论文阅读:DeepKE:A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
DeepKE,支持数据集和模型的结合来实现非结构化数据中信息的提取。
同时提出框架和一系列的组件来实现足够的模块化和可扩展性。
项目地址
先根据paper做一个介绍
1. Introduction
现存的KB是在实体和关系方面是不完备的。
常见的一些标志性的应用:
- Spacy(实体识别)
- OpenNER(关系提取)
- OpenIE(信息提取)
- RESIN(事件抽取)
存在的问题:各个现存的工具仅支持一种任务,同时难以应用在复杂的现实世界中(文档和多模态级别的数据)
本篇文章提出开源知识提取工具名为DeepKE。
支持:少资源、文件和多模态设置
并提供模块化和自动超参数优化
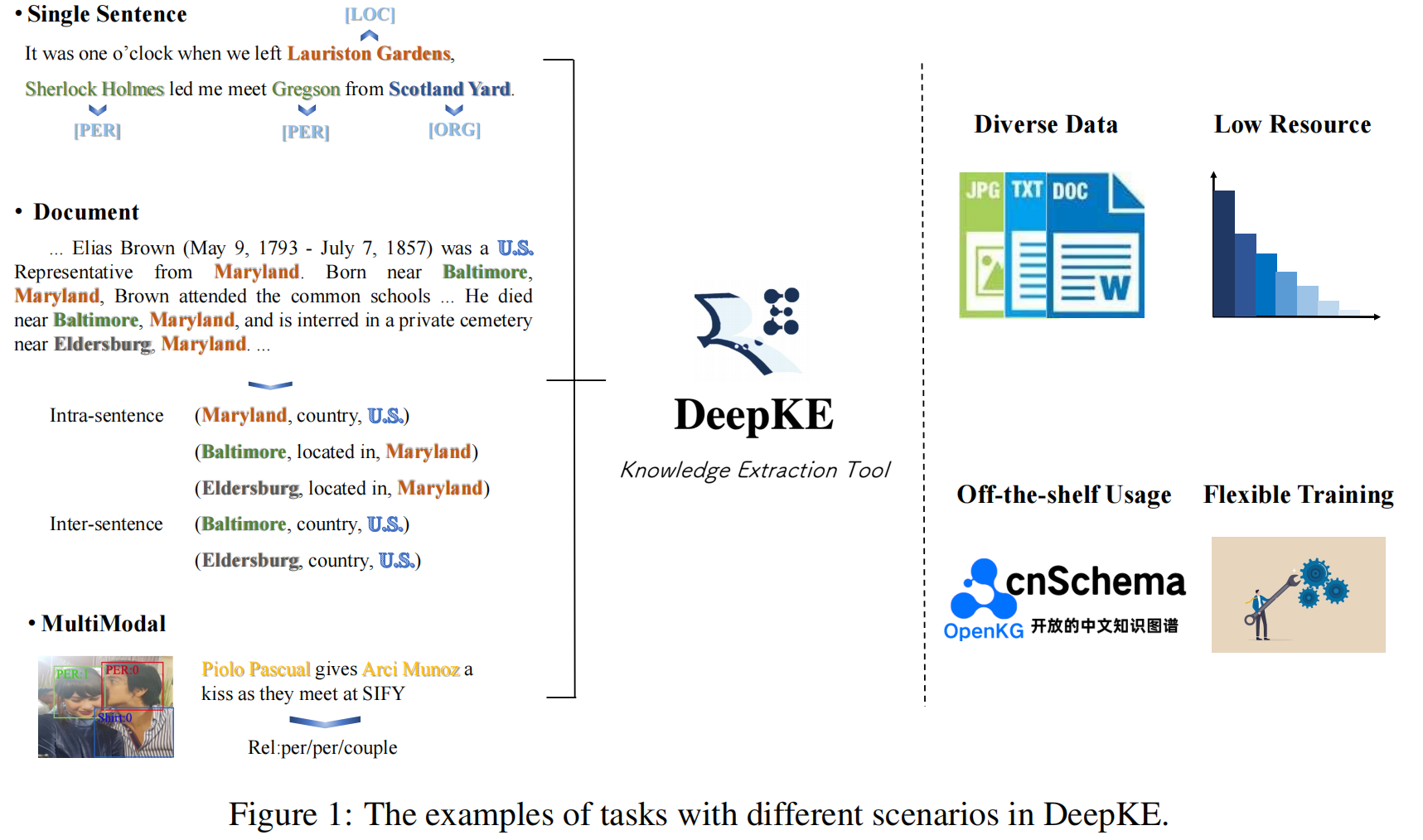
主要内容如上所示
2. Core Functions
主要是实体识别、关系识别与属性识别
2.1 Named Entity Recognition
输入句子,找到特定的实体和对应的类型
采用预训练的语言模型去编码句子并进行预测。
支持few-shot和多模态
2.2 Relation Extraction
提供了多种多样的模型
如CNN、RNN、GCN、Transformer、BERT。
在节省资源方面,采用了一种KnowPrompt方式。
在文件领域,主要采用了一种DocuNet的方式
2.3 Attribute Extraction
给定句子、实体和属性的描述
DeepKE可以推断属性的类型
3 Tooklit Design and Implementation
本工具包主要包含如下方面:
- 为多种任务提出统一的框架:data、model和core
- 提供超参数自动训练和评估,并提供docker提升运算效果
- 提供预训练的模型进行信息的提取
3.1 Data Module
