
NO.2:自学tensorflow之路------BP神经网络编程
引言
在上一篇博客中,介绍了各种Python的第三方库的安装,本周将要使用Tensorflow完成第一个神经网络,BP神经网络的编写。由于之前已经介绍过了BP神经网络的内部结构,本文将直接介绍Tensorflow编程常用的一些方法。
正文
神经网络的内容
一般,一个神经网络程序包含以下几部分内容。
1.数据表达和特征提取。对于一个非深度学习神经网络,主要影响其模型准确度的因素就是数据表达和特征提取。同样的一组数据,在欧式空间和非欧空间,就会有着不同的分布。有时候换一种思考问题的思路就会使得问题变得简单。所以选择合适的数据表达可以极大的降低解决问题的难度。同样,在机器学习中,特征的提取也不是一种简单的事。在一些复杂问题上,要通过人工的方式设计有效的特征集合,需要很多的时间和精力,有时甚至需要整个领域数十年的研究投入。例如,PCA独立成分分析就是特征提取中常用的手段之一。但是很多情况下,人为都很难提取出合适的特征。
由于不同问题下,可以提取不同的特征向量,这里将不做具体介绍。事实上深度学习解决的核心问题之一就是自动地将简单的特征组合成更加复杂的特征,并使用这些组合特征解决问题。
2.定义神经网络的结构。由神经网络发展的历史可知,不同结构的神经网络在不同的问题下得到的效果不同。因此分析问题,选择与问题合适的神经网络结构也同样重要。
3.训练神经网络的参数。使用训练数据集训练神经网络。主要是利用神经网络输出误差反向传播修正神经网络中的参数,甚至结构。反向传播过程中,步长选择对神经网络的训练有着重要的影响,在此基础上产生了多种训练方法。将在后面介绍。
4.使用训练好的神经网络预测未知数据。训练神经网络的目的就是对未知数据预测。
具体过程可以由如下流程图表示:
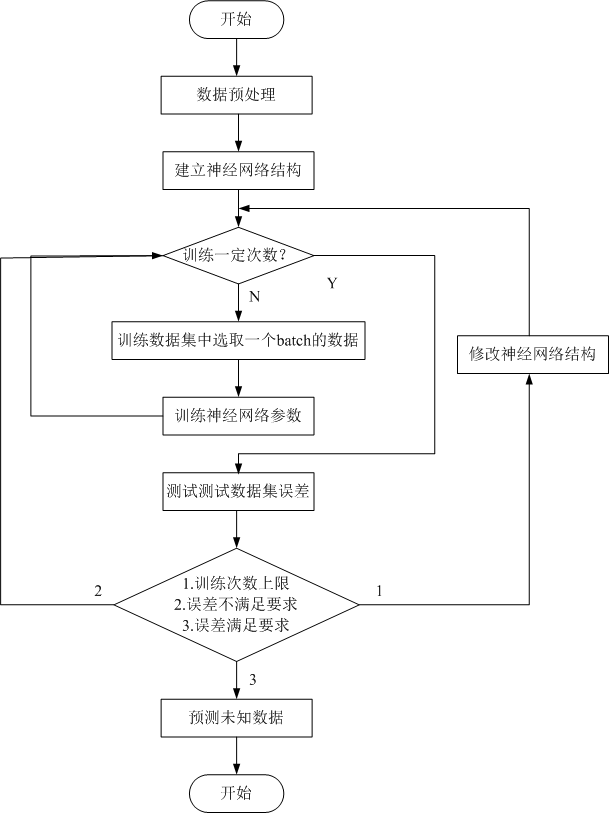
BP神经网络
这里将按照流程图,详细构造BP神经网络。
1.数据预处理
这里将使用自造的数据模拟实际数据,通过对自造的数据仿真,验证BP神经网络的拟合能力。模型将使用一个单输入单输出一阶惯性传递函数模型。模型结构如下所示:
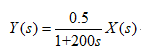
为了很好的激励出模型的特性,X将用随机数来表示。具体制造模型,例子:
导入第三方库,后面将不再展示。
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt
导入完成后就需要生成输入与输出的数据了。由于现实中各种数据之间的单位不同,直接使用时,由于数量级的问题往往会导致神经网络建模出现一些奇怪的问题。所以建模数据是需要归一化的。而这里为了方便,将直接生成0~1的数据。例子:
#生成输入输出数据 input_size = 1#输入变量个数 output_size = 1#输出变量个数 data_size = 2000#样本个数 k,T,x_state = 0.5,200,0#比例增益,时间常数,初始状态 x_data = np.random.rand(data_size,input_size)#输入数据0~1之间 y_data = np.zeros((data_size,output_size))#初始化输出数据 t_conv = np.e**(-1/T)#零阶保持器,采样周期1s for i in range(data_size): x_state = t_conv*x_state + k*(1-t_conv)*x_data[i] y_data[i] = x_state
这里使用零阶保持的方法,将传递函数离散化后生成了共2000点的数据。这样就完成了数据预处理。
2.神经网络结构
由于已经确定要使用BP神经网络为传递函数建模。所以直接按照一层隐含层的BP神经网络建立结构就可以了。而在建立前,需要学习Tensorflow中张量的相关操作。
首先,在Tensorflow中定义张量的方法是。例子:
a = tf.constant([1,2,3]) print(a)
从运行结果可以发现,Tensorflow中的张量与numpy中的向量不同,张量中包含着名字,维度,和类型三种属性。张量是建立在计算图上的,通过使用会话,就可以计算不同的数据。具体计算图将在之后Tensorflow可视化中介绍,这里暂时就可以理解为一个函数。Tensorflow中还含有不同的随机数常数生成函数,可以帮助建立神经网络中的权值和阈值。例子:
tf.random_normal()#正太分布,可设置平均值、标准差、取值类型 tf.truncated_normal()#正态分布,但随机值偏离平均值2个标准差以内 tf.random_uniform()#平均分布,可设置最小值、最大值、取值类型 tf.random_gamma()#gamma分布,可设置形状参数,尺度参数,取值类型 tf.zeros()#产生全0数组 tf.ones()#产生全1数组 tf.fill()#产生全部为给定数字的数组
特殊的,当不指导输入数据的长度时,可以用一个占位来定义。例子:
