Set集合
Set接口
Set框架
*
* |----Collection接口:单列集合,用来存储一个一个的对象
* |----Set接口:存储无序的、不可重复的数据 -->高中讲的“集合”
* |----HashSet:作为Set接口的主要实现类;线程不安全的;可以存储null值
* |----LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历
* 对于频繁的遍历操作,LinkedHashSet效率高于HashSet线程不安全.
* |----TreeSet:可以按照添加对象的指定属性,进行排序。
Set特点
Set:存储无序的、不可重复的数据,可以存储null值
- set 接口是 Collection的子接口,set接口没有提供额外的方法
- set 集合不允许包括相同的元素,如果试把两个相同的元素加入同一个 set集合中,则添加失败.
- set 判断两个对象是否相同不是使用 == 运算符,而是根据 hash和 equals方法
添加元素特点
- 以HashSet为例:
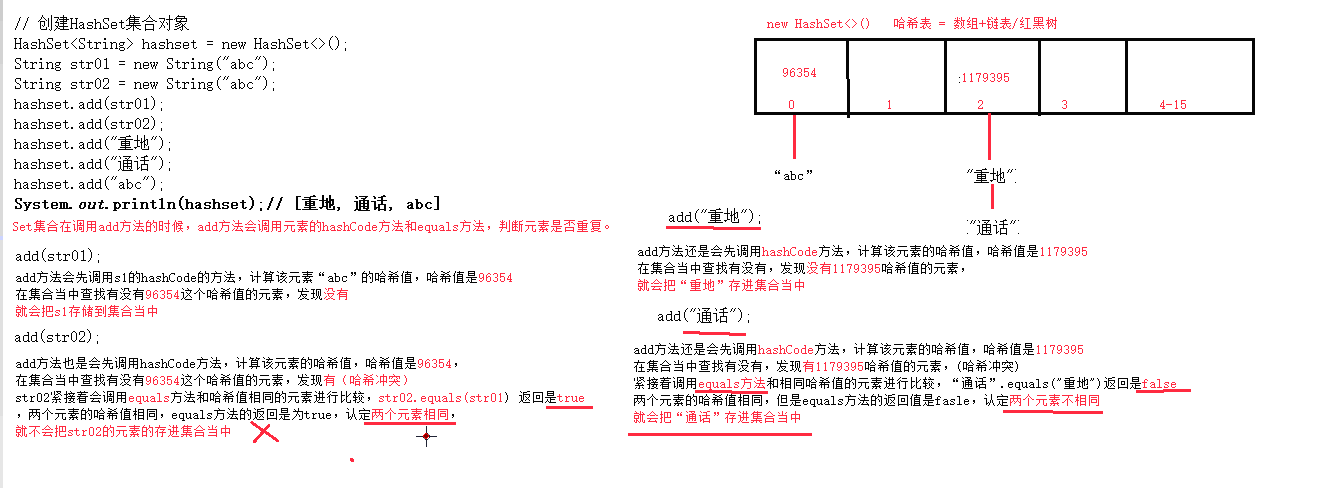
- 我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置),判断数组此位置上是否已经有元素:
- 如果此位置上没有其他元素,则元素a添加成功。 --->情况1
- 如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的hash值:
- 如果hash值不相同,则元素a添加成功。--->情况2
- 如果hash值相同,进而需要调用元素a所在类的equals()方法:
equals()返回true,元素a添加失败
equals()返回false,则元素a添加成功。--->情况3
- 对于添加成功的情况2和情况3而言:元素a 与已经存在指定索引位置上数据以链表的方式存储。
jdk 7 :元素a放到数组中,指向原来的元素。
jdk 8 :原来的元素在数组中,指向元素a
总结:七上八下
- 我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置),判断数组此位置上是否已经有元素:
HashSet集合
HashSet底层:数组+链表的结构。
描述
java.util.HashSet是Set接口的一个实现类,他存储大的元素是不可重复的,并且元素都是无序的(存取顺序不一致)。java.util.HashSet底层实现其实是一个java.util.HashMap支持的。- HashSet是根据对象的哈希值来确定元素在集合当中的存储位置,因此它具有良好的存取和查找性能。保证元素唯一性的方式依赖于
hashCode和equals方法 - 哈希值;是一个十进制的整数,有系统随机给出(就是对象的地址,是一个逻辑地址,是一个模拟出来得到的地址,不是数据实际存储的物理地址),是由Object类中有一个方法,可以获取对象的哈希码值
int hashCode()来获取对象的哈希值 //public native int hashCode(); 参数 native 代表的是该方法调用的是本地操作系统中的方法
特点
- 不允许存储重复的元素,可以是null值
- 没有索引,没有带索引的方法,也不能使用普通for循环
- 是一个无序的集合,存储的元素和取出元素的顺序可能不一致
- 线程不安全
- 底层是一个哈希表结构(查询的速度非常快)
HashSet集合存储数据结构(哈希表)- jdk1.8前 哈希表=数组+链表
- jdk1.8后 哈希表=数组+链表
哈希表=数组+红黑树 - 如果链表的长度超过了8,那么就会把链表结构转换成红黑树
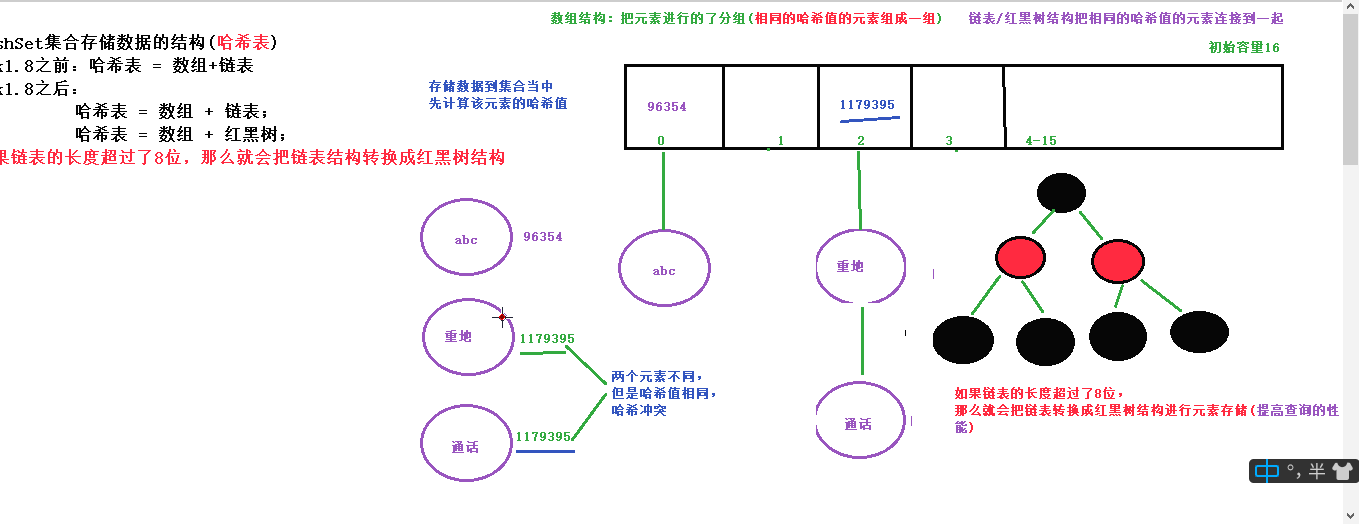
HashSet存储数据的结构(哈希表)
