NaLLM 项目总结
NaLLM 项目总结
前后端分离,前端Vue3,后端Fastapi
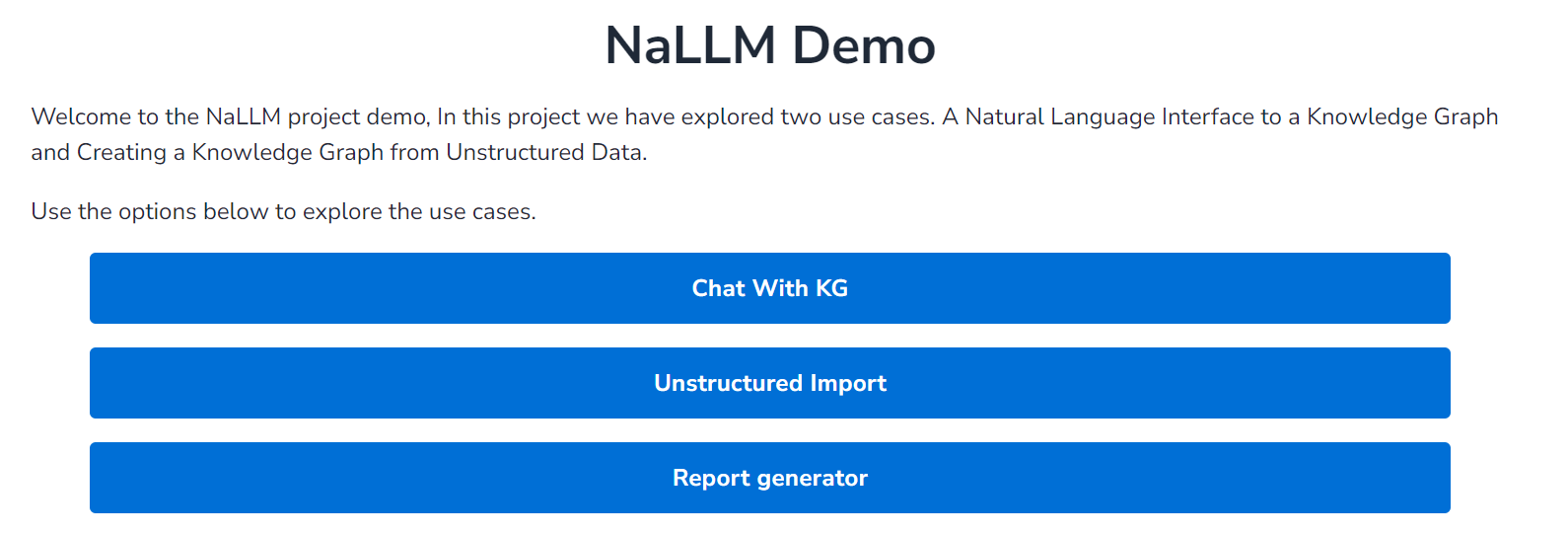
项目的整体界面如图:
主要实现三种功能:
-
Unstructured Import:实现非结构化文本的知识图谱提取和实体关系、去重等操作,最终返回提取的实体、关系和对应的属性,本项目也提供了将原始提取结果转换为CSV文件的类,便于结果的存储。
-
Chat with KG:用户实现与neo4j图数据库连接后,可以通过对话的方式实现询问知识图谱内部节点和关系以及对应的属性,大模型根据用户的问题自动的将问题转化为对应的Cypher查询,并执行Cypher查询后对结果进行润色,最终返回润色后的结果和对应的Cypher语句给界面。
-
Report generator:NaLLM项目初始连接的是关于公司主题的公开图数据库,这一部分主要是根据用户所选择的公司,返回公司的员工、位置、种类、基本概括等一些公司相关的信息(通过在知识图谱上执行一系列的Cypher查询)并将最后的结果以网页的形式展示给用户
先主要介绍后端的部分,(前端vue框架需要进一步的学习)。
毕设相关的主要是Unstructured Import和Chat with KG这两个模块。
后端整体架构结构是这样的:
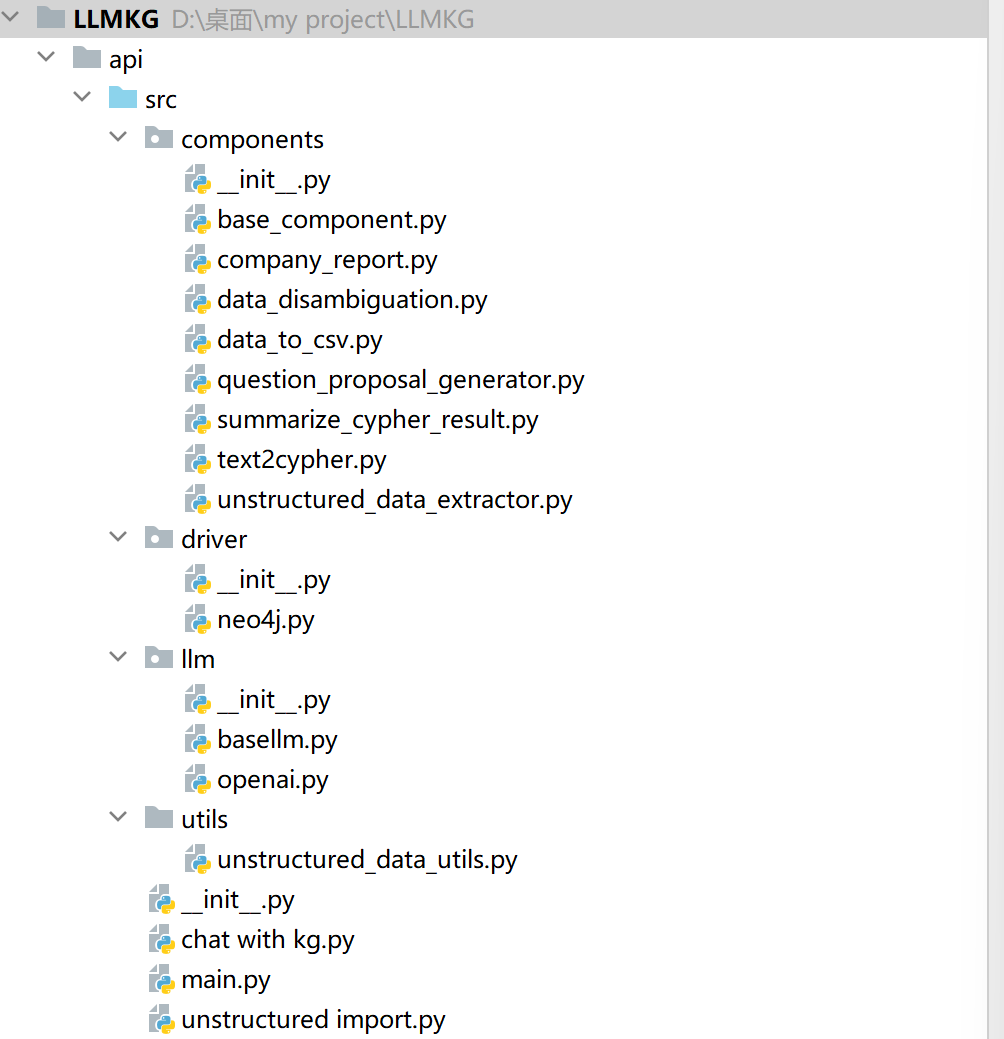
driver、llm、utils的文件夹主要实现一系列相关工具的调用。
