
jbd2
June 21, 2006 - 2:40am
Submitted by Kedar Sovani on June 21, 2006 - 2:40am.
http://kerneltrap.org/node/6741
原作者与版权信息:
Amey Inamdar (www.geocities.com/amey_inamdar) is a kernel developer working at Kernel Corporation. His interest areas include filesystems and distributed systems.
Kedar Sovani (www.geocities.com/kedarsovani) works for Kernel Corporation as a kernel developer. His areas of interest include filesystems and storage technologies.
Copyright (c) 2004-2006 Kedar Sovani and Amey Inamdar
王旭 (gnawux(at)gmail.com, http://sites.google.com/site/gnawux) 于2008年8月19-21日译
原子性是操作的一种属性,标明这个操作要么完全成功,要么完全失败,不会处于中间状态。磁盘可以保证扇区级的原子性。这意味着写一个扇区的操作,要么完全成功,要么根本没写。不过,当一个操作涉及到多个扇区的时候,就需要高层机制了。这种机制应该确保全部的扇区修改都是原子性的。如果不能做到原子性的话将导 致数据的不一致性。本文就将讨论 Linux 中的日志块设备(JBD)的实现。
首先来看看这些文件系统的不一致是如何产生的。假设一个应用程序建立了一个文件。文件系统内部于是就减少一个inode数量,初始化磁盘上的inode,并为文件的父目录添加一个对应于新文件的条目。但如果在上述操作进行到一半的时候计算机崩溃了,那会怎样呢?在这种情况下,不一致性就被引入到文件系统当中了——可用的inode数量减少了,但磁盘上inode的初始化可能还没有进行。
要发现这种不一致性的惟一方法便是扫描整个文件系统,这个程序称为 fsck (filesystem consistency check)。对于很大的系统,一致性检查可能需要相当长的时间(可能高达数小时)来检查并修复这些不一致问题。和你想的一样,这么长的宕机时间是难以接受的。更好的手段当然是在第一时间就避免不一致性的产生,这可以通过为操作提供原子性来达到。日志就是为这些操作提供原子性的一种手段。简单地说,使用日 志就像使用了一个草稿本。你在草稿本上进行操作,当操作正确,你满意了之后,可以把他们誊到最终版本上。
对于操作系统而言,所有的元数据和数据都存储在文件系统所在的块设备上。日志文件系统使用一个日志区域作为草稿。日志可以是同一个块设备的一部分,或者是一个单独的设备。一个日志文件系统首先记录所有在日志中的操作。一旦这些作为一个原子操作的操作们都被记录到日志之中了,它们才会被一起写到实际的块设备 中。在后文中,“磁盘(disk)”将指代“真实的块设备”,而“日志(journal)”将指代“日志区域”。
日志恢复场景
这个例子中,根据上面的需求,改动了3个块——inode 计数块,包含了磁盘上的 inode 的块包含了用于插入条目的目录所在的块。所有这些块首先都被写入到日志中。之后,一个特殊的块——提交记录,被写入到日志中,提交记录用于指示写到日志中 的所有的属于一个原子操作的块。
下面三个基本场景就反映了日志文件系统是如何工作的:
- 当第一个块被写入日志的时候机器崩溃了。在这种情况下,当计算机重启之后检查日志,它会发现一个有没有提交的操作。这就标明可能有一个未完成操作。那么,既然现在还没有对磁盘进行修改操作,也就保持数据一致性。
- 当提交记录被写入日志的时候机器崩溃。在这种情况下,机器重新启动并检查日志,它会发现一个操作和它的提交记录正在那里。提交记录指明有一个完成了的操作可以被写入到磁盘之中。所有的属于这个操作的块都会依据日志被写到他们在磁盘中的实际位置。
- 所有的三块都被写入日志,但提交记录还没有进入日志的时候机器崩了。即使在这种情况下,因为没有提交记录,磁盘上还是没有任何修改。这个场景中实际和第一个场景区别不大。