a = tf.placeholder(tf.float32,[None,1])
定义好节点以后,就需要进行计算,常用的计算中加减乘除与之前相同,下面将介绍一些不同的。例子:
a = tf.Variable(tf.ones((1,3))) b = tf.Variable(tf.ones((3,1))) c = tf.matmul(a,b)#向量乘法 d = tf.nn.relu(c)#激活函数ReLU e = tf.nn.sigmoid(c)#激活函数sigmoid f = tf.nn.tanh(c)#激活函数tanh
依靠以上内容,就可以建立BP神经网络的结构。例子:
#神经网络结构 batch_size = 50#训练batch的大小 hide_size = 5#隐藏神经元个数 #预留每个batch中输入与输出的空间 x = tf.placeholder(tf.float32,shape = (None,input_size))#None随batch大小变化 y_pred = tf.placeholder(tf.float32,shape = (None,output_size)) w_hidden = tf.Variable(tf.random_normal([input_size,hide_size],stddev = 1,seed = 1)) b_hidden = tf.Variable(tf.zeros([1,hide_size],dtype = tf.float32)) w_output = tf.Variable(tf.random_normal([hide_size,output_size],stddev = 1,seed = 1)) #定义前向传播过程 h = tf.nn.tanh(tf.matmul(x,w_hidden)+b_hidden) y = tf.nn.sigmoid(tf.matmul(h,w_output))
之后反向传播Tensorflow可以自动进行,我们只需要定义损失函数和反向计算算法就可以了。神经网络模型的效果以及优化的目标是通过损失函数来定义的。这就是使用Tensorflow的优势。根据不同的用途,损失函数有着不同的定义方法。对于分类问题,可以使用交叉熵来定义。交叉熵的计算公式如下:
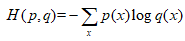
编程例子:
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y,1e-10,1.0)))#定义值与真实值间的交叉熵
这里tf.clip_by_value可以将一个张量中的数值限制在一个范围内,避免运算错误。由于交叉熵经常与softmax回归一起使用,Tensorflow将它们进行了封装。例子:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y,y_)
与分类问题不同,本次例子解决的是回归问题。对于具体数值的预测,应该使用MSE均方误差作为损失函数。例子:
cross_entropy = tf.reduce_mean(tf.square(y_ - y))#定义损失函数
并且,损失函数还可以自己定义,这里不再具体详述。
3.训练神经网络
训练神经网络时,要用到Tensorflow中另一个重要的内容,会话。会话拥有Tensorflow程序运行时的所有资源,并且可以对其进行管理。会话的打开与关闭与文件的读取类似。例子:
#方法1 sess=tf.Session()#创建会话 sess.run()#运行会话——类比打开文件 #具体会话执行内容 sess.close#关闭会话——类比关闭文件 #方法2 with tf.Session() as sess: sess.run() #通过缩进自动关闭
在使用sess.run( )运行计算图时,我们可以传入fetches,用于取回某些操作或tensor的输出内容。fetches可以是list,tuple,namedtuple,dict中的任意一个。例子:
x = tf.constant([1]) y = tf.constant([2]) a = x+y with tf.Session() as sess: z = sess.run(a) print(z)
同样在使用sess.run( )运行计算图时,我们可以传入feed,用于临时替代计算图中任意op操作的输入张量。例子:
x = numpy.array([2]) y = numpy.array([3]) input1 = tf.placeholder(tf.int32) input2 = tf.placeholder(tf.int32) output = input1+input2 with tf.Session() as sess: print(sess.run(output, feed_dict = {input1:x, input2:y}))
4.训练集,测试集。
一般情况下需要将数据分为2类,一部分用来训练模型,一部分用来测试模型。这样就完成了最简单的BP神经网络的建立。
作业
