论文阅读: Co-design Hardware and Algorithm for Vector Search
1. Introduction
介绍一下论文背景,
向量检索常用于 搜索引擎,推荐系统,LLM和科学计算等
对应的常用的硬件向量检索方法,IVF-PQ
其中IVF:将多个向量聚类, PQ将向量压缩
而为了最大化IVF-PQ的效果,也会面临很多的挑战
在芯片设计的过程中,会遇到针对六个阶段如何设计合适的微架构?如何将有限的资源分配给六个阶段等问题。所以这篇文章对特定的算法参数进行优化,以实现performance-recall的平衡。
本篇文章提出了FANNS,一个端到端加速器生成框架(依据IVF-PQ算法),
会根据目标数据集和召回率的需求,实现硬件资源和算法的平衡,以最大化加速器的性能。
基本工作流如下:
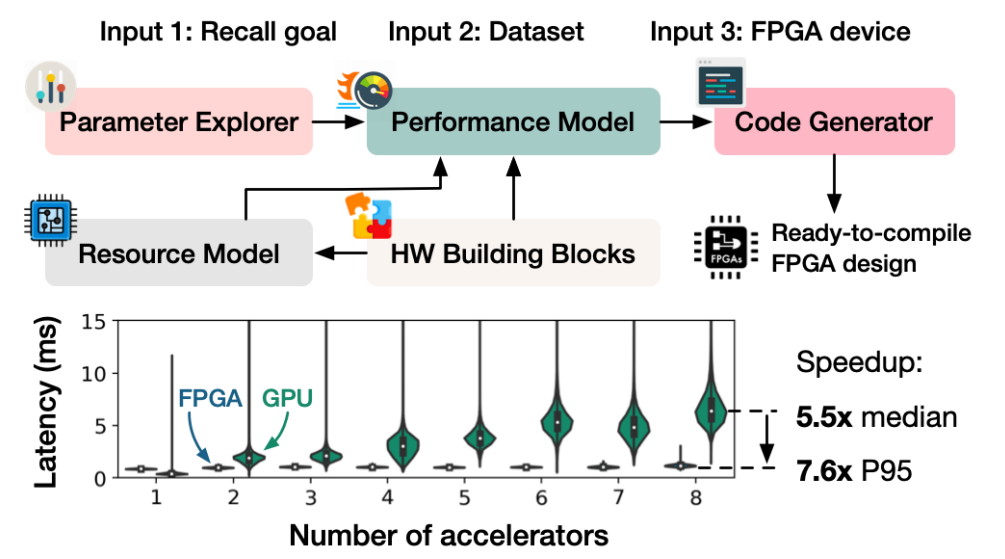
首先,FANNS会评估数据集召回率要求和IVF-PQ参数间的关系,找到所有合适的加速器设计。
之后,FANNS性能评估模型预测每个算法参数和硬件组合的QPS(queris-per-second)
