ANN(大规模向量检索方法)
向量检索
这篇文章主要介绍一些向量检索的常用方法
向量检索主要分为两种情况,分别为NN和ANN
首先是最近邻NN,时间复杂度为\(O(ND)\)
其中N为向量的个数,D为向量的维度,运算速度较慢
ANN通过牺牲一部分的内存和内存占用等,换来更快的检索速度(不一定是最近似的,比较近似的即可)
NN和ANN可应用在CV向量检索等多个方面
根据向量个数的规模,解决办法小结如下所示:
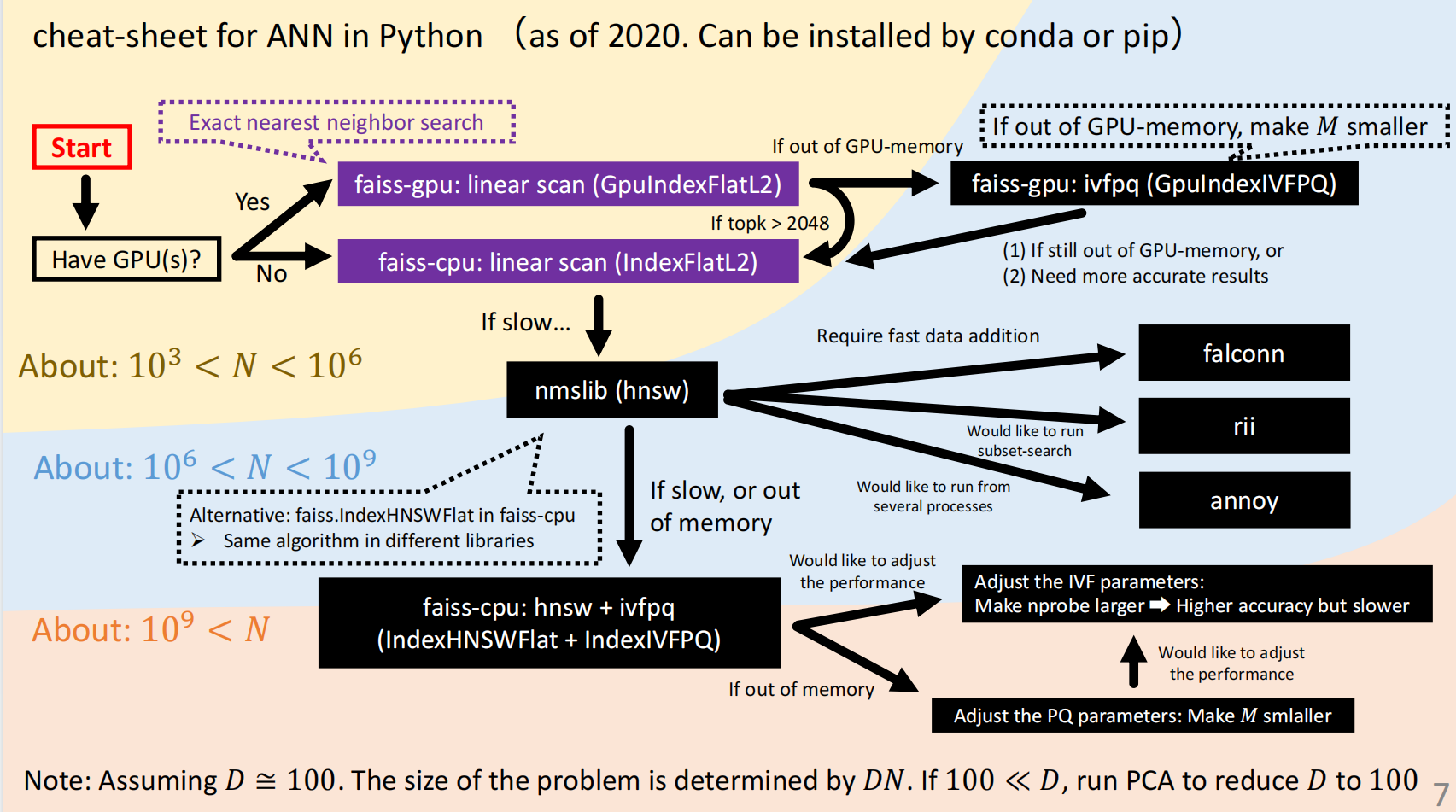
注意向量的维度限制
接下来介绍向量检索的两种思路
Part 1: Nearest Neighbor Search
介绍一下需要解决的问题和基本思路:

