论文阅读:InstructIE: A Chinese Instruction-based Information Extraction Dataset
主要提出了一种数据集Instruction-based IE,要求模型根据指令来提取信息。
1. Instruction
为IE任务创建特定的数据集式消耗事时间与资源的。
面对这些挑战的常见方法:
Seq2seq提出
TANL将其视为自然语言增强的翻译任务。
UIE提出一种text-to-structure的生成框架来面对多重的IE任务。
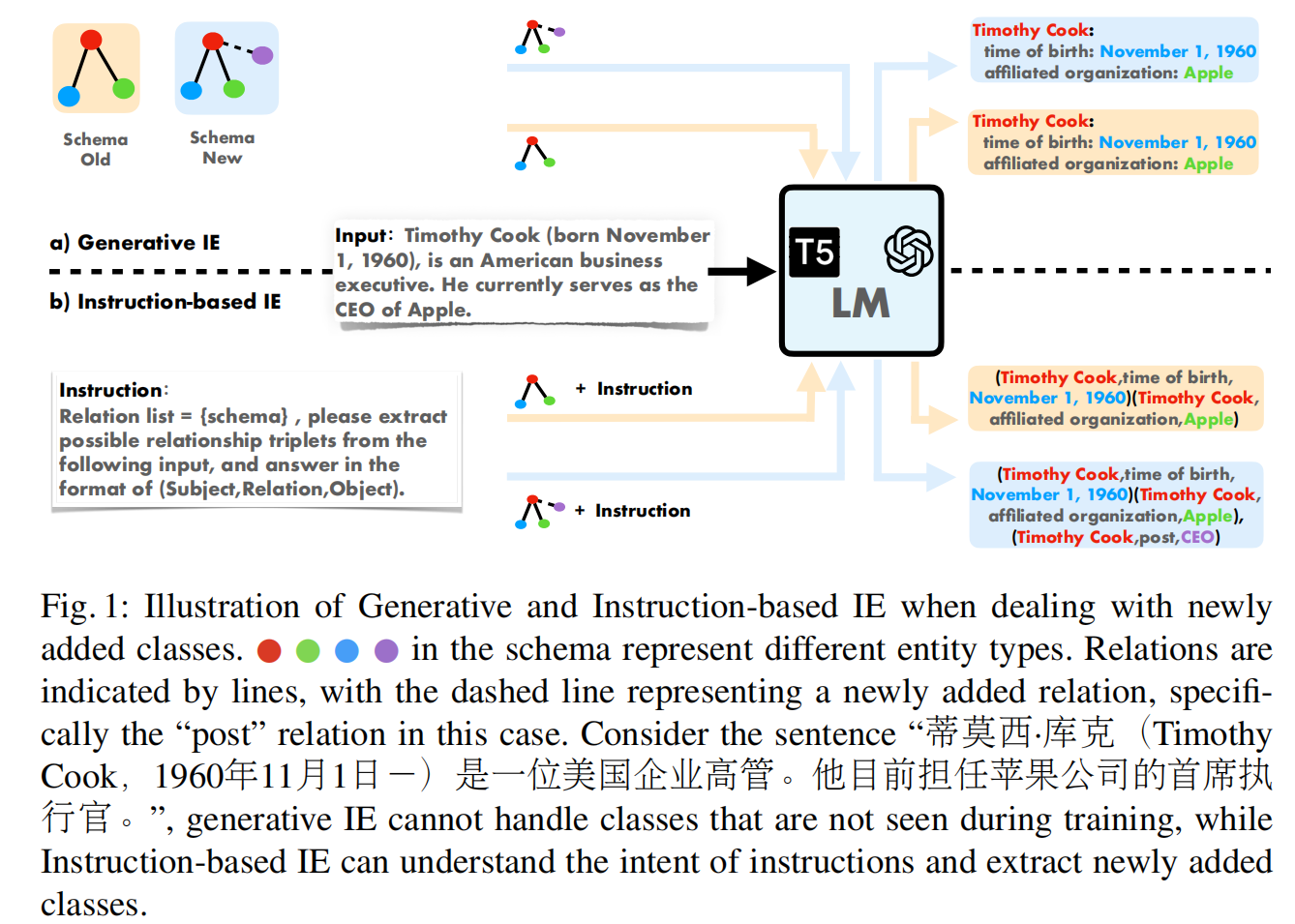
存在的缺陷:
训练过程中模式固定,难以应用到测试过程。
once-and-for-all训练
而Instruction-based IE可以实现指令的变化导致结果的变化,更加先进。
本数据集包含270000弱监督数据(来源于中文Wikipedia),
1000个经过高质量注释的数据。