最后,选择最好的组合,生成合适的FPGA代码。
同时,FANNS支持在加速器中实例化TCP/IP栈。
结果:
和固定的FPGA设计,提升了23倍。和CPU相比,提升了37.2倍。
单个GPU的运算效率强于设计的FANNS,但是,多个单元配合时,FPGA效率明显更高。
2. Background
2.1 The IVF-PQ Algorithm
主要分为两个模块:
Inverted File(IVF) Index
通过kmeans方法将所有向量划分为多个泰森多边形,每次查询只有临近的单元被扫描到,降低工作量。
Product Quantization(PQ)
二维图示如下:
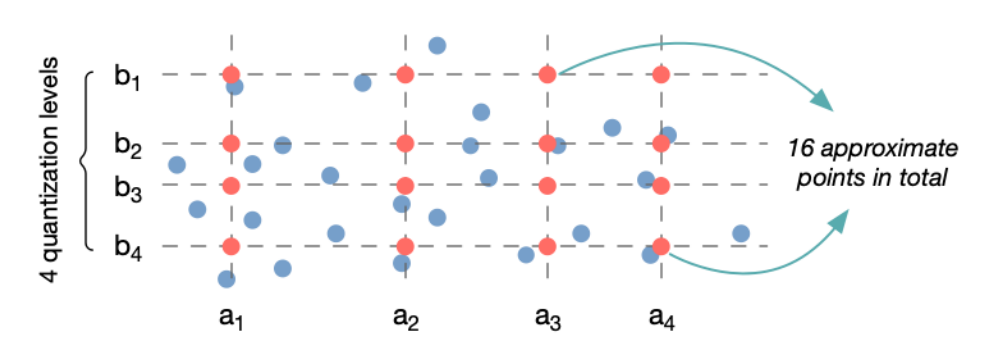
核心思想为通过cluster ID来代替原始的sub-vector。
OPQ是PQ算法的改进版,通过采用正交矩阵对空间进行变换,让各方向的方差尽可能的一致。
The Six Search Stages at Query Time
- OPQ变换
- IVFDist:衡量询问向量和各个中心间的距离
- SelCell:选择最邻近的cell进行扫描
- BuildLut:为衡量询问向量和PQ表示向量间的距离,构建距离查询表