其中driver中neo4j主要定义了图数据库连接相关的类,
这个类中query方法主要实现了给定连接的图数据库中cypher查询,执行cypher查询并返回处理结果,若cypher查询中存在错误时也会进行错误处理。
同时也实现schema提取,主要执行cypher语句实现图数据库中节点、关系属性以及关系本身提取。
llm中openai类实现了对大模型的调用,给定输入的system和user内容,输出大模型返回结果。同时也根据模型计算当前输入字符串的token数。
main函数主要是调用components中各种类的方法,实现知识图谱构建、知识图谱查询等的后端api。
项目核心为components,以不同的类为基础实现知识图谱构建、知识图谱查询等操作。
一. Unstructured import
这里面主要采用的为先实现unstructed_data_extractor,之后实现data_disambiguation。
先看一下提取效果:
界面如下:
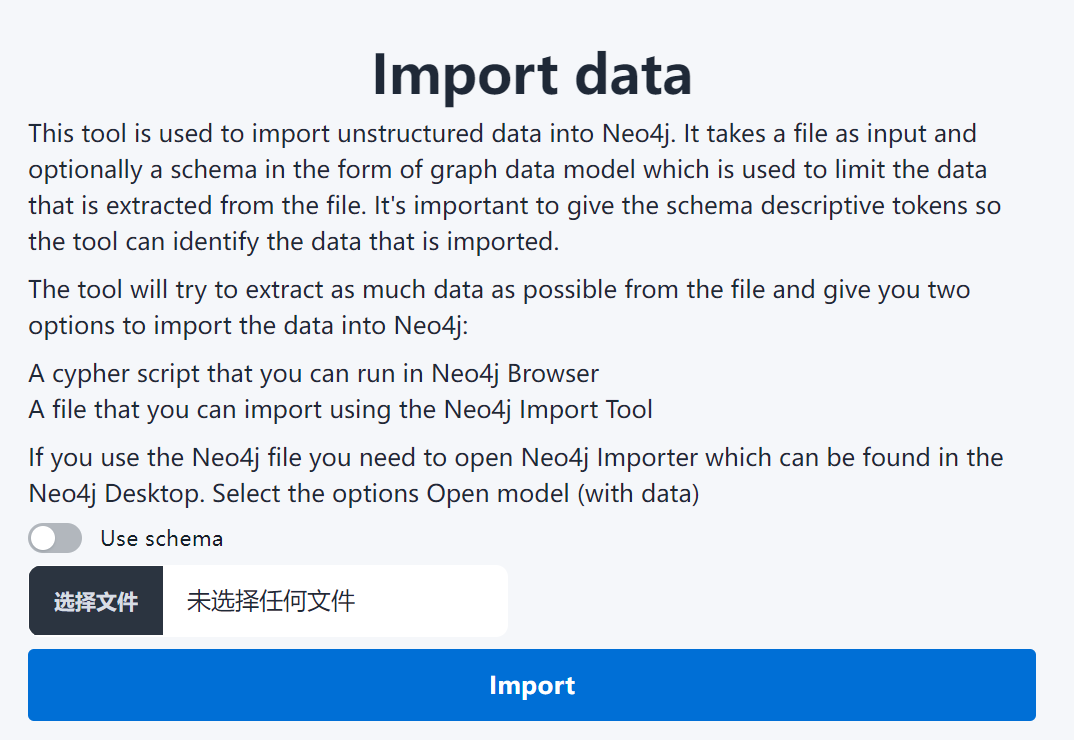
但是在本地部署后无法直接对文件中的内容进行提取。
效果:
尝试采用NaLLM项目prompt提取,发现很容易出现遗漏的现象。
举个例子:
Huang Qi , also known as Jiu Yi, a male of Han nationality,
with his ancestral home in Xiushui, Jiangxi,
was born in Anqing, Anhui, China.