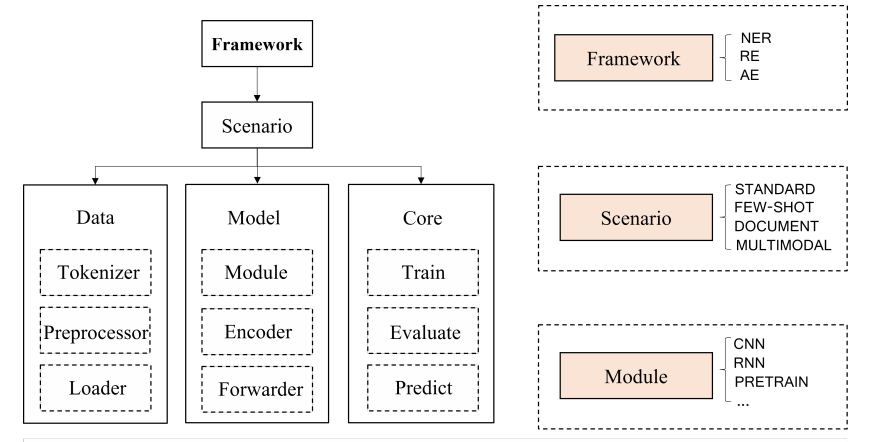
tokenizer可处理英文和中文的信息,
在多模式设置条件下也可以实现视觉信息的处理。
用户输入自身的数据集,处理后得到一系列的tokens或image patches
3.2 Model Module
支持CNN,RNN,Transformer等神经网络模型。
同时,在不同的任务场景下,也会尝试采用不同模型
如在标准的RE任务,采用BERT,在NER采用BART
3.3 Core Module
train用填入期望的参数,如(模型、数据、epoch、损失函数等)
validate主要用于评估
predict用于结果的获取
3.4 Framework Module
将上述三个部分和不同场景相组合,
用户可以自动修改超参数
4 Toolkit Usage
支持低资源NER(prompr guided)与RE(prompt-tuning)
同时支持文件级别的关系提取,预测一个实体级别的关系矩阵来实现局部和全局信息的获取。
在多模态领域,采用了一种IFAformer方式。
同时采用网页名为:http://deepke.zjukg.cn

5 Experiment and Evaluation
5.1 Single-sentence Supervised Setting
实验结果如图所示:
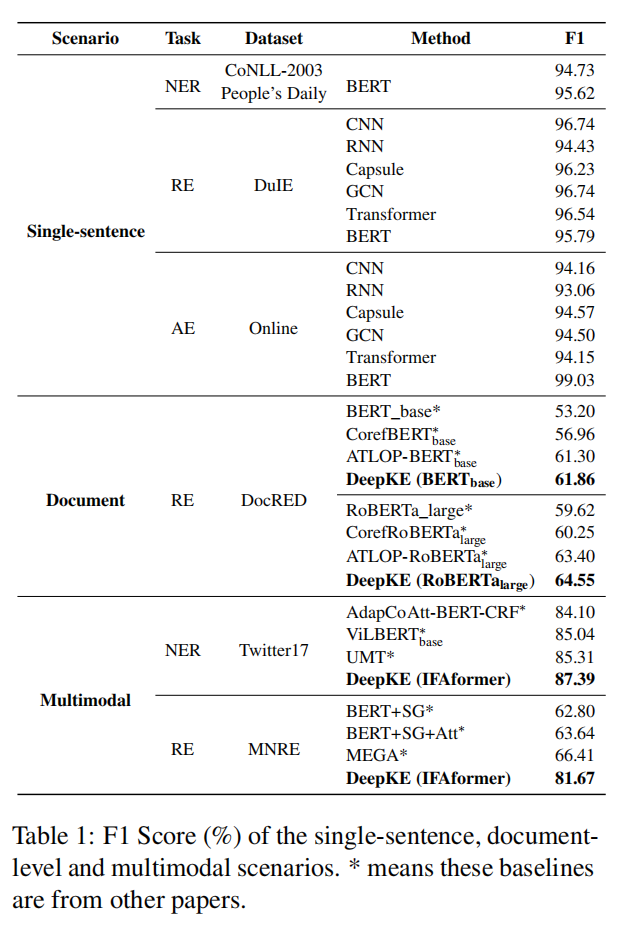
Named Entity Recognition
主要在两个数据集上验证:
CoNLL-2003和People‘s Daily。
英文包含四类,person(PER),locations(LOC),organization(ORG),
miscellaneous(MISC)
中文包含上述的前三类。
模型的表现很优越。
Relation Extraction
在中文数据集DuIE,十种类型。