- PQDist:计算距离近似值
- SelK:选择K近邻
3. Hardware-Algorithm Design Space
主要的挑战为如何在巨大的algorithm-hardware设计空间中找到合适的选择。
不同的参数会影响算法召回率和性能瓶颈。
同时,应用PQ算法也对应多种硬件设计思路。
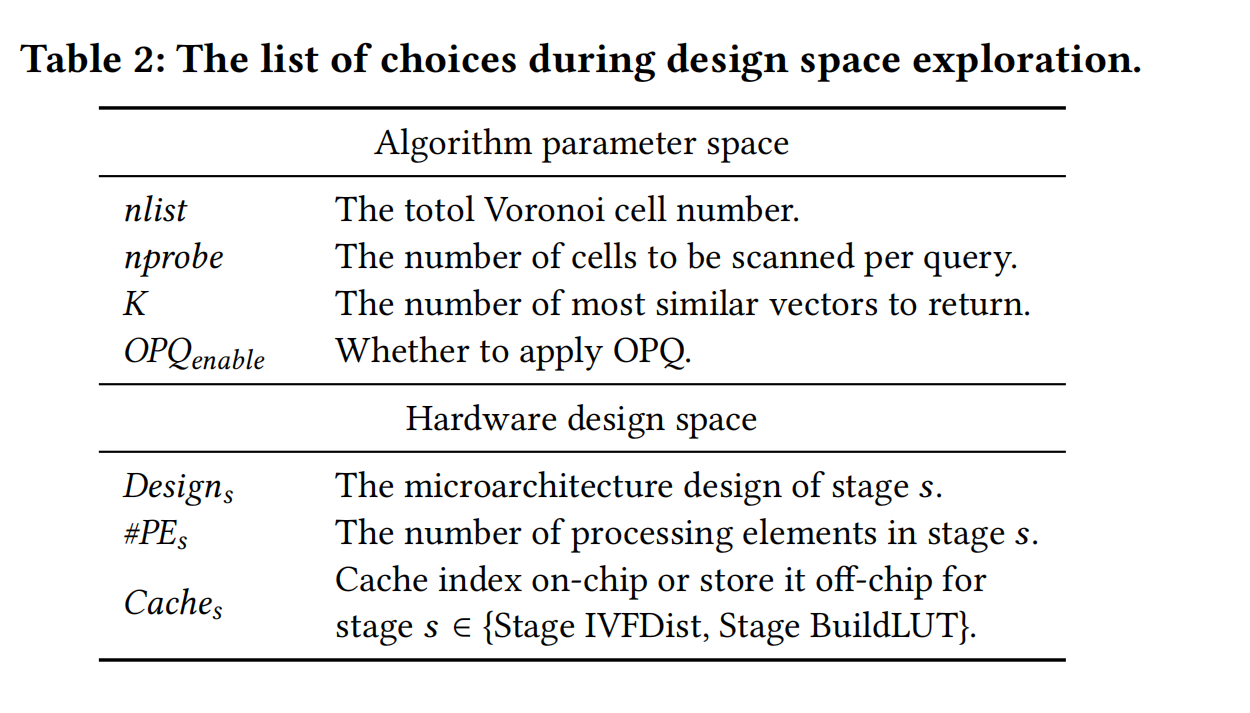
3.1 Algorithm Parameter Space
加速器设计的要求需要在任意的参数实现可接受的性能或者在特定的参数实现最佳的性能。
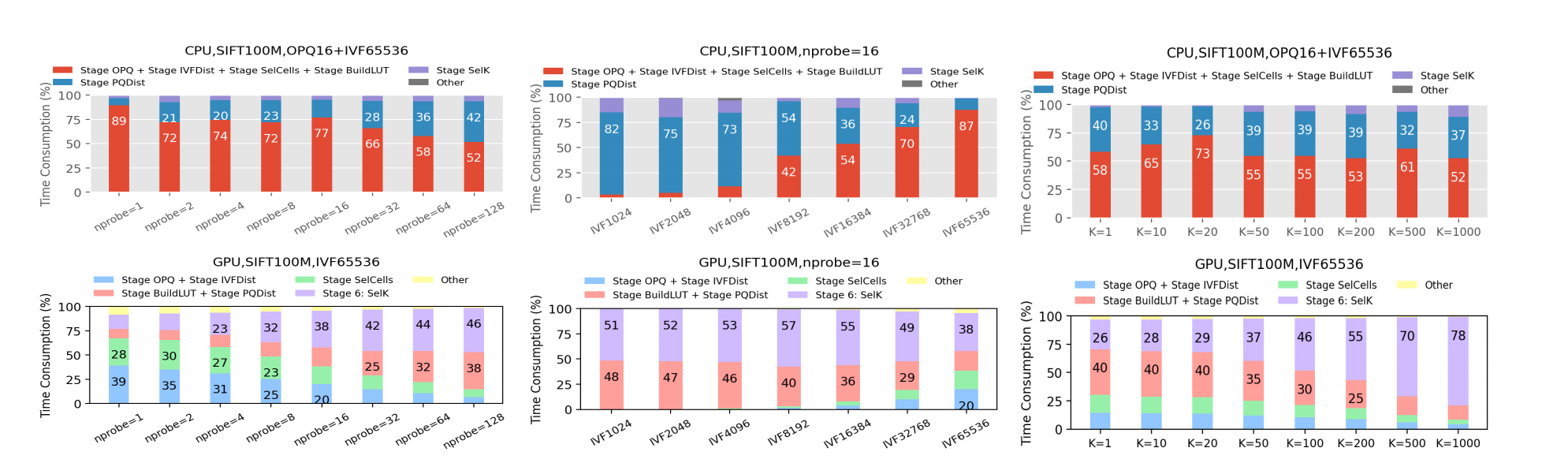
将IVF-PQ划分为若干阶段,查看各参数对各阶段时间消耗的影响:
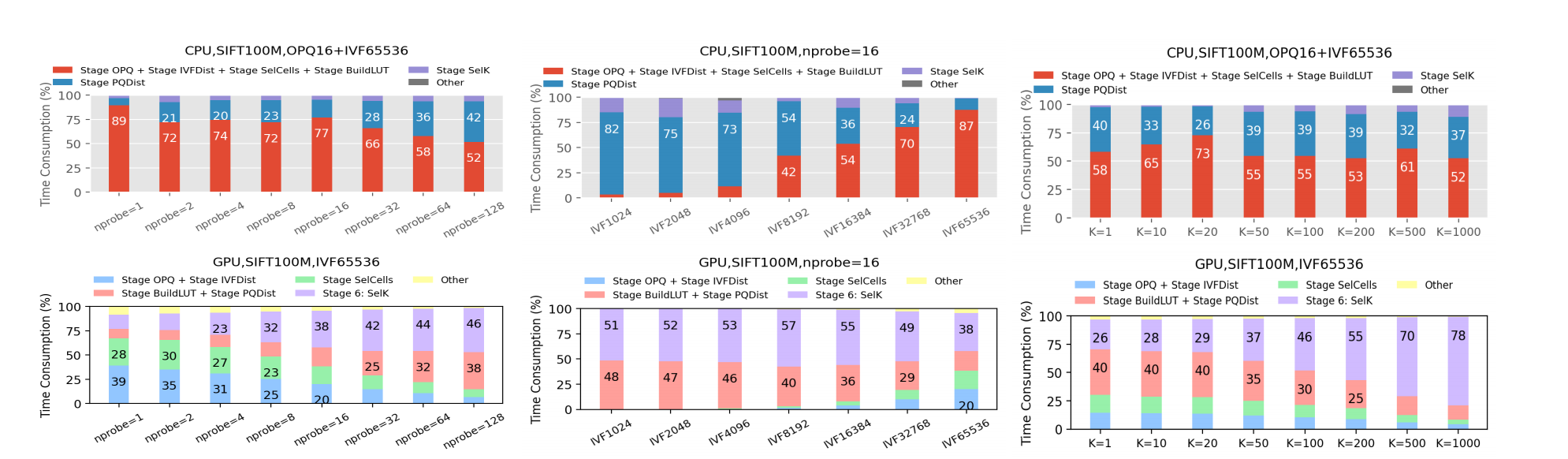
- nprobe:PQDist和SelK花费时间增加。
- nlist:当nlist增加时,IVFDist时间消耗增加,对CPU更为重要(浮点数运算影响大)
- K:SelK耗时增加,在GPU上明显,在CPU上不明显(CPU主要瓶颈在其他阶段)