He was a Chinese linguist and calligrapher,
and the former vice chairman of the Chinese Calligraphers Association.
正确的提取结果:
[{"head": "Huang Qi", "relation": "place of birth", "tail": "Anqing, Anhui"},
{"head": "Huang Qi", "relation": "alternative name", "tail": "Jiu Yi"},
{"head": "Huang Qi", "relation": "country of citizenship", "tail": "China"},
{"head": "Huang Qi", "relation": "affiliated organization", "tail": "Chinese Calligraphers Association"}
{"head": "Huang Qi", "relation": "ancestral home", "tail": "Xiushui, Jiangxi"},
{"head": "Huang Qi", "relation": "occupation", "tail": "Chinese linguist"},
{"head": "Huang Qi", "relation": "occupation", "tail": "calligrapher"},
{"head": "Huang Qi", "relation": "position", "tail": "former vice chairman of the Chinese Calligraphers Association"}],
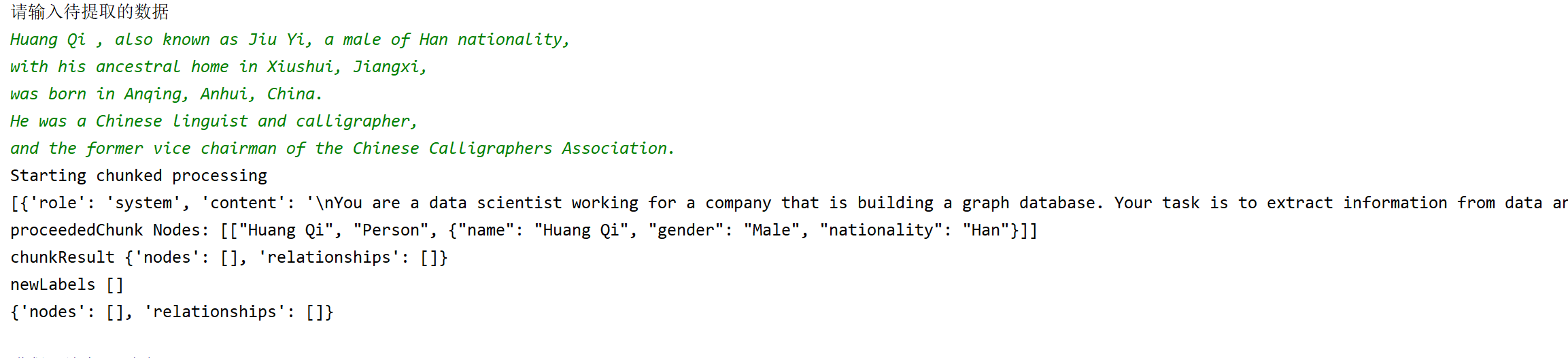
采用NaLLM项目提取的结果明显还是缺失了非常多有用的信息。

采用十分简单的prompt,但是只提取三元组,并不提取属性,效果反而好很多。所以我认为先只进行三元组提取,最后再实现属性的提取反而效果会好很多。
但是如果是很简单的例子,提取效果还是可以的:

不过存在问题为,属性和关系本身就难以区分,例如,located in本身可以作为关系,也可以作为一个景点的属性,这种问题如何解决?我感觉先提取(h,r,t)三元组,之后再实现属性的补充可能比较合适。
1. unstructured_data_extractor
主要划分为DataExtractor(不带Schema)和DataExtractorWithSchema
两种是类似的
首先将原始待提取文本进行分块,每块大小的字符串长度为500,
同时计算每次最多输入多少token(大模型允许token数-system prompt的token数)。
尽可能多的将原始待提取文本对应的块塞入大模型的输入中,直到无法塞下。
这样就可以得到每轮输入的用户文本。
每轮输入的System prompt如下所示:
DataExtractor采用的System Prompt:
You are a data scientist working for a company that is building a graph database.
Your task is to extract information from data and convert it into a graph database.
Provide a set of Nodes in the form [ENTITY_ID, TYPE, PROPERTIES] and a set of relationships in the form [ENTITY_ID_1, RELATIONSHIP, ENTITY_ID_2, PROPERTIES].
It is important that the ENTITY_ID_1 and ENTITY_ID_2 exists as nodes with a matching ENTITY_ID.
If you can't pair a relationship with a pair of nodes don't add it.
When you find a node or relationship you want to add try to create a generic TYPE for it that describes the entity you can also think of it as a label.
You will be given a list of types that you should try to use when creating the TYPE for a node.
If you can't find a type that fits the node you can create a new one.
Example:
Data: Alice lawyer and is 25 years old and Bob is her roommate since 2001. Bob works as a journalist. Alice owns a the webpage www.alice.com and Bob owns the webpage www.bob.com.