类似的,任何其他的崩溃场景都可以归到上面的头两种场景之中。这样,日志确保了文件系统的一致性。用于查找和重放日志的时间与文件系统一致性检查的时间相比简直是微不足道的。
日志块设备
Linux 日志块设备(JBD)提供了这个用于提供操作原子性的草稿纸。这样,由控制着一个块设备的文件系统可以在同一个设备或是其他块设备上使用JBD来保障一致 性。JBD 实现为一个提供一组供这些应用使用的 API 的模块。下面的章节将描述 2.6 内核中的 Linux JBD 的原理和实现。
在 转入到 JBD 的实现细节之前,我们需要了解一些 JBD 用到的对象。日志(journal)是管理一个块设备的更新的内部记录(log)。正如上文提到的,更新首先会放到日志之中,然后反射到它们在磁盘上的真 实位置。日志区域被当作一个环状链表来管子。也就是说,当日志记满的时候会重用之前用过的区域。
handle 代表一个原子更新。需要被原子地完成的全部一组改写被提取出来引用为一个 handle。
不过,将每个原子更新(handle)都写入到日志 之中可能不那么高效。为了更高的性能,JBD 将一组 handle 打包为一个事务(transaction),并将事务一次写入日志。JBD 保障事务本身是原子性的。这样,作为事务的组成部分的 handle 们自然也是原子性的。
事务最重要的属性是它的状态(state)。当事务正在提交时,它的生命周期经历了下面的一系列状态。
- 运行(running):事务当前是活着的,并且可以接受新的句柄。在一个系统中,仅有一个事务可以处于运行状态。
- 锁定(locked):事务不再接受新的 handle,但现有 handle 们还没有完成。一旦所有 handle 都完成了,事务将进入下一个状态。
- 写入(flush):事务中的所有 handle 都完成了,这时事务将它自己写入到日志中去。
- 提交(commit):整个事务的记录都被写到日志里面这之后。事务会写一个提交块,来指到日志中的事务记录已经完成了。
- 完成:事务完整的写到日志种种之后,它会留在那直到所有的块都被更新到磁盘上的实际位置。
Transaction Committing 与 Checkpointing
一个处于运行状态的事务在一段时间之后会被写(write)到日志区域。这样,一个事务可能是在内存中(running)或是在磁盘上。将事务写入(flushing)到日志中并标记特定的事务已完成的过程称为事务的提交。
日 志只控制一小块有限的区域,并且需要进行重用。对于已经提交的事务,也就是那些已经把全部块都写到磁盘上的事务,就不再需要停留在日志里了。这 里,Checkpointing(这词儿咋翻译?咬不准啊)就是用于将完成的事务写入磁盘并重新声明日志中对应的空间可用的过程。
实现概要
JBD 层用于进行元数据的日志记录,期间数据简单的不经过日志直接写到磁盘上。但是这并不阻止应用程序记录数据的日志,因为它可以告诉 JBD,它自己是元数据。本文以 2.6.0 内核为例。
Commit
[journal_commit_transaction(journal object)]
Kjournald 线程与每个进行日志的设备相关联。Kjournald 线程保证运行中的事务会在一个特定间隔后被提交。事务提交的代码分成了如下八个不同阶段。图1 给出了日志的逻辑结构。
阶段0:将事务的状态从运行(T_RUNNING)变为锁定(T_LOCKED),这样,这个事务就不能再添加新的 handle 了。事务会等待所有的 handle 都完成的。当事务初始化的时候,会预留一部分缓冲区。在这一阶段,有些缓冲区可能没有使用,就被释放了。到这里,所有事务都完成了之后,事务就已经准备好 了可以被提交了。
阶段1:事务进入到写入状态(T_FLUSH)。事务被标记为正在向日志提交的事。这一阶段中,也会标记该日志没有运行状态的事务存在;这样,新的 handles 请求将会导致新的事务的初始化。
阶段2:事务实际使用的缓冲们被写入到磁盘上。首先是数据缓冲。由于数据缓冲不存储到日志记录区域,所以没有什么麻烦的。相反,它们会直接写到磁盘的真实位置。这一阶段在这些缓冲都被接收、收到 IO 操作完成提示后结束。