3.2 Hardware Design Space
第一个选择为每个查询阶段的微架构,如选择前K个对应硬件有多个不同的实现方案
第二个选择为芯片位置的分配,增加一阶段处理单元就会减少另一单元的个数。
第三个选择索引缓存,将其放置在芯片之外的DRAM或者还是芯片之上的SRAM。
3.3 How Does One Choice Influence Others?
算法参数会影响最佳的硬件设计,反之亦然。举例如下:
- 增加nlists会提升IVFDist消耗,为其加入更多的处理单元,减少其他阶段处理单元。同时nlist增大不适合缓存索引,而小规模的索引是适合集成在芯片上的
- 不同的硬件对应不同的参数。
4 FANNS FRAMEWORK OVERVIEW
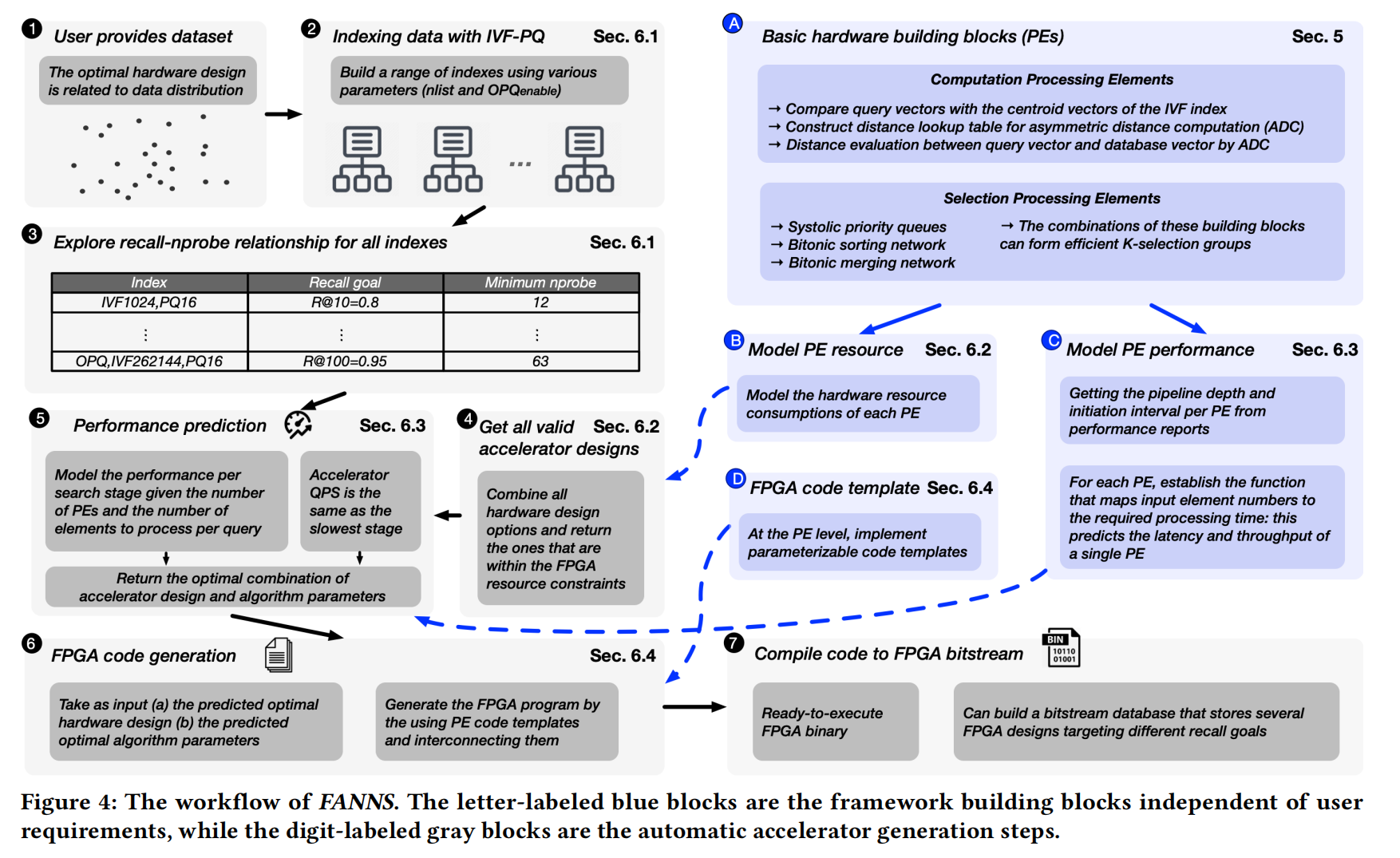
Framework building blocks
A. 为六个阶段构建处理元素(计算单元、选择单元等,如图所示)
B. 评估每个单元的硬件资源消耗
C. 评估每个PE的延迟和吞吐量(构建输入元素与处理时间的函数)
D. 得到PE code template
Automatic accelerator generation workflow
- 输入数据集和召回率目标
- 得到一系列nlist和OPQ参数,对应一个index
- 根据每个index,FANNS得到nprobe和recall之间的关系