Types: ["Person", "Webpage"]
Nodes:
["alice", "Person", {"age": 25, "occupation": "lawyer", "name":"Alice"}],
["bob", "Person", {"occupation": "journalist", "name": "Bob"}],
["alice.com", "Webpage", {"url": "www.alice.com"}],
["bob.com", "Webpage", {"url": "www.bob.com"}]
Relationships:
["alice", "roommate", "bob", {"start": 2021}],
["alice", "owns", "alice.com", {}],
["bob", "owns", "bob.com", {}]
采用的User prompt:
def generate_prompt_with_labels(data, labels) -> str:
return f"""
Data: {data}
Types: {labels}"""
这里的prompt主要是采用了one-shot的prompt,并且要求大模型直接从给定的输入的文本中提取出知识图谱。
在提取的过程中也会尝试使用大模型已经创建的labels来标记提取到的实体和关系,
若目前已有的labels无法来标记提取出的实体和关系,则尝试让大模型自己创造新的实体和关系对应的labels。
最后将每轮大模型的输出文本存储到results列表中,
最终在results列表中通过正则表达式匹配的方法得到所有的实体和关系。
DataExtractorWithSchema是类似的,不过区别在于Prompt的不同:
System Prompt
Only add nodes and relationships that are part of the schema.
If you don't get any relationships in the schema only add nodes.
Example:
Schema:
Nodes: [Person {age: integer, name: string}]
Relationships: [Person, roommate, Person]
User Prompt:
def generate_prompt_with_schema(data, schema) -> str:
return f"""
Schema: {schema}
Data: {data}"""
其他处理部分都是一致的。
评价:
- 数据提取的过程中,并未采用任何的数据集进行测试并评价大模型的提取效果。
因此,我认为可以采用Wikipedia和Wikidata(Wikipedia对应的知识图谱)为基础来实现知识图谱抽取和知识图谱抽取效果的评价。之前分享的浙江大学DeepKE-LLM项目已经构造多个待抽取文本和抽取后三元组的example。其中待抽取文本为150-300左右的段落,并且DeepKE-LLM项目将文本划分为12个主题,一千条记录,包含中文和英文。可以选择其中的一个或多个主题来作为输入。下面是一个example(JSON格式):
{"id": 1000000,
"cate": "Building",
"input": "Krasinski Square is a square located in the center of Warsaw, the capital of Poland. This square is famous for its numerous historical buildings. The history of the square dates back to the late 18th century.",
"relation":
[{"head": "Krasinski Square", "relation": "creation time", "tail": "the late 18th century"},
{"head": "Krasinski Square", "relation": "located in", "tail": "Warsaw"}, {"head": "Warsaw", "relation": "located in", "tail": "Poland"}]}
这个数据集的缺陷在于没有涉及到长文本的提取和没有涉及到属性提取。不过可以以此为基础来做。
- 一般情况下,用户并不乐意直接提供一大段文本用来实现知识图谱的构建。
因此可以通过输入关键词的形式,并采用爬虫机制,抓取相关的文本文档,并以抓取到的信息为基础,进行知识图谱的构建。例如,如果要做人物主题的知识图谱,用户输入关键词“欧拉”,之后采用爬虫抓取描述欧拉相关的维基百科信息,根据抓取到的信息为基础实现KG构建。
- 关于长文本的处理:
NaLLM项目是直接将文本进行简单的分割再抽取,这样很容易直接丢失上下文信息。考虑引入如下的机制:
(1)保留上下文信息:
这里引入的第一种技巧就是summary,这点主要是保留上下文的信息,有助于三元组和属性的抽取和完善。
需要注意的是 \(summary_{i-1}\)和\(text_i\)权重不同,效果也会不太一样。如果\(summary_{i-1}\)的权重比较大 ,则每次保留的上下文信息也就会越多越完善,但是每次可输入新的文本就会变少,总的消耗的token数和资源就会越。如果\(summary_{i-1}\)的权重较大,则每次保留上下文信息更少,可输入的文本就会变多,但是最终提取的完善度和精确度就会下降。
关于权重的控制,我认为主要是通过控制summary的长度来实现。
(2)滑动窗口
第二种技巧就是采用滑动窗口的方式实现,以防文本中同一三元组的不同部分划分到不同的块中。这里一般滑动窗口重叠的部分尽可能包含完整的语义比较合适,这样同一三元组划分到不同的块的概率会有所降低。
- 关于知识图谱三元组的提取
主要有如下三种思路:
(1)直接采用prompt从输入的文本中提取出三元组和对应的属性
这也是NaLLM项目的方法,采用1-shot方式,编写好system prompt和user prompt直接提取出所有的三元组和对应属性。这样的提取方式最为简单,但是提取的质量可能不会太好。
(2)先提取头实体,再根据头实体和关系来提取尾实体
这种方法我认为在确定模式的情况下实现更好一些。
这种做法的思路来源于论文《ITERATIVE ZERO-SHOT LLM PROMPTING FOR KNOWLEDGE
GRAPH CONSTRUCTION》,从直觉上来讲,这种提取的方法效果会有所提升。这是因为将知识图谱提取的大问题分解为一步步小问题,从而减轻大模型的处理压力。
先根据文本的输入提取所有实体和实体相关的描述信息。之后,我们获得了一系列的头实体,再根据模式中存在的关系为基础,这样就将问题转化为\((h,r,?)\) ,让大模型从实体相关的描述信息中找到最可能填入?的一系列实体。
在采用这个方法构建知识图谱过程中,可以尝试一下复杂关系的提取(如N元关系,特定关系等),编写好复杂关系的样例,来辅助大模型对尾实体的获取。
(3)先提取头实体,再提取尾实体,最后提取关系
这个感觉在不带模式的情况下可能好一些。也是论文《ITERATIVE ZERO-SHOT LLM PROMPTING FOR KNOWLEDGE GRAPH CONSTRUCTION》的做法。先根据输入文本生成头实体和头实体的相关描述,再从头实体的描述中找到所有和头实体有关的尾实体,最终根据确定的头实体和尾实体确定头实体和尾实体的关系。关键在于根据描述文本确定合适的谓词。谓词最好不要过于具体,也不要过于抽象和简单(感觉可以采用few-shot的方式来提示大模型什么样的谓词是合适的。
- 关于实体和关系属性的提取
(1)直接在提取三元组的过程中提取属性
这也是NaLLM项目的方法,prompt里编写的example中既包括了实体关系本身,也包括了实体和关系属性的提取。
(2)先生成实体和关系的文本描述,再以根据实体关系的描述为基础实现属性的提取。
这种方式相较于NaLLM来讲对问题进行了简化,属性的提取效果可能会好一些。不过由于属性提取本身十分灵活,最后属性提取的评价应该还是需要采用人工的方式来完成。
2. data_disambiguation
这一部分主要是去除之前提取结果中重复的实体和关系。
NaLLM项目的做法主要是类内去重(在上一步unstructed_data_extractor中大模型会给每一个实体和关系贴一个label),也是直接通过输入上一步提取到的实体、关系和对应属性,以0-shot prompt的方式要求大模型直接实现对实体和关系的去重,采用的prompt如下。
实体进行disambiguation的prompt:
def generate_system_message_for_nodes() -> str:
return """
Your task is to identify if there are duplicated nodes and if so merge them into one nod.
