【简易大数据应用】购物篮数据的关联分析
一、应用内容
某大型商场预计在下个周进行一次大型的促销活动,促销的主要手段为捆绑销售,即将某些商品进行捆绑销售并以一定的折扣卖出。然而,捆绑并不是随机的,商场希望捆绑的商品都是关联的,即若在平时用户买了商品A,则他有大概率会买商品B的话,将A和B进行捆绑就有很大概率比单卖的话销量更高,即和B是关联商品。现要求设计一个大数据算法,利用大数据相关的技术,获取尽可能多的关联商品集合,以帮助该商场获得尽可能多的利润。然而,偶尔的关联性并不能很好地说明物品间的联系,因此,给定该商场最近10天的所有销售记录(用户的购买记录) t,若存在一个商品集合s = {A,B,C} ⊆t,s若能频繁地出现在销售记录中,则s就可能是一个关联的商品集合。为了量化该频繁性,给定一个参数d,d为正整数,若|s|不小于d,则s就是一个关联集合,请设计算法求出所有的关联集合,给出用到的大数据的相关技术,编写相应代码并演示。
输入:
10 天的销售数据文件 data.txt,文件中每一行代表一个用户的购买记录,如“apple, milk,beef”表示用户一次性买了苹果、牛奶和牛肉。因只用于测试,该文件仅有 10000行左右的数据。(测试数据见附件!)
d:需要满足的最小频繁度;
输出:
返回所有的关联集合以及它们各自的频繁度,且集合内商品的数量不小于2。
二、开发环境及技术
编译环境:Ubuntu 18.04
使用技术 :Hadoop,MapReduce
开发工具:Eclipse
三、设计与实现
简化:
本题为求解所有的关联集合,给定某个集合S,若S出现在数据集中的次数达到了d 以上,输出S即可,因此,本题转化为求S的个数的问题,基于MapReduce的特性,我们Map 的输出一定得是<集合,在当前数据集中存在的个数>这样的一个键值对,然而,数据集给的是一条一条的记录,一个记录里可能包含了很多的集合,因此,本题的难点在于如何把这些集合都拆解出来,而拆解集合其实就是一个求子集的过程,每读到一条购物记录,则将其所有子集拆出来(只含1项的去掉),然后转化为<子集,1>的形式,这样又变成了1个wordcount问题,Reduce过程几乎不用做任何处理。所以,当数据集被读入时,每读到一个购物记录,则生成该购物记录的所有子集,剔除其中只含有1个商品的子集,并将每个子集计数为1,并输出。Reduce端不需要做任何处理,只要判断某个集合的计数是否不小于d,若不小于d则输出即可,本题完结。
总结:在Map的输入阶段将每一行的数据的子集求解出来,在Map的输出阶段输出每一条的记录,最后在Reduce阶段判断某个集合的计数是否不小于d,若不小于d则输出即可。
设计
在Map的输入阶段将每一行的数据的子集求解出来,在Map的输出阶段输出每一条的记录,最后在Reduce阶段判断某个集合的计数是否不小于d,若不小于d则输出即可。
求子集:
现有n个元素的集合,先求得(n-1)个元素的所有子集,再将第n个元素加入到之前的所有子集之中,这就实现了求n个元素的子集。
实现
1)在eclipse编译环境中运行ShoppingData类,结果如图所示
2)之后,需要将Java应用程序打包生成JAR包,部署到Hadoop平台上运行,如图。
3)可以把词频统计程序放在“/usr/local/hadoop/myapp”目录下。如果该目录不存在,可以使用如下命令创建:
cd /usr/local/hadoop
mkdir myapp
4) 在运行程序之前,需要启动Hadoop,命令如下:
cd /usr/local/hadoop
./sbin/start-dfs.sh
5)在启动Hadoop之后,需要首先删除HDFS中与当前Linux用户hadoop对应的input和output目录(即HDFS中的“/user/hadoop/input”和“/user/hadoop/output”目录),这样确保后面程序运行不会出现问题,具体命令如下
cd /usr/local/hadoop ./bin/hdfs dfs -rm -r input ./bin/hdfs dfs -rm -r output
6)然后,再在HDFS中新建与当前Linux用户hadoop对应的input目录,即“/user/hadoop/input”目录,具体命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir input
7)将数据文件data.txt上传到HDFS中的“/user/hadoop/input”目录下,命令如下:
./bin/hdfs dfs -put /usr/local/data.txt input(数据文件存放在/usr/local目录下)
8)最后,就可以在Linux系统中,使用hadoop jar命令运行程序,命令如下:
cd /usr/local/hadoop
./bin/hadoop jar ./myapp/ShoppingData.jar input output

9)词频统计结果已经被写入了HDFS的“/user/hadoop/output”目录中,可以执行如下命令查看词频统计结果:
cd /usr/local/hadoop ./bin/hdfs dfs -cat output/*
结果如图所示(此处仅展示两张图):
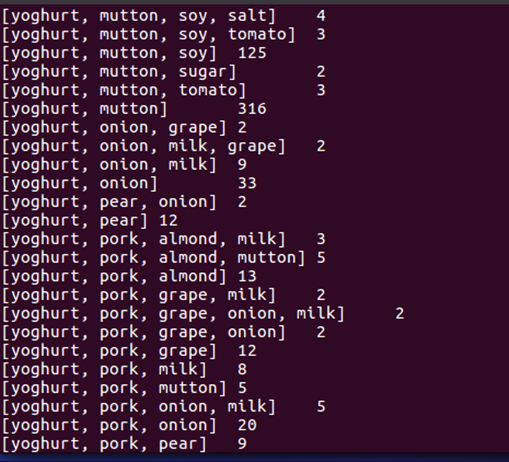
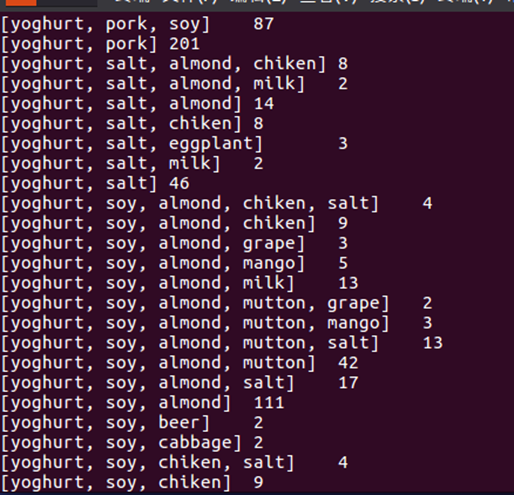
附录:
ShoppingData项目代码如下:
import java.io.IOException; import java.util.ArrayList; import java.util.Iterator; import java.util.Scanner; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; import java.util.ArrayList; public class ShoppingData{ public ShoppingData(){ } //最小频繁度 public static int d=2; public static void main(String[] args) throws Exception { Scanner input=new Scanner(System.in); System.out.println("请输入最小频繁度: "); d = input.nextInt(); Configuration conf = new