MongoDB 聚合管道
MongoDB 聚合管道
为什么需要聚合
一般查询可以通过 find() 方法,但如果是比较复杂的查询或者数据统计的话,find() 方法可能就无能为力,这时需要聚合(aggregate)。
聚合操作处理数据文档并返回计算结果。聚合操作将来自多个文档的值分组在一起,可以对分组的数据执行各种操作以返回单个结果。
MongoDB 提供了三种执行聚合的方法:
- 聚合管道
- map- reduce 函数
- 单一目的聚合方法
什么是聚合管道(aggregation pipeline)
聚合管道可以对数据文档进行变换和组合。聚合管道是基于数据流概念,数据进入管道经过一个或多个 stage,每个 stage 对数据进行操作(筛选,投射,分组,排序,限制或跳过)后输出最终结果。
聚合管道语法
db.collection.aggregate(pipeline, options)
- pipeline:数组类型
注:聚合管道可以对分片集合进行操作
Pipeline 管道
db.collection.aggregate( [ { <stage> },... ] )
MongoDB 聚合管道由多个 stage 阶段组成。每个 stage 阶段在文档通过管道时转换文档。管道阶段可以在管道中出现多次。
聚合管道原理
db.collection.aggregate([]) 是聚合管道查询使用的方法,参数是数组,每个数组元素就是一个stage,stage 中运用操作符对数据进行处理后再交由下一个stage,直到没有下个stage,就输出最终的结果,而数据的处理则是通过使用管道操作符。
什么是管道操作符
mongoDB 有 4 类操作符用于文档的操作(操作符以 $ 开头)
- 查询操作符
- 更新操作符
- 管道操作符(聚合管道中的操作符)
- 查询修饰符
在 aggregate 中每个 stage 可以使用的操作符叫做管道操作符
管道操作符分类
- 阶段操作符(Stage Operators)
- 表达式操作符(Expression Operators)
- 累加器(Accumulators)
阶段操作符
db.collection.aggregate( [ { 阶段操作符:表述 }, { 阶段操作符:表述 }, ... ] )
| 阶段操作符 | 操作符名称 | 说明 |
|---|---|---|
| $count | 统计操作符 | 用于统计文档的数量 |
| $group | 分组操作符 | 用于对文档集合进行分组 |
| $limit | 限制操作符 | 用于限制返回文档的数量 |
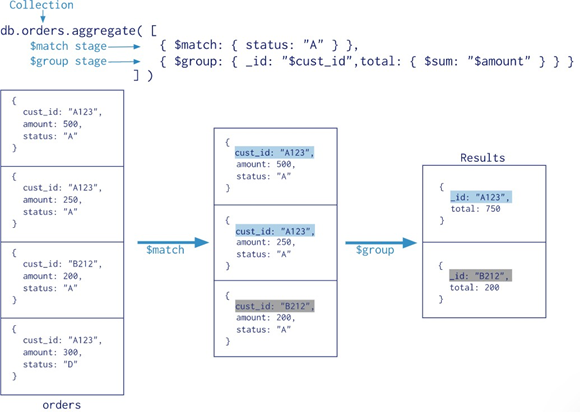
| $match | 匹配操作符 | 用于对文档集合进行筛选 |
| $out | 输出操作符 | 将聚合管道的结果文档写入集合。要使用 $out阶段,它必须是管道中的最后一个阶段。 |
| $project | 投射操作符 | 用于重构每一个文档的字段,可以提取字段,重命名字段,甚至可以对原有字段进行操作后新增字段 |
| $skip | 跳过操作符 | 用于跳过指定数量的文档 |
| $sort | 排序操作符 | 用于根据一个或多个字段对文档进行排序 |
| $unwind | 拆分操作符 | 用于将数组中的每一个值拆分为单独的文档 |
| $lookup | 连接操作符 | 用于连接同一个数据库中另一个集合,并获取指定的文档,类似于populate |
| $addFields | 字段操作符 | 用于给聚合管道的结果文档添加字段 |
$match 语法
匹配操作符,用于对文档集合进行筛选
{ $match: { <query> } }
$project 语法
用于重构每一个文档的字段,可以提取字段,重命名字段,甚至可以对原有字段进行操作后新增字段
{ $project: { <specification(s)> } }
specification 的规则如下:
| 规则 | 描述 |
|---|---|
| <字段名>: 1 or true | 选择需要显示什么字段 |
| _id: 0 or false | 不显示 _id (默认显示) |
| <字段名>: 表达式 | 使用表达式,可以用于重命名字段,或对其值进行操作,或新增字段 |
| <字段名>: 0 or false | 选择需要不返回什么字段,注意:当使用这种用法时,就不要用上面的方法 |
$addFields 语法
在聚合管道结果添加一些字段信息或者修改字段信息
{ $addField: <document> }
$skip 语法
用于跳过指定数量的文档
{ $skip: <positive integer> }
$limit 语法
用于限制返回文档的数量
{ $limit: <positive integer> }
$count 语法
{ $count: <string> }
- string:是输出字段的名称,该字段的值为 count。string 必须是非空字符串,不能以 $ 开头,也不能包含 .点字符
$sort 语法
用于根据一个或多个字段对文档进行排序
{ $sort: { <field1>: <sort order>,<field2>: <sort order> ... } }
- 1:升序
- -1:降序
$out 语法
{ $out: "<output-collection>" }
$unwind 语法
用于将数组中的每一个值拆分为单独的文档
{
$unwind:
{
path: <field path>, includeArrayIndex: <string>,
preserveNullAndEmptyArrays:<boolean>
}
}