Only merge the nodes that refer to the same entity.
You will be given different datasets of nodes and some of these nodes may be duplicated or refer to the same entity.
The datasets contains nodes in the form [ENTITY_ID, TYPE, PROPERTIES].
When you have completed your task please give me the
resulting nodes in the same format.
Only return the nodes and relationships no other text. If there is no duplicated nodes return the original nodes.
Here is an example of the input you will be given:
["alice", "Person", {"age": 25, "occupation": "lawyer", "name":"Alice"}], ["bob", "Person", {"occupation": "journalist", "name": "Bob"}], ["alice.com", "Webpage", {"url": "www.alice.com"}], ["bob.com", "Webpage", {"url": "www.bob.com"}]
"""
也是要求大模型根据输入和合并完全相同的实体,同时限制了输入格式和输出格式。最后会得到一系列去重后的节点。
关系disambiguation的prompt:
def generate_system_message_for_relationships() -> str:
return """
Your task is to identify if a set of relationships make sense.
If they do not make sense please remove them from the dataset.
Some relationships may be duplicated or refer to the same entity.
Please merge relationships that refer to the same entity.
The datasets contains relationships in the form [ENTITY_ID_1, RELATIONSHIP, ENTITY_ID_2, PROPERTIES].
You will also be given a set of ENTITY_IDs that are valid.
Some relationships may use ENTITY_IDs that are not in the valid set but refer to a entity in the valid set.
If a relationships refer to a ENTITY_ID in the valid set please change the ID so it matches the valid ID.
When you have completed your task please give me the valid relationships in the same format.
Only return the relationships no other text.
Here is an example of the input you will be given:
["alice", "roommate", "bob", {"start": 2021}], ["alice", "owns", "alice.com", {}], ["bob", "owns", "bob.com", {}]
"""
关系disambiguation和实体disambiguation是类似的,不过也存在一定的区别。第一个区别是要求大模型去除不合理的关系,第二个要求是让大模型将头实体和尾实体替换为去重后的节点。
最终也是通过正则表达式的形式,对大模型输出进行匹配,返回去重后的节点和关系。
评价:
(1)可以考虑在提取过程中添加实体和关系的上下文信息,来辅助实体和关系的disambiguation。例如,苹果和苹果公司,如果属性不够完善,或者不加入上下文信息的话,可能很难实现区分。
(2)可以尝试引入few-shot,让大模型去更好的理解disambiguation的含义。列举一些在语境中,一词多义和多词同义的情况辅助大模型辨别。提取的样例进行disambiguation的难度尽可能大,这样大模型在做disambiguation的过程中参考价值也会越大。
(3)对关系进行disambiguation过程中,对make sense的情况尽可能详细的说明。什么情况是make sense的。需要满足,头实体和尾实体本身是正确的并且存在于文本中,并且描述头实体和尾实体的谓词是合理的,并且这个谓词可以从文本中推理得到,而不是来源于大模型内部的知识库。
3. data_to_csv
这个主要将上面返回的结果转换为CSV文件,便于存储到本地,并将后面将提取的结果存储到图数据库中,也是依靠大模型来完成。
def generate_system_message() ->str:
return f"""
You will be given a dataset of nodes and relationships。Your task is to convert this data into a CSV format,
Return only the data in the CSV format and nothing else.Return a CSV file for every type of node and relationship.
The data you will be given is in the form [ENTiTY,TYPE,PROPERTIES] and a set of relationships in the form [ENTITY,RELATIONSHIP,ENTITY2,PROPERTIES].
Important:If you don't get any data or data that does not follow the previous mentioned format return "No data" and nothing else.
This is very important: If you don't follow this instruction you will get a 0.