2 Task Definition:Instruction-based IE

将IE视为指令驱动的文本生成任务。
指令名为\(I\),自然语言形式的处理要求
提取要求\(S\),需要提取的实体/类型的类别
格式要求\(T\),一般要求JSON字符串形式或者元组形式
整体格式如下:
\(Y=M(I,X)\)

3 Dataset Construction for InstructIE
3.1 Data Source
主要包含两大部分:Wikidata和Chinese Wikipedia
Chinese Wikipedia:提取维基百科的文档,划分为若干段落(50-300字符),
最终得到1.8million段落
Wikidata:知识图谱,采用Wikidata的一个子集
3.2 Data Preparation
为特定的段落分配主题可以简化注释的过程。
训练一个段落的分类器(5000 labeled数据)。
最终分为12个topic和设计相关的模式模板。
分类结果如下:
3.3 Dataset Construction
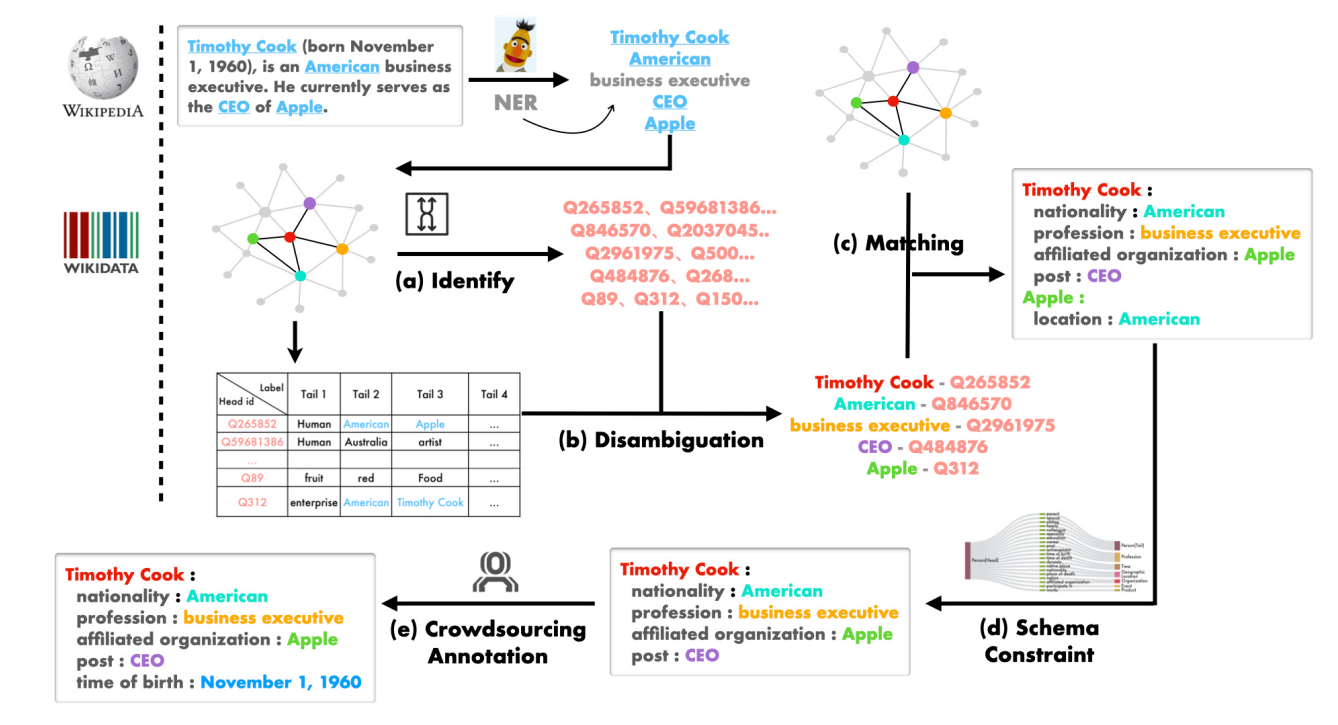
主要划分为如下的若干步:
Identifying all entity mentions
利用中文NER模型识别出尽可能多的提及的实体
Disambiguating
获取文本中提及的实体对应的Wikidata(知识图谱)中的ID,
相同名称的实体可能对应不同的ID,
提出一种简单的语义消歧的方法。
如下所示:

该实体ID与对应相邻接的实体在段落中存在的次数越多,
则选择该ID的可能性就会越大。
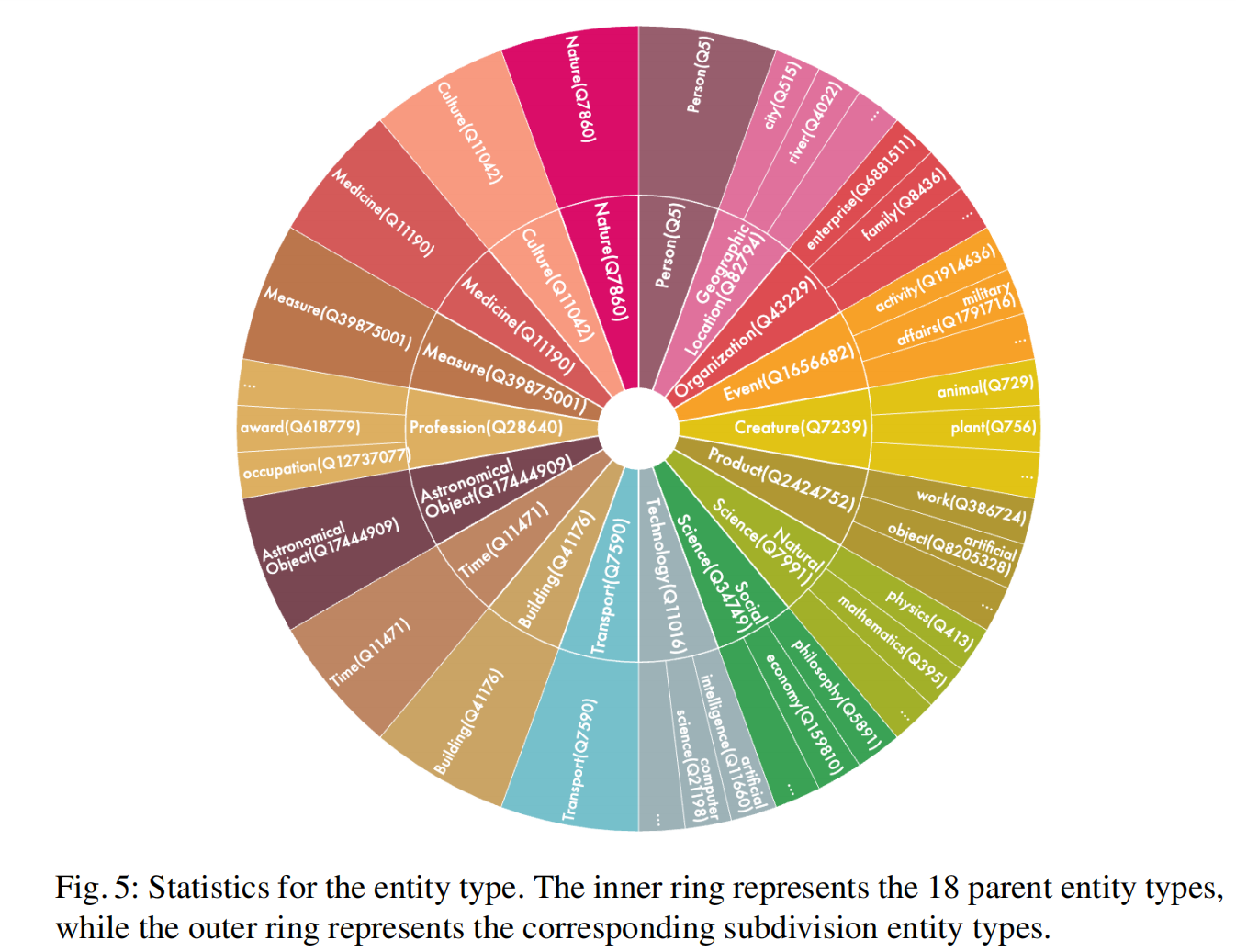
同时,将实体进行分类,得到实体类型(entity type),
作者将其分为了18类。
Matching
根据M段落中实体在KG中确定实体的关系,
需要注意的是,这种方法可能会导致生成许多无关的关系,