- 根据约束得到所有合适的硬件设计选择
- FANNS根据性能评测模型得到最佳组合,模型的输入为所有可能的加速器设计和参数每个index与其对应最小的nprobe
- FPGA代码生成
- FPGA字节流生成

上面是每个阶段的耗时
Example FPGA Design
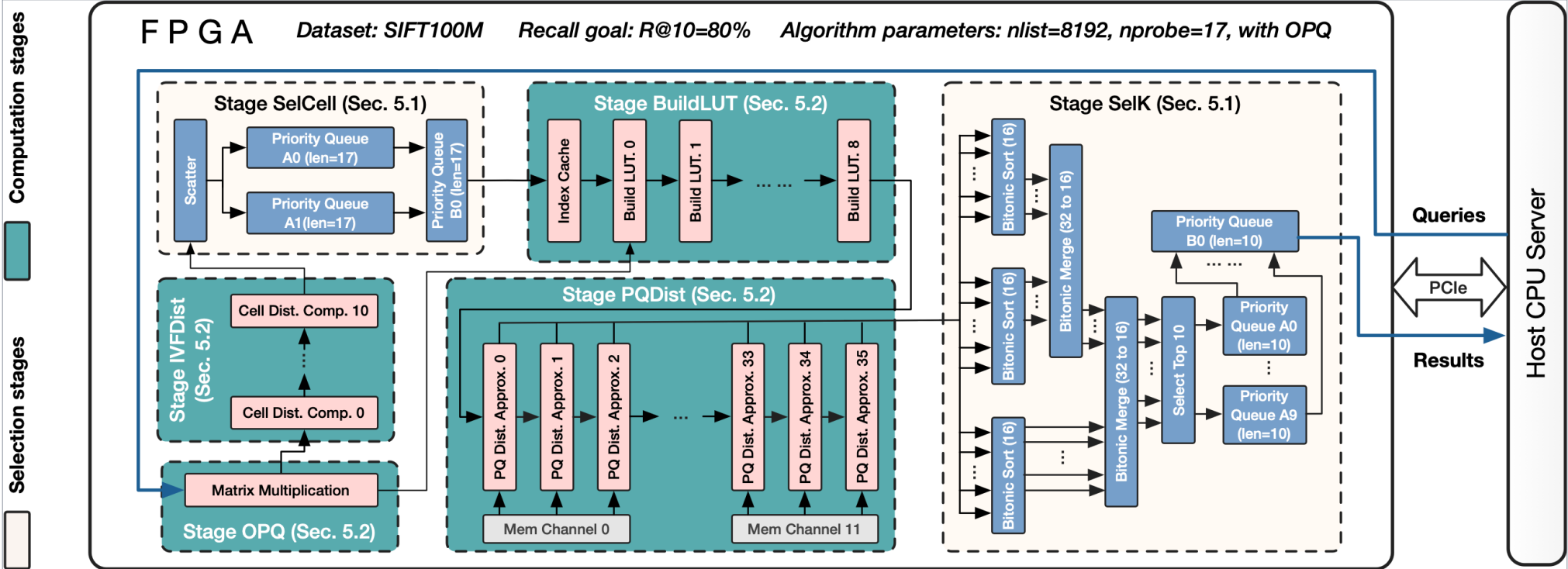
上面是设计的示例。
每个阶段由多个PE来处理,PE之间通过FIFO连接。
PE可以是多层,并且分布不规律的。
5.Hardware Processing Elements
主要分为两块:选择模块和计算模块
5.1 Designs for the Selection Stages
K-Selection Primitives
这一部分主要通过双端排序和收缩优先队列实现。
双端排序(Bitonit Sorts):
一系列输入,通过并行排序的方法实现。
收缩优先队列(Systolic Priority Queue):
队列只需要实现替换replace操作。
通过不断的比较和交换可以将最小的元素交换到最左边。
如下图所示:
K-Selection Microarchitecture Design
假设输入流个数为\(z\),选择\(s\)个最小的
根据不同的权衡具有两种选择:
Option 1:层次优先级队列(HPQ)