"""
转换的一个示例:
CSV:
Entity,Properties
alice:Person,{"age":18}
bob:Dog,{"age":7}
Subject,Relation,Object,Properties
alice,roommate,bob,{"start": 2021}
alice,owns,alice.com,{}
bob,owns,bob.com,{}
二. Chat with KG
主要还是通过两部分,先通过in-context learning的方式(4-shot)将用户问题转化为Cypher查询并执行。之后将查询的结果以prompt形式传递给大模型,经润色后得到结果。
效果:
NaLLM项目初始连接的为“companies”主题的公开neo4j图数据库。
连接公司这一公开的图数据库时,在4-shot条件下,大模型的问答效果表现还是比较好的,下面是运行的示例:
所连接的图数据库样例(共有237258个节点,389984个关系):

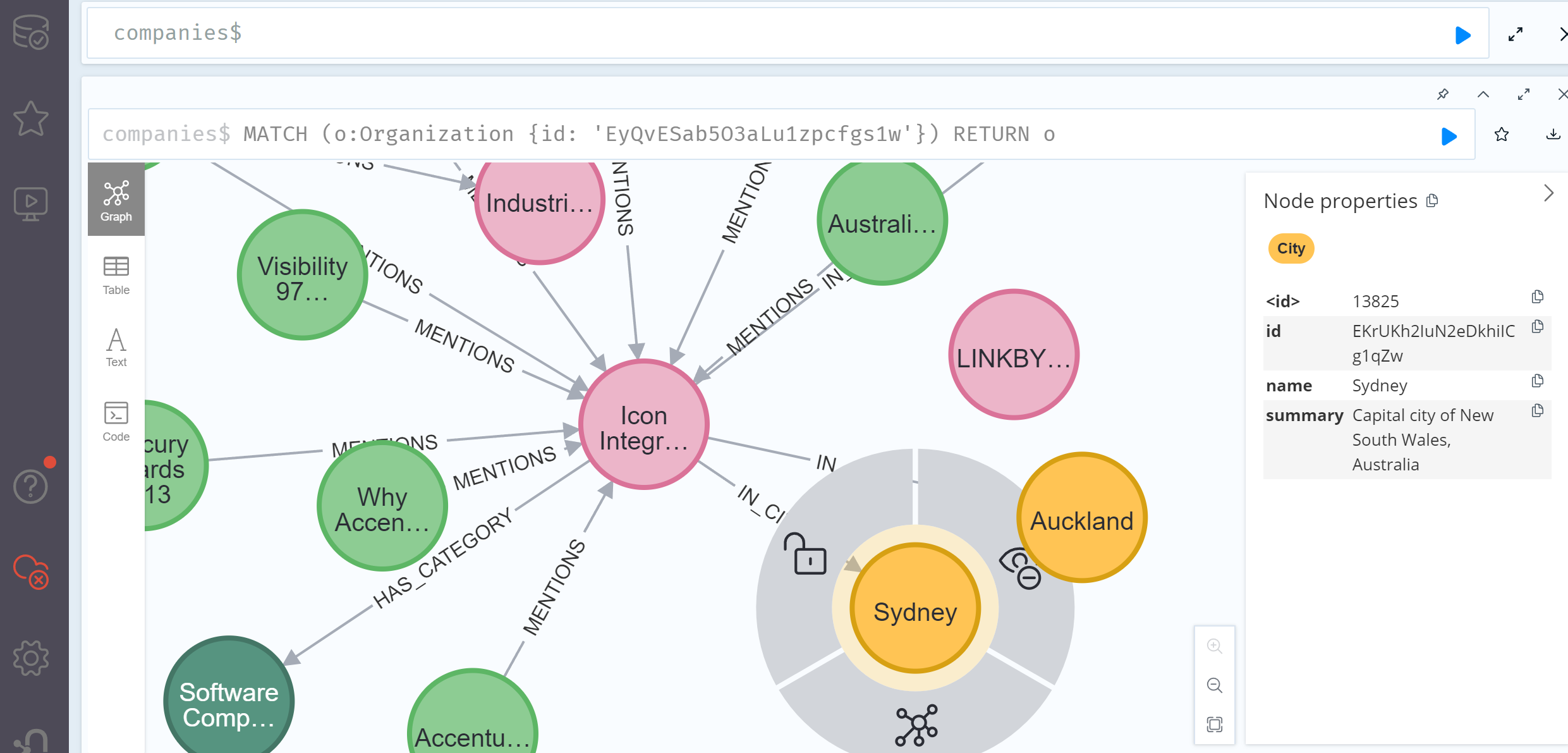