阶段3:这时所有的数据缓冲都已经写入到磁盘上了, 但它们的元数据还在内存之中。元数据的写入不像数据缓冲那么直接,因为元数据需要先写到日志区域之中,并需要记录它们实际要存放的位置。在这个阶段会首先 写这些元数据缓存,这里需要一个日志描述块。日志描述块以标签(tag)的形式存储日志中的每个元数据缓存到它的实际位置的映射。之后,元数据缓存写入日 志。一旦日志描述符中装满了标签,或者所有的元数据缓存都写入到日志之中了,日志描述符就会被写入到日志之中。现在,所有的元数据缓存都存在日志中了,而 且它们在硬盘中的实际位置也被记录下来了。如果系统宕机,再启动的时候,这些要被永久化写入磁盘的数据就可以用来恢复数据了。
阶段4 和阶段5:这两个阶段分别在等元数据缓冲和日志描述符的 I/O 描述通告。一旦收到 I/O 完成消息,内存链表中对应的缓冲就可以释放掉了。
阶段6:现在所有数据和元数据都已经安全地保存着 了,数据就在它们的实际位置,而元数据在日志中。现在,事务要被标记为已提交,这样就表明所有的更新都妥善保存在日志之中了。因此,日志描述块再次分配。 一个标签会被写入,以示事务已经被成功提交,这个块是同步写入到到日志之中的。这之后,事务便进入了已提交状态,T_COMMIT。
阶段7:当很多事务被写入到日志中但还没有写入到磁盘中的时候。当前事务中的一些元数据缓存可能是一些之前的事务的一部分。这就不需要保存之前的事务了,因为我们的当前提交的事务已经有了更新的版本了。这些缓冲于是就被从老的事务中删除了。
阶段8:事务被标记为完成状态,T_FINISHED。日志结构被更新以将当前事务标记为最新提交的事务。同时也将自己标到要被 checkpoint 的事务列表中去。
Checkpointing
当 日志要被写入磁盘的时候,checkpointing 就会被启动了——比如卸载文件系统,或者在新的 handle 开始的时候也可能会启动 checkpointing。一个新的 handle 可能发现需要保证的缓冲数量不足了,于是它就可能需要启动 checkpointing 进程来释放一些日志空间。
checkpointing 进程将写入那些还没有写到硬盘里实际位置上的元数据缓冲。于是这些事务就可以被从日志中删除了。一个日志区域可以有多个 checkpointing 事务,而每个 checkpointing 事务都可以有多个缓冲。checkpointing 进程处理每个提交的事务,对每个事务找出需要写入磁盘的元数据缓冲。所有这些缓冲被一批写入磁盘。一旦所有事务都被处理完,他们的记录就会被从日志中删掉 了。
恢复
[journal_recover(journal object)]
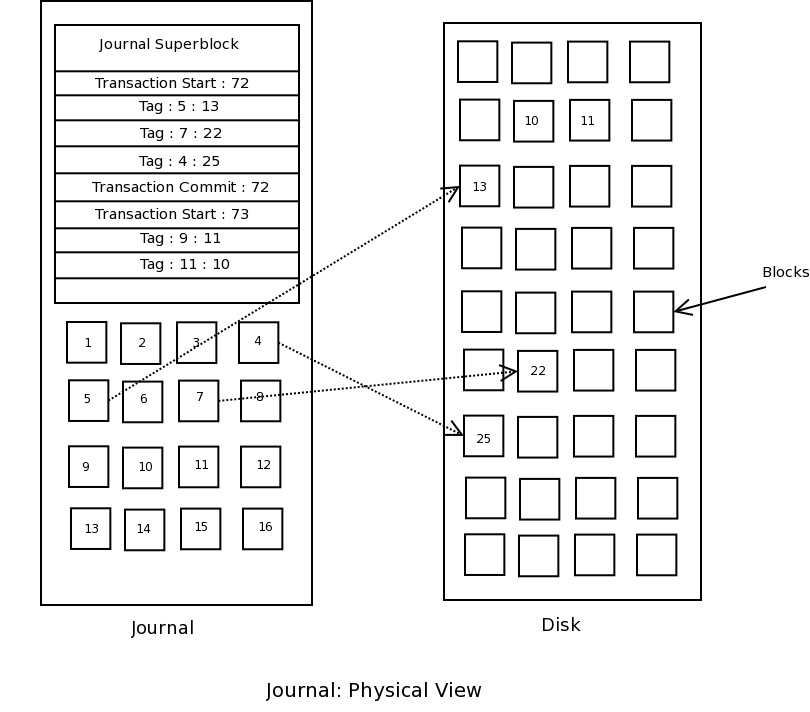
当系统在崩溃之后启动的时候,它会发现日志条目不是空的,这就表明上次文件系统卸载并不成功,或者根本就没有进行。这就需要尝试进行修复了。图2 绘制了日志的物理结构的一个例子。修复分三个阶段进行。
- PASS_SCAN: 发现日志记录的尾部。
- PASS_REVOKE: 为日志记录准备一串要被撤销的块。
- PASS_REPLAY: 未被撤销的块以确保磁盘一致性的顺序被重新写入(重放)。
对于恢复而言,可用信息已经在日志中提供了。但是日志的实际状态是不清楚的,就像我们不知道系统在那个具体的点崩溃的一样。这样,最后的事务可能在 checkpointing 或是提交的状态。一个在运行中的事务是不可能被发现的,因为它还在内存中。
对于提交状态的事务,我们不得不忘掉这些更新,因为可能不是所有的更新都在这里。这样,在 PASS_SCAN 阶段中,最后的记录条目会被发现。到这里,恢复进程知道了哪些事务需要被重写。
每个事务可以有一组撤销(revoked)块。这些块非常重要,通过它们可以防止同一个块的老的日志记录被重放在新的数据之上。在 PASS_REVOKE 过程中,会准备一个撤销块的哈希表。每当我们要找出某个快是否需要被在重放中写入到磁盘的时候,这个表就会被用到。
在最后一个阶段,所有的需要被重演的块都需要被处理。 每个块都会检查是否存在在解除块撤销表之中。如果这个块没在表里,那么它就可以被安全的写入到磁盘上的实际位置之中。而如果这个块在表中,那么只有最新的 版本才会写入到磁盘中。注意,我们还没有改变磁盘上的日志的任何内容。这样,如果在修复过程中系统再次崩溃的话不会造成任何破坏。同样的日志可以在下次用 来重新恢复,在恢复的过程中,无关的操作不会被进行。
http://blog.chinaunix.net/uid-8653017-id-2018003.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号