通过直接设置\(z\)个优先级队列,通过z个优先队列选择最小的s个。
Option 2: 混合排序、合并和优先队列
整体过程如下所示:
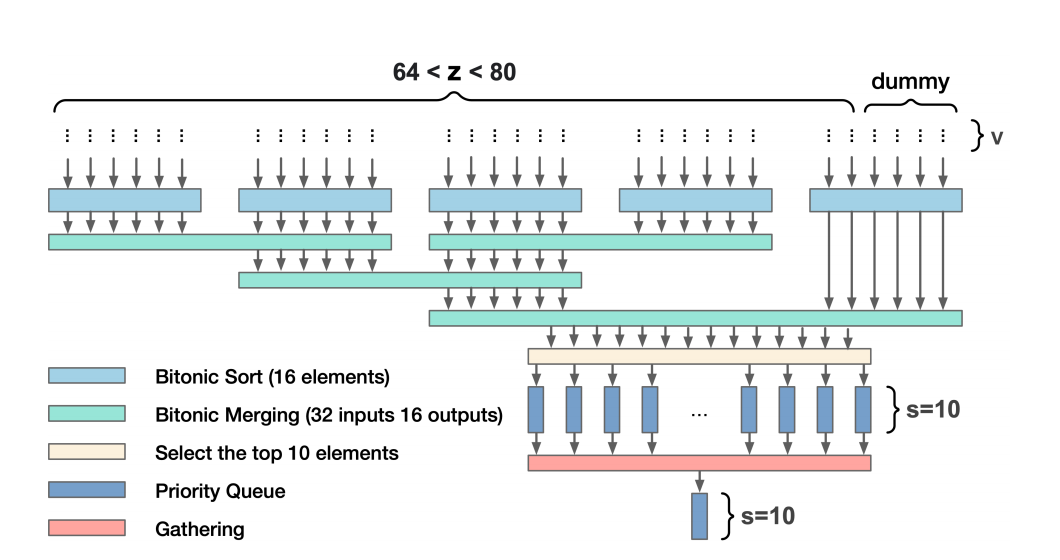
先通过双调排序合并的方式从80个里面选出来16个,之后选择合适的10个。
其中,需要注意的是,第一种选择一般用于z比较小的情况。第二种选择一般适合z比较大的情况,不过当z增大的时候排序和合并也会带来更多额外的开销。
5.2 Designs for the Computation Stages
计算过程一般在OPQ,IVFDist,BuildLUT,PQDist等阶段。
Stage PQdist
整体过程如下所示:
PE Design
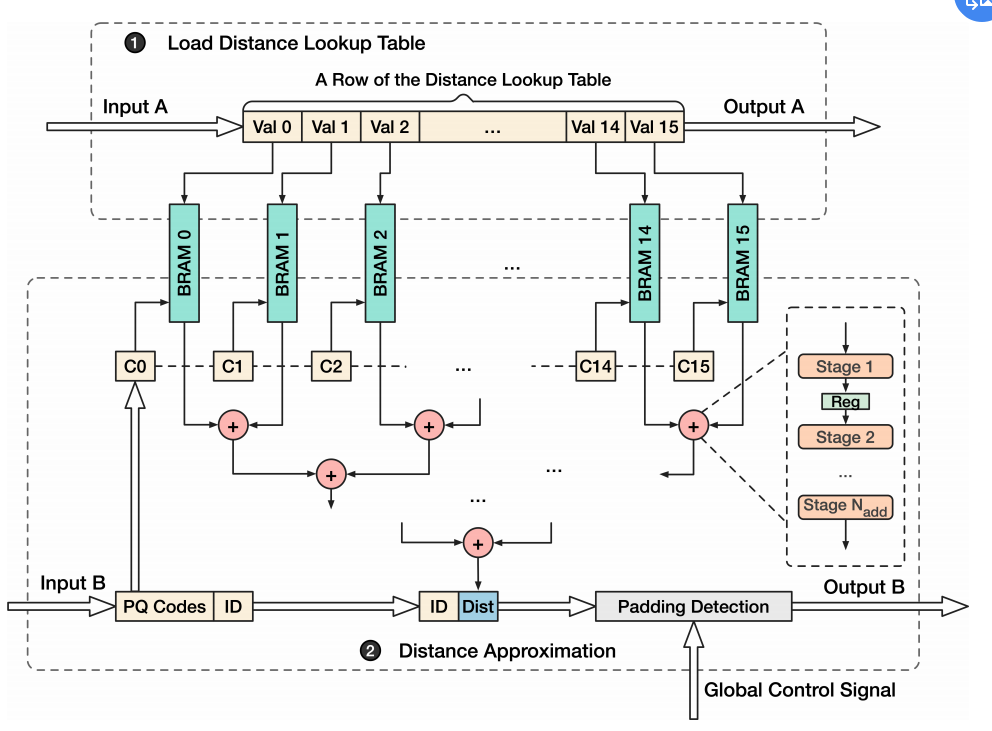
输入为\(BuildLUT\)和\(PQ codes\),一般存储在off-chip中。
第一步,将距离表读入到片上缓存中(BRAM,是快速片上SRAM的一种)。
一个BRAM slice存储表的一列,共m个。
之后,以PQ-code作为索引,得到m个距离,
之后通过m个距离的加法树得到最终的距离,最后将距离填充到对应的位置即可。
PE Size
一般来讲,PE有更多的运算逻辑一般是效率更高的,并且越小的PE,整体的运开销越显著。然而,FPGA编译器很难将如此多的运算逻辑正确的映射到FPGA。