每个实例中包含一个句子,一个头实体,一个尾实体,offset和关系。
Attribute Extraction
数据集为网页上的https://github.com/leefsir/triplet_extraction
每个实体标注属性类型,值和offset
附录:
A Toolkit Usage Details
如何详尽的使用DeepKE
A.1 Build a Model From Scratch
准备运行环境
两种方式:Anaconda或者docker
安装:pip install deepke
修改源代码,需要:python setup.py install / develop
所有的数据需要放在data的目录中
实体识别
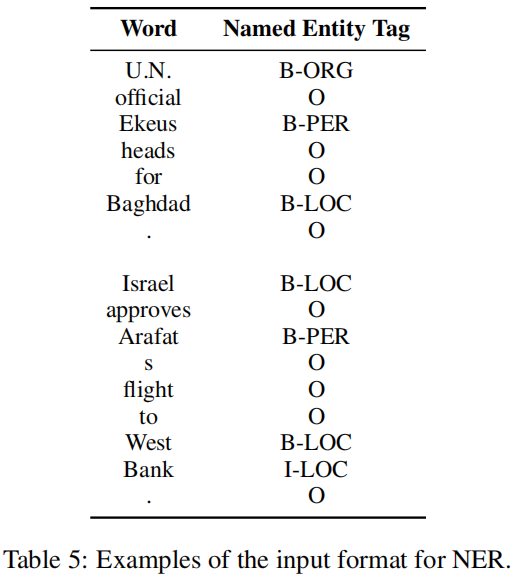
主要包含:输入数据和对应标签,如上例所示。
所有如上所示的数据会被送给NER模型,
采用run.py来fine-tuned NER模型,
然后predict.py来对输入的句子进行预测
关系识别
在单个句子和few-shot上面训练的格式是类似的。

同时,也支持在文件级别的关系提取。
输入包含标题,句子(分解为单词和标点符号)
实体集合(实体被提及的名字,对应句子标号,偏移量,类型)
关系标签(头实体和尾实体的标号,关系和evidence的id)

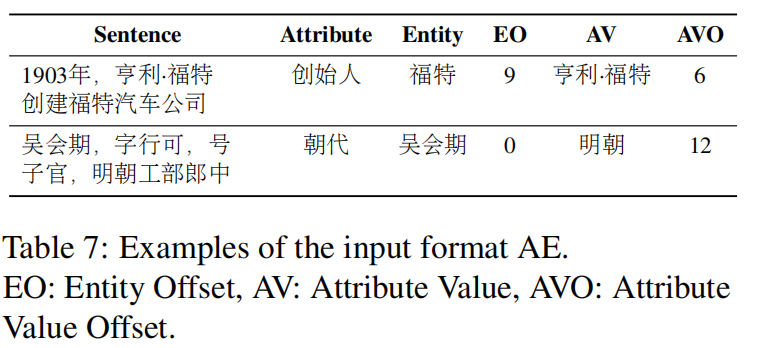
Attribution Extraction
主要包含如下:句子,属性类型,实体,实体标签,与实体相关的属性值与其对应的偏移量。
最后可以得到一个fine-tune的AE model
A.2 Auto-Hyperparameter Tuning
采用Weight& Biases的机器学习工具包
本文来自博客园,作者:zjz2333,转载请注明原文链接:https://www.cnblogs.com/zjz2333/p/17788132.html