使用普通BP神经网络拟合传递函数
#-*- coding:utf-8 -*- #BP neural network #Author:Kai Z import tensorflow as tf import numpy as np import matplotlib.pyplot as plt #生成输入输出数据 input_size = 1#输入变量个数 output_size = 1#输出变量个数 data_size = 2000#样本个数 x_data = np.random.rand(data_size,input_size)#输入数据0~1之间 y_data = np.zeros((data_size,output_size))#初始化输出数据 k,T,x_state = 0.5,200,0 t_conv = np.e**(-1/T)#零阶保持器,采样周期1s for i in range(data_size): x_state = t_conv*x_state + k*(1-t_conv)*x_data[i] y_data[i] = x_state #神经网络结构 batch_size = 50#训练batch的大小 hide_size = 5#隐藏神经元个数 #预留每个batch中输入与输出的空间 x = tf.placeholder(tf.float32,shape = (None,input_size))#None随batch大小变化 y = tf.placeholder(tf.float32,shape = (None,output_size)) w_hidden = tf.Variable(tf.random_normal([input_size,hide_size],stddev = 1,seed = 1)) b_hidden = tf.Variable(tf.zeros([1,hide_size],dtype = tf.float32)) w_output = tf.Variable(tf.random_normal([hide_size,output_size],stddev = 1,seed = 1)) #定义前向传播过程 h = tf.nn.tanh(tf.matmul(x,w_hidden)+b_hidden) y_pred = tf.nn.sigmoid(tf.matmul(h,w_output)) #反向损失函数 learning_rate = 2e-3#学习速率 cross_entropy = tf.reduce_mean(tf.square(y_pred - y))#定义损失函数 train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)#定义反向传播优化方法 #创建会话 with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op)#初始化变量 #设定训练次数 STEPS = 10000#训练次数 for i in range(STEPS): #选取训练batch start = max((i * batch_size) % 1000,20) end = min(start + batch_size,1000)#取前1000点训练 #计算 sess.run(train_step,feed_dict = {x:x_data[start:end],y:y_data[start:end]}) #显示误差 if i % 100 == 0: total_cross_entropy = sess.run(cross_entropy,feed_dict = {x:x_data[1000:1500],y:y_data[1000:1500]})#1000~1500测试 print('训练%d次后,误差为%f'%(i,total_cross_entropy)) if total_cross_entropy <= 1e-3: break else: print('未达到训练目标') exit() #保存结果 saver = tf.train.Saver() file_path = 'D:/Study/Project/Hobby/Python/03 Study/02 Learn/test' save_path = saver.save(sess,file_path) predict = sess.run(y_pred,feed_dict={x:x_data}) predict = predict.ravel()#转换为向量 orange = y_data.ravel() #建立时间轴 t = np.arange(2000) plt.plot(t,predict) plt.plot(t,orange) plt.show()
后记
可以看出,普通BP神经网络对动态传递函数的拟合效果并不是很好。这是由于神经网络是静态的,而传递函数是动态的。要想辨识动态系统,也得使用动态的神经网络。如最简单的NARX神经网络。或者更复杂的RNN。之后将进行RNN的实现。

