
NO.1:自学tensorflow之路------神经网络背景知识
引言
从本周,我将开始tensorflow的学习。手头只有一本《tensorflow:实战Google深度学习框架》,这本书对于tensorflow的入门有一定帮助。tensorflow中文社区中的翻译的谷歌官方教程十分详细,是自学tensorflow的好帮手,当然如果是英文熟手可以直接看谷歌官方给出的原版教程(博主英语是靠谷歌翻译和百度翻译救活的)。
本篇博客主要讲述机器学习的发展过程,以及BP神经网络的主要内容。不涉及tensorflow的编程。具体BP神经网络tensorflow的实现将在下一篇博文中展示。
正文
机器学习背景
在20世纪以来,任何一门技术的发展都离不开学科间的交融,计算机技术的发展,以及才华横溢的工作者的创新。机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
人类的大脑十分神奇,它帮助人们认识,学习这个世界。神经网络不仅是生物学习记忆的一种结构,同样也是机器学习的基础。将人类的单个神经元传递处理信息的过程简化,并用数学表示,就是神经网络的来源。
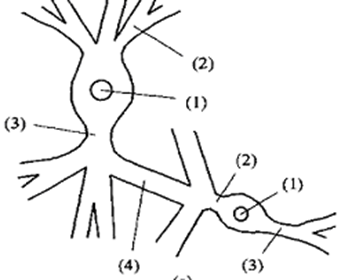
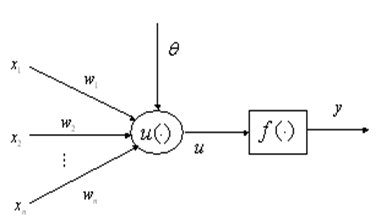
图1.生物神经元(上)和神经网络神经元(下)
早在1958年,Rosenblatt就提出了名为感知机的线性分类模型。但是后来研究人员发现它对非线性问题难以处理,并且当时计算机计算能力低下,难以完成复杂的计算过程。
神经网络的第一次大的革新是在1974年,Paul Werbos提出了反向传播算法,为神经网络的训练提供了良好的方法。让神经网络出现在各种应用场景中,也逐渐出现了多种多样的神经网络结构。
1992年,Vapnik等人提出了支持向量机,支持向量机方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折中,以求获得最好的泛化能力。
从此,一场支持向量机与神经网络的较量就展开了。并且神经网络在后来的较量中逐渐败下阵来。究其原因主要是由于当时计算机的计算能力依然难以满足多层神经网络训练,计算的要求,同时神经网络还存在着梯度消失的现象,使得多层神经网络难以实现。
在2006年,深度学习(Deep Learning)算法的提出是神经网络的第二次大的革新。谷歌AlphaGo在围棋中战胜李世石,点燃了深度学习的一个新的热潮。所以本人就在这个浪头上开始跟风了,希望能在明年毕业之前完成毕设论文。
BP神经网络
一个3层的BP神经网络,是学习神经网络的基础。虽然如今很多工具都有现成的BP神经网络工具,但是如果不能深入了解神经网络内部实际的运作,也将很难对其进行创新。这里将介绍最简单的BP神经网络的正向传播,反向传播过程。
正向传播
一般的BP神经网络是由输入层、隐含层和输出层三层神经网络组成。输入层神经元的个数等于输入变量的个数,输出层神经元的个数等于输出变量的个数,隐含层神经元的个数一般通过经验法选取。变量从输入层传播到隐藏层,其计算过程如下所示:
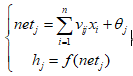
其中, xi为输入层神经元i的输入变量,vij输入层神经元i到隐含层神经元j之间突触的权值,θj为隐含层神经元j的偏置,f()为隐含层激活函数,hj为隐含层神经元的输出。
从输入层到隐藏层的计算过程如下所示:
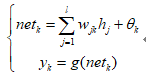
其中,g()为输出层激活函数,yk为输出层神经元k的输出。
激活函数为神经网络引入非线性因素,让神经网络可以解决线性模型不能解决的问题。常用的又sigmoid函数与tanh函数,但这两种都存在梯度消失的问题。Re-LU函数可以解决梯度消失的问题,目前被大量使用。这样就讲完了正向传播的过程。
反向传播
正向传递神经网络,可以得到神经网络输出,随后就可以得到神经网络的误差。神经网络反向传播误差,就可以得到神经元参数应该向最优值运动的方向。通过多次的循环学习,就可以逐渐逼近最优的神经网络参数,完成神经网络的训练。
输出误差函数为:
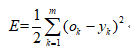
隐藏层误差函数为:
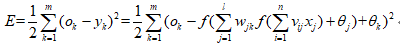
其中,ok为系统实际输出。将误差进行反向传递后,利用梯度下降法,分别让误差对应各层的权值和阈值求偏导数,以达到最优。其表达式如下所示:
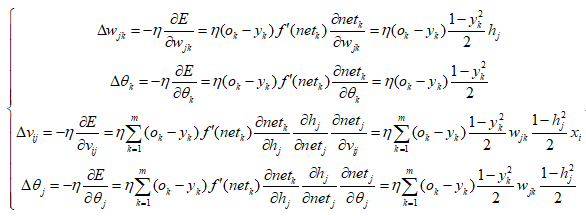
这样就得到了误差反向传播的公式,通过设定合适的batch,就可以进行神经网络的训练了。
谷歌使用tensorflow建立了一个游乐场分类网页,可以通过调节神经元个数,层数,激活函数以及训练步长来快速看出分类效果。十分有趣。游乐场例子:http://playground.tensorflow.org
后记
由于平日学习用Matlab居多,而学习深度学习,tensorflow又是其目前最好用的工具之一。希望一切努力不会付诸流水,与正在学习的朱军共勉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号