- path:字符串类型,数组字段的字段路径,若要指定字段路径,需要在字段名称前加上 $ 符号并将其括在引号内
- includeArrayIndex:可选项,用于保存元素的数组索引的新字段的名称。名称不能以 $ 符号开头
- preserveNullAndEmptyArrays:
- 如果为 true,如果路径为空、没有数组字段或数组为空,则 $unwind 输出文档
- 如果为 false,如果路径为空、没有数组字段或数组为空,则 $unwind 不输出文档(默认)
$lookup 语法
用于连接同一个数据库中另一个集合,并获取指定的文档
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}
| 字段 | 描述 |
|---|---|
| from | 需要关联的集合名 |
| localField | 本集合中需要查找的字段 |
| foreignField | 另外一个集合中需要关联的字段 |
| as | 输出的字段名 |
$group 语法
用于对文档集合进行分组
{ $group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ... } }
- _id:是必须的,用作分组的依据条件
表达式(Expression)
表达式可以包括字段路径和系统变量、文本、表达式对象和表达式操作符。表达式可以嵌套。
{ <field1>: <expression1>, ... }
-
字段路径表达式:$
-
"$<field>” 等价于 “$$CURRENT.<field>”,其中 CURRENT 是一个系统变量,在大多数阶段默认为当前对象的根.
-
聚合表达式使用字段路径访问输入文档中的字段。若要指定字段路径,请使用前缀为$符号字段名的字符串,如果字段在嵌入的文档中,则使用点语法。
-
系统变量表达式:$$系统变量
-
$$CURRENT 表示当前文档
-
$$ROOT 整个文档
-
-
字面量表达式:返回不需要解析的值。用于聚合管道可解释为表达式的值
-
表达式对象
-
表达式操作符
表达式操作符
表达式操作符主要用于在管道中构建表达式时使用,使用类似于函数那样需要参数,主要用于 $project 操作符中,用于构建表达式,使用方法一般如下:
{ <operator>: [ <argument1>, <argument2> ... ] }
# 或
{ <operator>: <argument> }
表达式操作符分类
- 布尔值操作符(Boolean Operators)
- 集合操作符(Set Operators)
- 比较操作符(Comparison Operators)
- 数学操作符(Arithmetic Operators)
- 字符串操作符(String Operators)
- 文本搜索操作符(Text Search Operators)
- 数组操作符(Array Operators)
- 变量操作符(Variable Operators)
- 字面量操作符(Literal Operators)
- 日期操作符(Date Operators)
- 条件操作符(Conditional Operators)
- 数据类型操作符(Data Type Operators)
累加器(Accumulators)
| 累加器操作符 | 说明 |
|---|---|
| $avg | 返回数值的平均值(忽略非数字值) |
| $max | 返回每个组的最高表达式值 |
| $min | 返回每个组的最低表达式值 |
| $push | 返回每个组的表达式值组成的数组 |
| $sum | 返回数值的和(忽略了非数字值) |
$avg 语法
{ $avg: [ <expression1>, <expression2>... ] }
$max 语法
{ $max: <expression> }
{ $max: [ <expression1>, <expression2>... ] }
$push 语法
{ $push: <expression> }
$sum 语法
{ $sum: <expression> }
聚合管道优化
聚合管道操作有一个优化阶段,该阶段试图重塑管道以提高性能
管道序列优化
-
$project or $addFields) 和 $match 顺序优化
-
$sort 和 $match 顺序优化
-
$skip 和 $limit 顺序优化
-
$project 和 ($skip or $limit) 顺序优化
管道联合优化
- $sort 和 $limit 联合优化
当 $sort 紧邻 $limit 时,优化器可以将 $limit 合并到 $sort 中。这允许 $sort 操作在进行过程中只维护顶部的 n 个结果,其中 n 是指定的限制,MongoDB 只需要在内存中存储 n 个条目。
- $limit 和 $limit 联合优化
当一个 $limit 紧接另一个 $limit 之后,这两个阶段可以合并为一个 $limit,其中 $limit 值是两个初始 $limit 值中较小的一个。
- $skip 和 $skip 联合优化
当一个 $skip 紧接着另一个 $skip 时,这两个阶段可以合并为单个 $skip,其中 $skip 量是两个初始 $skip 量的总和。
- $match 和 $match 联合优化
当一个 $match 紧跟在另一个 $match 之后时,这两个阶段可以合并为一个结合了条件和 $and 的单个 $match
-
$sort 和 $skip 和 $limit 联合优化
-
$limit 和 $skip 和 $limit 和 $skip 联合优化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号