复杂, 因为它要引入网络编程: 分布式文件系统要容忍节点失效,这也是一个很大的挑战,HDFS 出色完成了这一任务
HDFS 设计六大目标
-
可以存储超大文件
HDFS 支持 GB 级别大小的文件,它能够将文件分块存储,通过扩展更多节点增大其存储容量
-
适用于流式的数据访问
HDFS 适用于批处理的情况而不是交互式处理,它的重点是保证高吞吐量而不是低延迟的用户响应
-
高容错性
HDFS 有完善的冗余备份机制
-
支持简单的一致性模型
HDFS 需要支持一次写入多次读取的模型,而且写入过文件不会经常变化
-
移动计算优于移动数据
HDFS 提供使应用计算移动到离它最近数据位置的接口
-
异构软硬件平台间的可移植性
HDFS 在设计时考虑到平台的可移植性,以方便 HDFS 作为大规模数据应用平台的推广
HDFS 整体工作机制
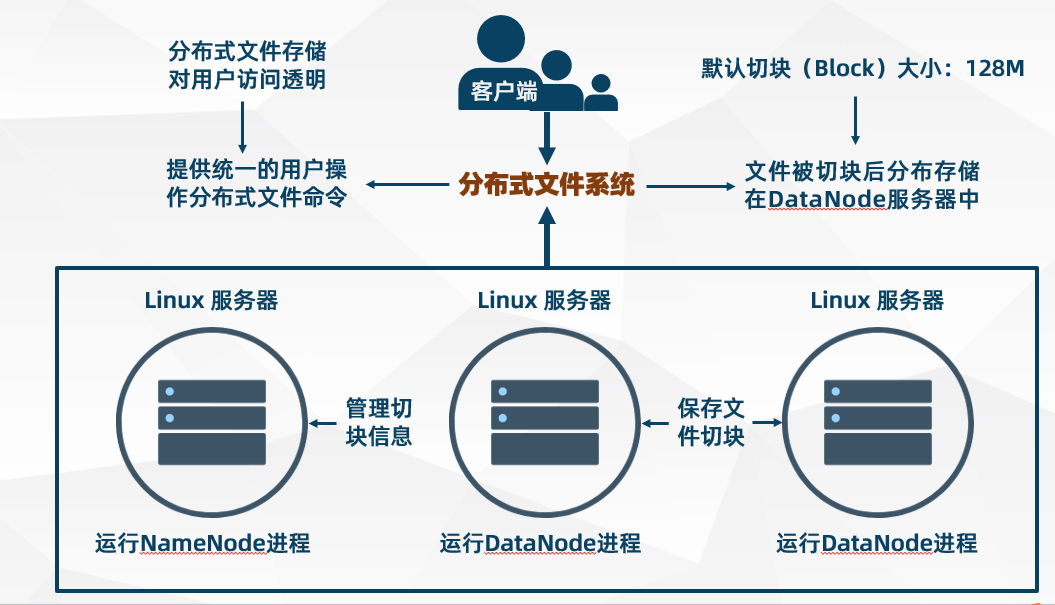
- HDFS 是一个文件系统,用于存储和管理用户上传的文件
- HDFS 是分布式的,由很多服务器联合起来组成集群实现其功能,集群中的服务器分为两大角色:NameNode 服务器 和 DataNode 服务器
- HDFS 采用的是主/从架构:NameNode 是 HDFS 集群的主节点,而 DataNode 是 HDFS 集群的从节点
HDFS 特征
- HDFS 文件系统对客户端访问提供统一的抽象目录树,客户端通过目录树路径来访问文件( 类似 Linux 文件系统 )
- HDFS 中的文件在物理上是分块存储(block),块的大小在 hadoop3.x 版本中默认 128M(通过配置参数 dfs.blocksize 可设置)
- NameNode 负责维护和管理 HDFS 抽象目录树及文件分块(block)的描述信息(元数据)
- DataNode 负责存储和管理文件分块(block),而且每一个文件分块(block)都可以在多个 DataNode 上存储多个副本,副本数量在 hadoop3.x 版本中默认 2 个 (通过参数 dfs.replication 可设置)
- HDFS 设计成适应一次写入、多次读出的场景,且不支持文件的修改
HDFS 优点与不足
HDFS 优点
- 高容错性
- 适合离线批处理
- 适合大数据处理
- 可构建在廉价机器上
HDFS 不足
-
不擅长低延时数据访问
由于 hadoop 针对高数据吞吐量做了优化,牺牲了获取数据的延迟,所以对于低延迟访问数据的业务需求不适合HDFS
-
不擅长大量小文件存储
存储大量小文件的话,它会占用 NameNode 大量的内存来存储文件、目录和块信息,容易导致 NameNode 内存不足
-
不支持多用户并发写入一个文本
同一时间内只能有一个用户执行写操作
-
不支持文件随机修改(多次写入,一次读取)
仅支持文件的数据追加,不支持文件的随机修改