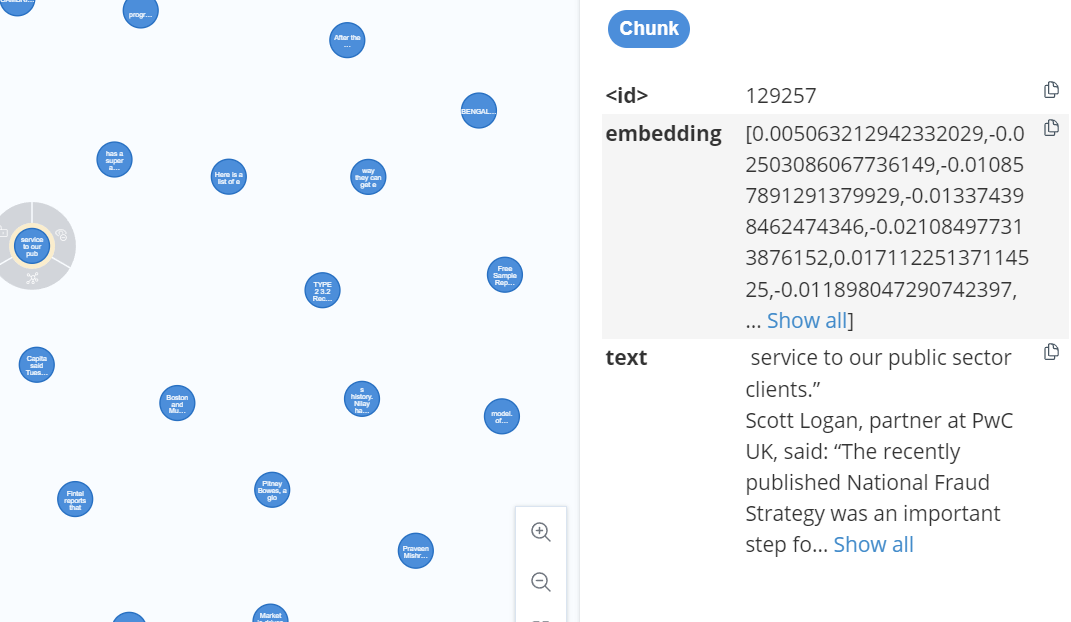
这个图数据库也会尝试将一些文章的文本分块后做embedding作为一个节点,存放在图数据库中,如下所示:
尝试让大模型实现二跳和三条问答:

关于知识图谱上的多跳问题都回答上来了,表现很好。
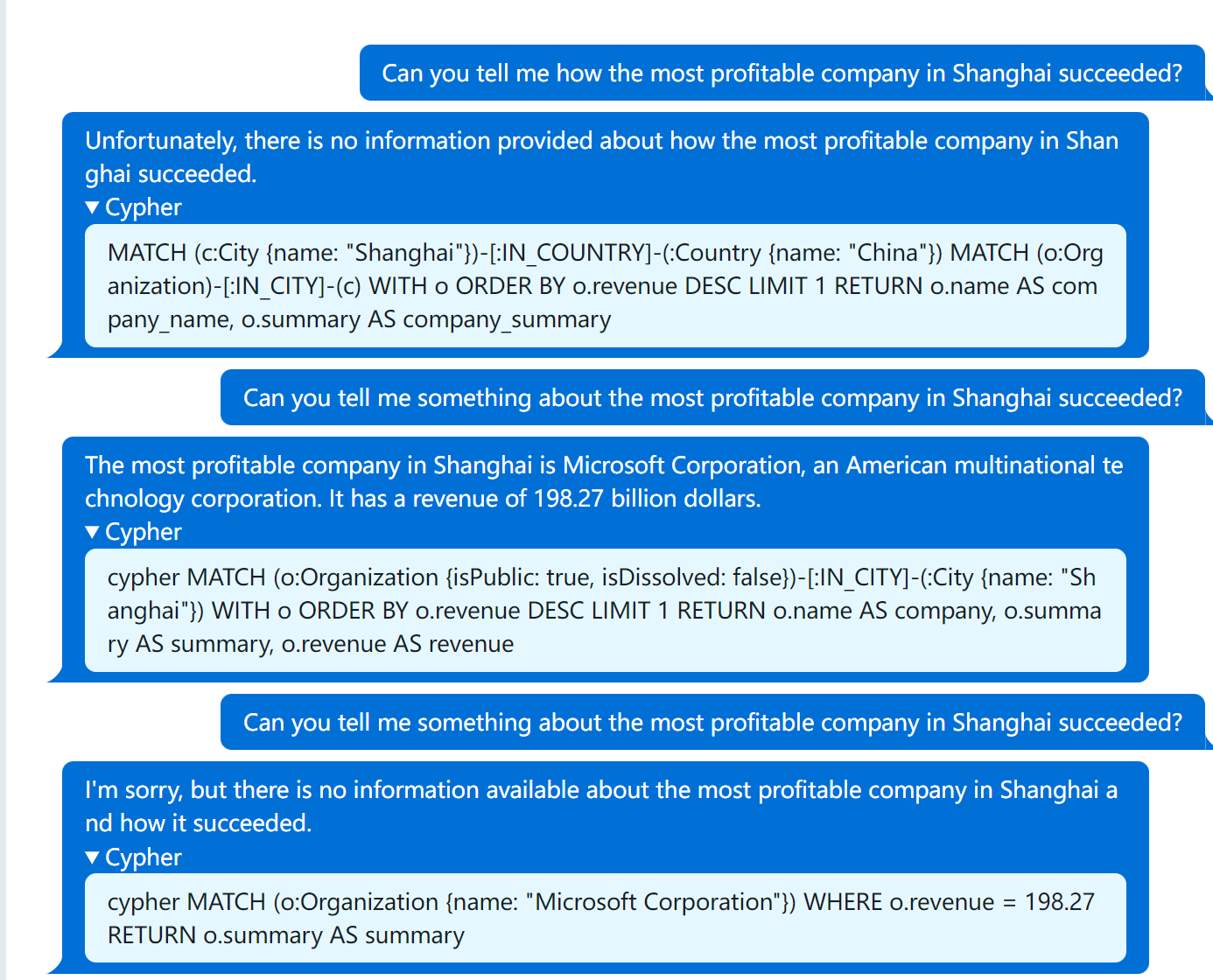
构造的比较复杂的问题:当大模型对话次数变多的时候,大模型也会有一些胡言乱语的现象,比如最后的问题语义理解错了,这部分可能需要精简prompt。而且第一个问题也没有尝试从公司相关article的chunk中(需要做embedding)查询相关信息。
1. text2cypher
这个模块主要是将用户输入的问题转化为neo4j中的Cypher查询。
采用的prompt主要包含如下部分:
Your task is to convert questions about contents in a Neo4j database to Cypher query the Neo4j database.