Configuration(); String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs(); if(otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } Job job = Job.getInstance(conf, "Shooping Data"); job.setJarByClass(ShoppingData.class); job.setMapperClass(ShoppingData.TokenizerMapper.class); job.setCombinerClass(ShoppingData.IntSumReducer.class); job.setReducerClass(ShoppingData.IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); for(int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true)?0:1); } public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private static final IntWritable one = new IntWritable(1); private Text word = new Text(); public TokenizerMapper() { } public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString(),","); //定义数组 ArrayList<String> arrayList = new ArrayList<>(); //添加一行打所有数据 while(itr.hasMoreTokens()) { arrayList.add(itr.nextToken()); // this.word.set(itr.nextToken()); // context.write(this.word, one); } // System.out.println("读入的数据为: "); // System.out.println(arrayList); //获取子集 ArrayList<ArrayList<String>> allList = sub(arrayList,0); // System.out.println("子集为: "); // System.out.println(allList); //获取有效子集 ArrayList<ArrayList<String>> resList = new ArrayList<>(); for(ArrayList<String> item: allList) { if(item.size()>1){ //newSubset.addAll(item); resList.add(item); } } // System.out.println("有效子集为: "); // System.out.println(resList); //设定key-value for(ArrayList<String> item: resList){ this.word.set(item.toString()); context.write(this.word, one); // System.out.println("word为: "); // System.out.println(this.word); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public IntSumReducer() { } public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; IntWritable val; for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) { val = (IntWritable)i$.next(); } this.result.set(sum); //当num大于最小频繁度时,进行打印 if(this.result.get() >= d) context.write(key, this.result); } } public static ArrayList<ArrayList<String>> sub(ArrayList<String> arr, int index) { //声明一个装子集的集合 ArrayList<ArrayList<String>> all = new ArrayList<ArrayList<String>>(); //判断:如果传入的集合长度==传入的元素索引(实质上是要求子集的元素个数),即前面的所有元素都安排完了 if(arr.size() == index){ //添加一个空的集合 all.add(new ArrayList<String>()); }else{ //递归调用:从索引为0的元素开始将索引增加不断调用 all = sub(arr, index+1); //获得当前索引的元素 String item = arr.get(index); //声明一个装所有(index-1)个元素的所有子集元素+当前索引元素的集合 ArrayList<ArrayList<String>> subsets = new ArrayList<ArrayList<String>>(); //遍历包含index-1的所有子集和的集合,将其中的子集输出 for(ArrayList<String> s: all){ //声明一个新的数组来装(index-1)个元素的所有子集元素+当前索引index元素的集合 ArrayList<String> newSubset = new ArrayList<String>(); //先将(index-1)个元素的每一个子集添加到新的集合中 newSubset.addAll(s); //再将index位置的元素添加进去 newSubset.add(item); //最后将新的子集添加到集合subsets中 subsets.add(newSubset); } //最后将加入新的元素后的所有子集添加到包含(index-1)个元素的所有子集的集合当中当中 all.addAll(subsets); } return all; } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号