- 什么是哈希表?
在jdk1.8之前,哈希表的底层采用的是数组+链表实现,即使使用链表出来哈希表冲突,同一哈希值的链表都存储在一个链表里,但是当位于一个链中的元素较多的时,通过key值一次查找的效率底下。在jdk1.8中哈希表存储
- 总而言之,jdk1.8之后引入红黑树结构件大大优化了HashMap的性能,那么对于我们来讲保证HashSet元素唯一不重复,其实是根据对象的hashCode方法和equals方法来决定的。如果我们往集合当中存储的时自定义的对象,需要保证对象的唯一性,就必须重写HashCode方法和equals方法,来自定义当前对象的比较方式。
HashSet存储自定义类型的元素
- 一般需要重写对象当中的hashCode和equals方法
底层扩容机制
- 底层也是数组,初始容量为 16,当如果使用频率超过 0.75,(16*0.75)就会扩大容量为原来的2倍.
(16扩容32,依次为64,128...等)
LinkedHashSet
描述
- 在java.util.HashSet类的下面还有一个子类,java.util.LinkedHashSet,他是链表和哈希表的组合的一个数组存储结构。(数组链表/红黑树)+链表。多了一条链表(保证元素的有序)
特点
- LinkedHashSet 是 HashSet的子类
- LinkedHashSet 根据元素的 hashCode值来决定元素的存储位置,但它同时使用双向连表维护元素的次序,这使得元素看起来是以插入顺序保存的.
- LinkedHashSet插入性能略低于 HashSet,但在迭代访问 Set里的全部元素时有很好的性能.
- LinkedHashSet 不允许集合元素重复.
TreeSet
特点
- 有序,查询速度比list快,底层是红黑树数据结构
- 向TreeSet中添加的数据,要求是同类的对象
- 两种排序方式;自然排序和定制排序
- 自然排序中,比较两个对象是否相同的标准为:compareTo()返回0.不再是equals().
- 定制排序中,比较两个对象是否相同的标准为:compare()返回0.不再是equals().
新增方法
Comparator<? super E> comparator() 返回用于为了在这个组中的元素,或比较null如果这个集使用natural ordering的元素。
E first() 返回此集合中当前的第一个(最低)元素。
E ceiling(E e) 返回此集合中最小元素大于或等于给定元素,如果没有此元素,则 null 。
E last() 返回此集合中当前的最后(最高)元素。
E lower(E e) 返回该集合中最大的元素严格小于给定的元素,如果没有这样的元素,则 null 。
Object higher(Object e) 返回这个集合中的最小元素严格大于给定的元素,如果没有这样的元素,则 null 。
E floor(E e) 返回此集中最大的元素小于或等于给定元素,如果没有此元素,则 null 。
SortedSet subSet(fromElement, toElement)返回此集合的部分的视图,其元素的范围从 fromElement (包括)到 toElement ,独占。
SortedSet headSet(toElement)返回此集合的部分的视图,其元素严格小于 toElement 。
SortedSet tailSet(fromElement)返回此集合的部分的视图,该部分的元素大于或等于 fromElement 。
E pollFirst() 检索并删除第一个(最低)元素,如果此集合为空,则返回 null 。
E pollLast() 检索并删除最后一个(最高)元素,如果此集合为空,则返回 null 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号