Use only the provide relationship types and properties.
Do not use any other relationship types or properties that are not provides
如果连接的数据库提取过schema(图数据库节点属性、关系属性和关系本身集合)并且无法转换Cypher的话,要求利用提供的模式解释无法转化的原因。
if self.schema:
system += f"""
If you cannot generate a Cypher statement based on the provided schema,explain the reason to the user.
Schema:
{self.schema}"""
同时,通过in-context learning的方法(提出了4个example)辅助大模型进行转化,对应的prompt如下:
if self.cypher_examples:
system += f"""
You need to follow these Cypher examples when you are constructing a Cypher statement.
{self.cypher_examples}"""
采用的example例子(特定图数据库中的example),
对于提问的较为复杂的问题,也尝试了采用embedding的方法检索:
#How is Emil Eifrem connected to Michael Hunger?
MATCH (p1:Person {{name:"Emil Eifrem"}}), (p2:Person {{name:"Michael Hunger"}})
MATCH p=shortestPath((p1)-[*]-(p2))
RETURN p
#What are the latest news regarding Google?
MATCH (o:Organization {{name:"Google"}})<-[:MENTIONS]-(a:Article)-[:HAS_CHUNK]->(c)
RETURN a.title AS title, c.text AS text, c.date AS date
ORDER BY date DESC LIMIT 3
#Are there any news regarding return to office policies?
CALL apoc.ml.openai.embedding(["Are there any news regarding return to office policies?"],
"{openai_api_key}") YIELD embedding
MATCH (c:Chunk)
WITH c, gds.similarity.cosine(c.embedding, embedding) AS score
ORDER BY score DESC LIMIT 3
RETURN c.text, score
#What is Microsoft policy regarding to the return to office?
CALL apoc.ml.openai.embedding(["What is Microsoft policy regarding to the return to office?"], "{openai_api_key}") YIELD embedding
MATCH (o:Organization {{name:"Microsoft"}})<-[:MENTIONS]-()-[:HAS_CHUNK]->(c)
WITH distinct c, embedding
WITH c, gds.similarity.cosine(c.embedding, embedding) AS score
ORDER BY score DESC LIMIT 3
RETURN c.text, score
最后是输出的一些要求:
system += """Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement. This is very important if you want to get paid.
Always provide enough context for an LLM to be able to generate valid response.
Please wrap the generated Cypher statement in triple backticks (`).
"""
return system
最终让大模型实现将用户问题转化为Cypher查询。
如果生成的Cypher查询在图数据库中执行错误的话,则会尝试收集执行错误的system prompt、用户问题和错误cypher查询反馈给大模型,让大模型再执行一次转化过程(仅额外执行一次)
评价:
(1)NaLLM项目实现的为利用大模型将用户问题转化为Neo4j上的Cypher查询。可以尝试采用RDF数据模型的SPARQL以及其他图数据库上检索语句生成。这一点可以尝试参考Langchain如何实现,并在其他的图数据库上尝试使用系统优化。
(2)NaLLM项目所连接的数据库为Company主题的公开数据库,尝试连接不同的数据库,并编写不同的example。
(3)NaLLM项目中的example中缺少需要复杂推理的问题。假设用户的问题需要多步推理才能完成,那么就需要大模型尝试利用CoT的技巧生成Cypher查询,并尝试利用大模型将复杂问题实现分解并合并。
(4)错误处理问题,假设在图数据库中无法查询到相应节点关系或者大模型转化的Cypher语句存在问题,如何将这些错误以相对友好的形式反馈给用户。
(5)用户问题本身存在问题(如拼写错误等),尝试利用大模型推断用户意图。
2. summarize_cypher_result
这一部分主要将上面转化的cypher查询以用户友好的方式转化给用户。
system prompt要求的两件事情,根据用户的问题生成友好的回答、并且要求大模型不能够在答案中提出任何和问题无关的信息。
采用的System Prompt为:
system = f"""
You are an assistant that helps to generate text to form nice and human understandable answers based.
The latest prompt contains the information, and you need to generate a human readable response based on the given information.
Make the answer sound as a response to the question.
Do not mention that you based the result on the given information.
Do not add any additional information that is not explicitly provided in the latest prompt.
I repeat, do not add any information that is not explicitly given.
Make the answer as concise as possible and do not use more than 50 words.
"""
采用的Answer Prompt为:
return f"""
The question was {question}
Answer the question by using the following results:
{[remove_large_lists(el) for el in results] if self.exclude_embeddings else results}
"""
这个remove_large_list函数为将查询到的节点或关系中属性内容长度过大进行简化后再提供给大模型。
评价:
(1)NaLLM项目是直接尝试将非结构化信息(文章划分为若干chunk)做embedding后存放在neo4j中,作为知识图谱的一部分,并根据查询后的结果作为prompt送给大模型润色后得到答案。若直接将原始文本进行分块后再进行向量检索得到非结构化信息,在知识图谱中查询结构化信息,并以Unstructed_information和structured information合并反馈给大模型,感觉这种方法可能会获取更多有意义的信息,提供的上下文参考价值可能会越大。
(2)生成满足不同用户不同风格的答案。
(3)缓解大模型在多轮对话后发生的幻觉问题。
本文来自博客园,作者:zjz2333,转载请注明原文链接:https://www.cnblogs.com/zjz2333/p/17868588.html