本论文的实验尝试了可以成功的最大的PE。
PE interconnection Topology
采用了一维数组的方式去前向传播运算。不断的运算,并且不断的append
并未采用broadcasting/gather topology。一个资源可能连接过多长线。
6 End-To-End Hardware Generation
6.1 Explore Algorithm Parameters
输入数据集和召回率,得到一些nlist,找到对应的nprobe
6.2 List Valid Accelerator Designs
返回符合资源消耗约束的所有的有效的选择。
计算公式如下:
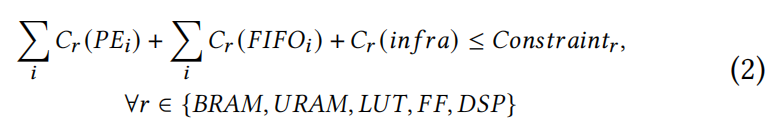
主要分为三部分。
可以用使用各个单元的资源消耗量乘以个数来近似。
6.3 Model Acclerator Performance
直接计算QPS并不现实。
- 评价加速器:取决于瓶颈段
- 评价查找段:取决于workload最重的PE
- 评价PE性能:预测每个PE响应询问的QPS,如下所示:
可以近似:
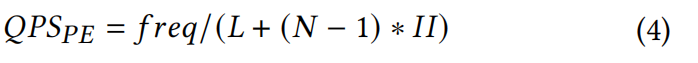
6.4 Generate FPGA Programs
根据输入,调用模板,得到结果。
7. Evaluation