例如,在通用领域中,Apple与American是location的关系,
但是,在person主题中,这两个实体之间应该是没有关系的。
Schema-Constraint
为12种主题确定了模式的约束,
只有两端的实体均满足约束,KG的关系才是有效的。

Crowdsourcing Annotation
多轮多人注释
3.4 Dataset Statistics
训练集与测试集的规模:
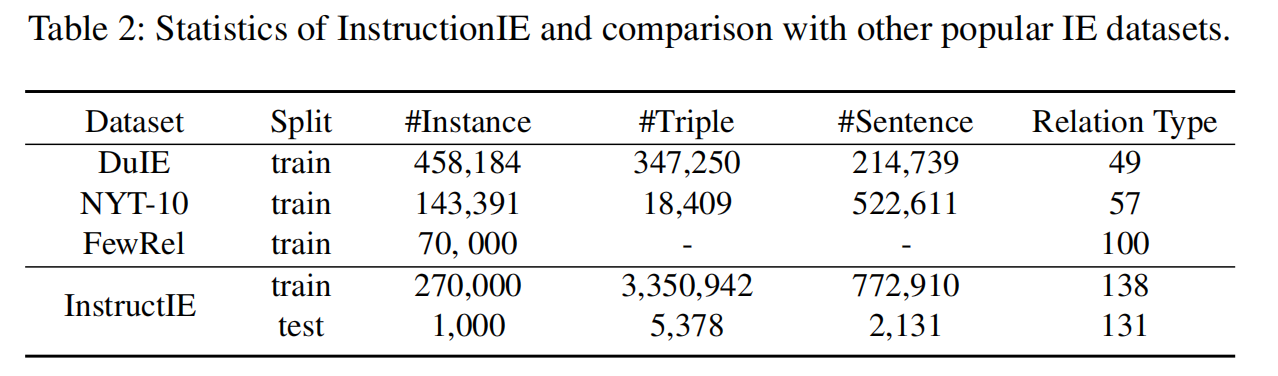
270000弱监督数据进行训练,
1000注释数据作为测试。
数据中主题的分布:
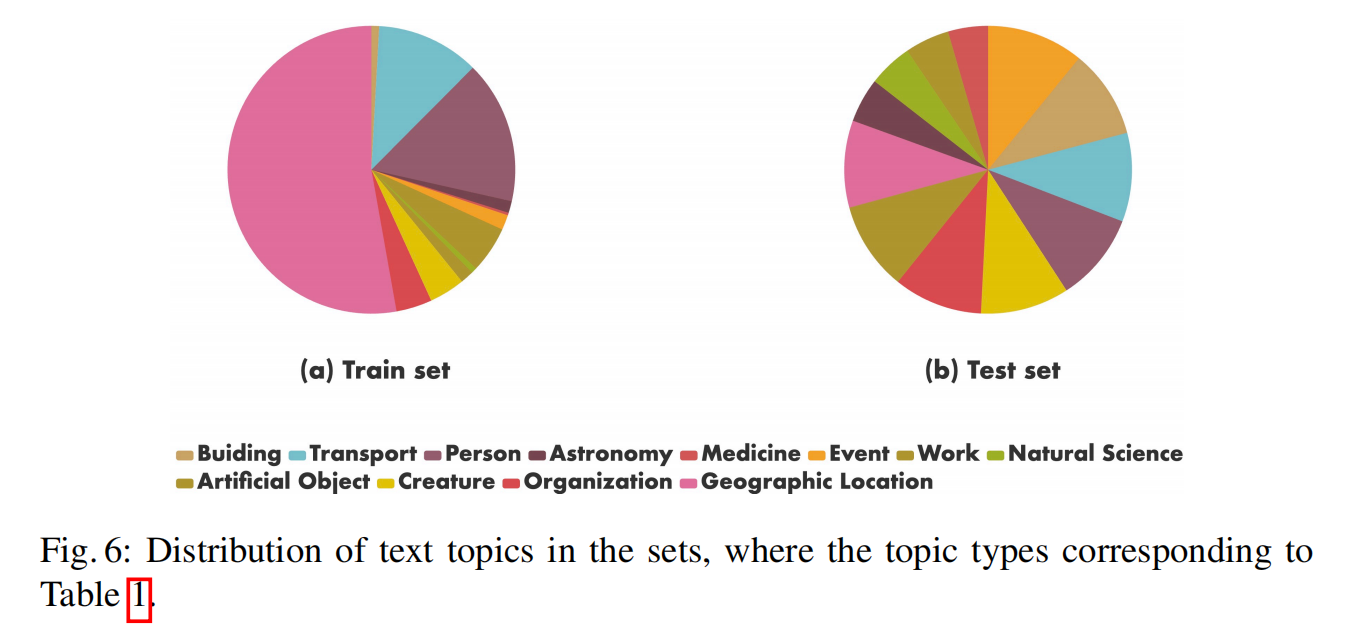
4 Experiments
采用的技术主要包括:
In-Context Learning,LoRA和Fine-Tuning
4.1 Baselines
- MT5:在Common Crawl-based dataset预训练,支持多种语言的T5模型
- ChatGPT:指令驱动
- LLaMA:基础语言模型的集合(7B到65B),本次实验采用7B与13B
- Alpaca:Instruction-following的LLaMA
- CaMA:在中文语料库与英文语料库预训练的模型(基于LLaMA-13B)
4.2 Evaluating Setting
ICL:500个例子中随机抽取5个作为prompt
LORA:采用框架Alpaca-LORA
评价指标:
Micro-F1:三元组完全正确。
ROUGE-2:在模型输出与正确结果分解为2-grams条件下,有多少元组匹配
最终评价:
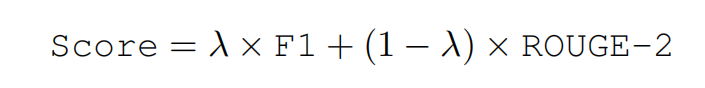
4.3 Experiment Results
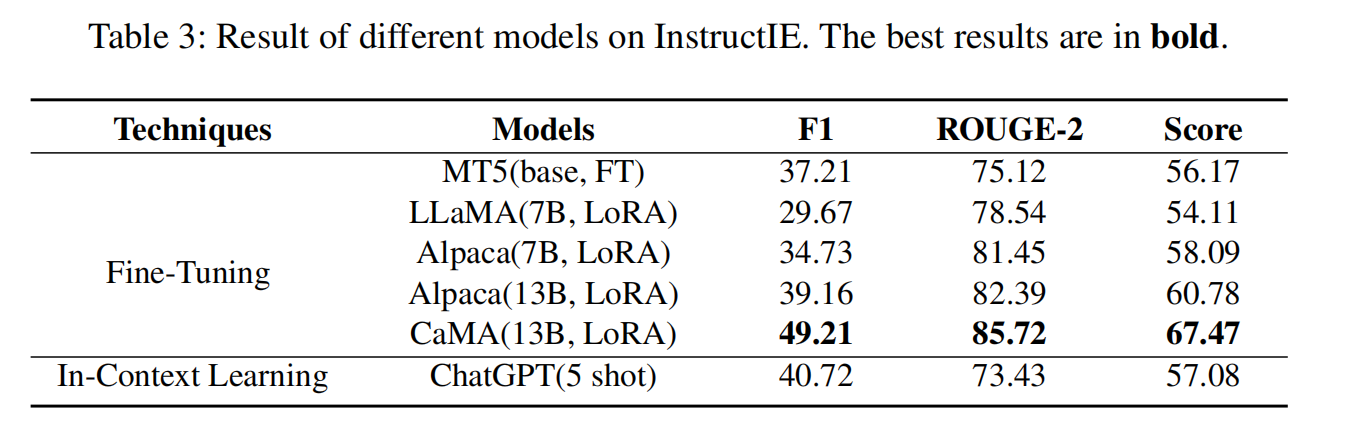
CaMA-13B-LoRA表现最好
ChatGPT(ICL)其次。
Model and Size
Alpaca表现较于LLaMA更好(对指令的理解能力更强)