7.1 Experimental Setup
简单介绍了一下CPU,GPU和FPGA以及数据集和其他参数。
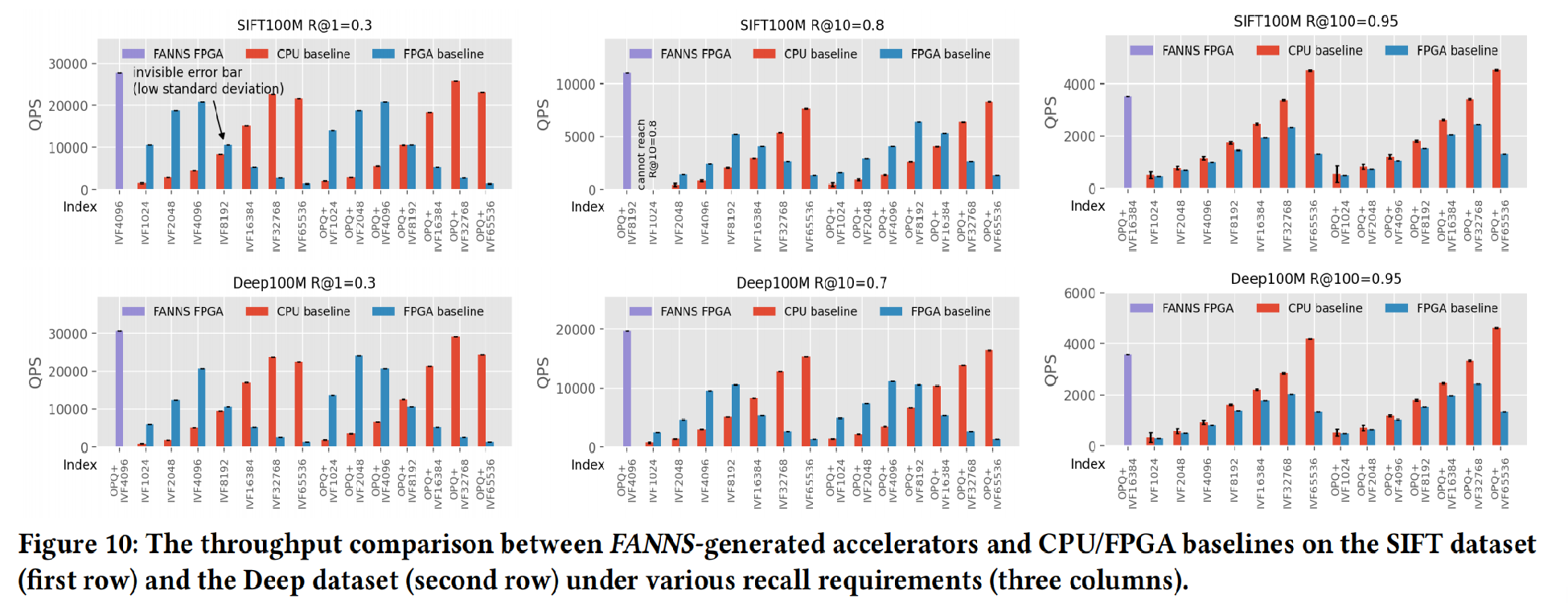
7.2 FANNS-Generated Acceleators

整体对比结果如下:
可以发现,FANNS可以根据不同的召回率选择不同的硬件组成。
同时和baseline设计进行对比
7.3 Performance Comparsion
Offline Batch Processing
-
为最大化性能定制化FPGA是重要的
-
FPGA的表现与K高度相关(优先队列消耗更多的资源)
-
无论何种硬件平台,参数的选择都是至关重要的
Online Query Processing and Scalability
由于实例化TCP/IP堆栈,实现可扩展性
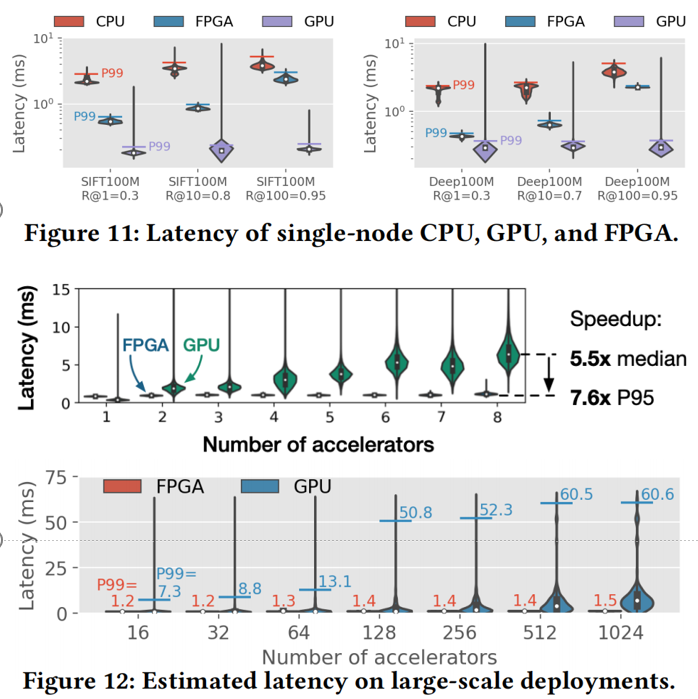
-
单个加速器:FPGA比CPU快很多,但是GPU仍然以其更快的浮点处理速度和位宽占据优势
-
8个FPGA相较于GPU更快(同负载),GPU具有更长的延迟。FPGA相较于GPU具有更好的扩展性
-
随着加速器个数的提升,FPGA相较于会表现出更快的速度
本文来自博客园,作者:zjz2333,转载请注明原文链接:https://www.cnblogs.com/zjz2333/p/17705941.html