同时增大模型的规模,也有助于提升模型的能力
LoRA vs Fine-tuning
M较小规模模型(MT5)上微调与在大规模模型LoRA达到了类似的效果。
(Fine-tuning修改全部参数,LoRA修改部分参数)
4.4 Experiment Analysis
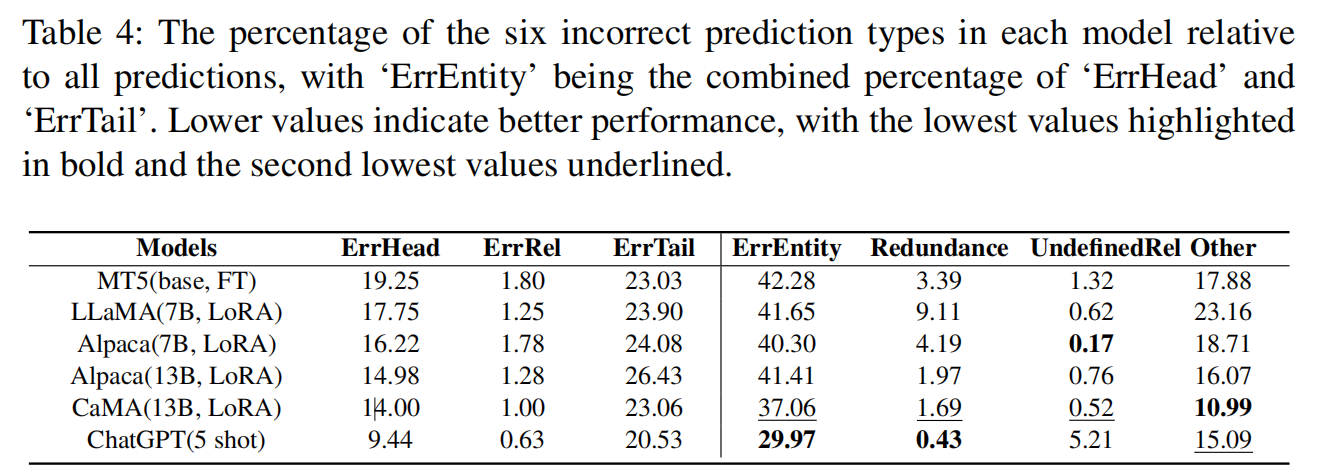
不同模型在不同类型的错误中犯错的概率如上所示。
一般来讲,所有模型在ErrRel与UndefinedRel中犯错的概率是较小的,
而在ErrEntity中犯错的概率较大,
Other表明模型也会生成多余与不相关的信息。
CaMA在Other表现最好,其他指标表现也不错
而ChatGPT采用ICL方法后再UndefinedRel表现较差
本文来自博客园,作者:zjz2333,转载请注明原文链接:https://www.cnblogs.com/zjz2333/p/17806449.html