faiss为facebook为了向量检索做的包,不同规模问题用不同方法去解决,并充分发挥了GPU等方面的优势
当\({M<20}\)的时候,采用SIMD(单指令流多数据流),基本过程如下所示:
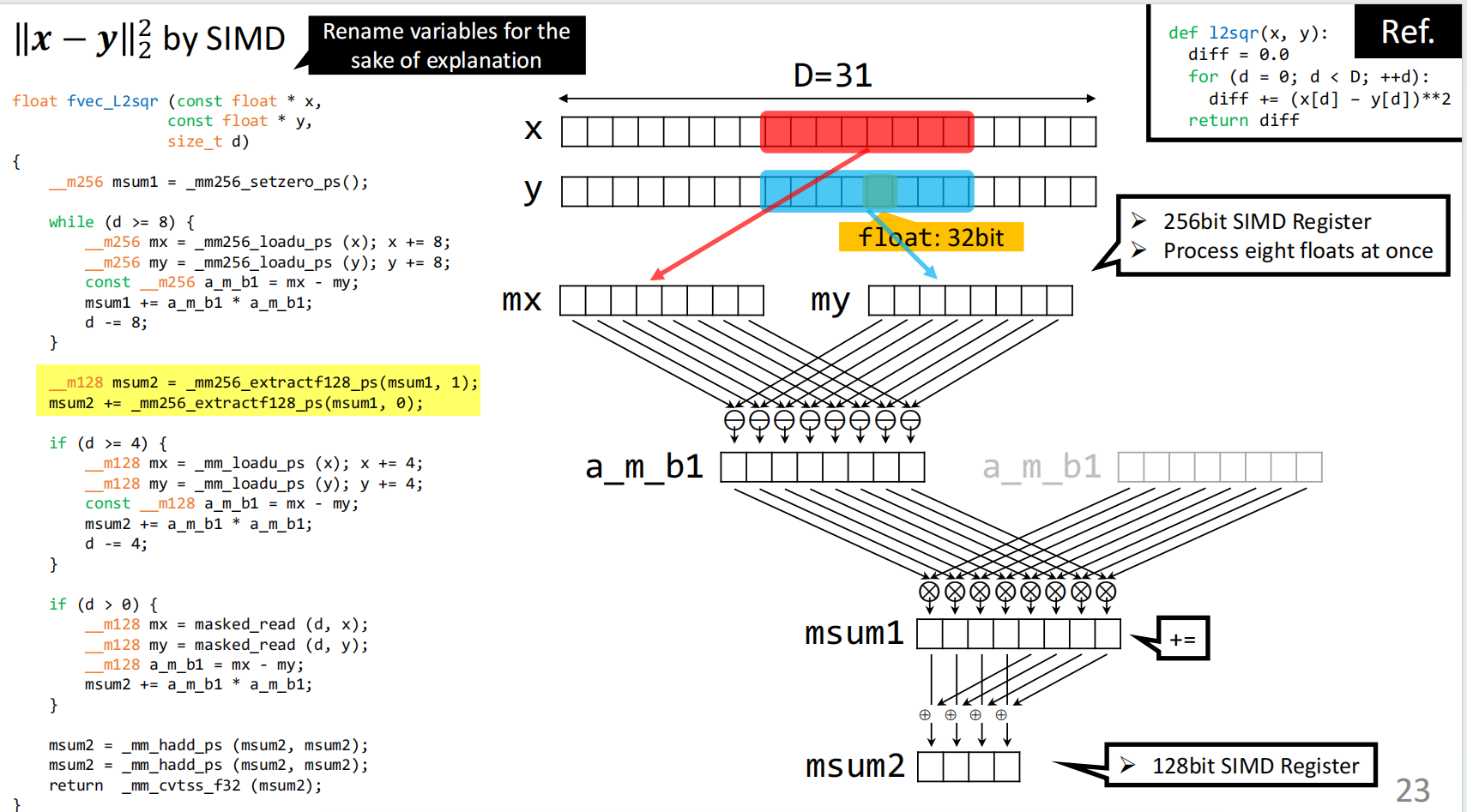
充分提升了并行性,在计算距离的过程中提升了差不多8倍的效率。
当\({M\geq 20}\),采用矩阵乘法的方式,并且将其部署在GPU上加速运算效率
如下图所示:

将该算法部署在GPU上差不多可以提升10倍。
Part 2: Approximate Nearest Neighbor Search
2.1 向量检索基本方法
整体思路如下所示:
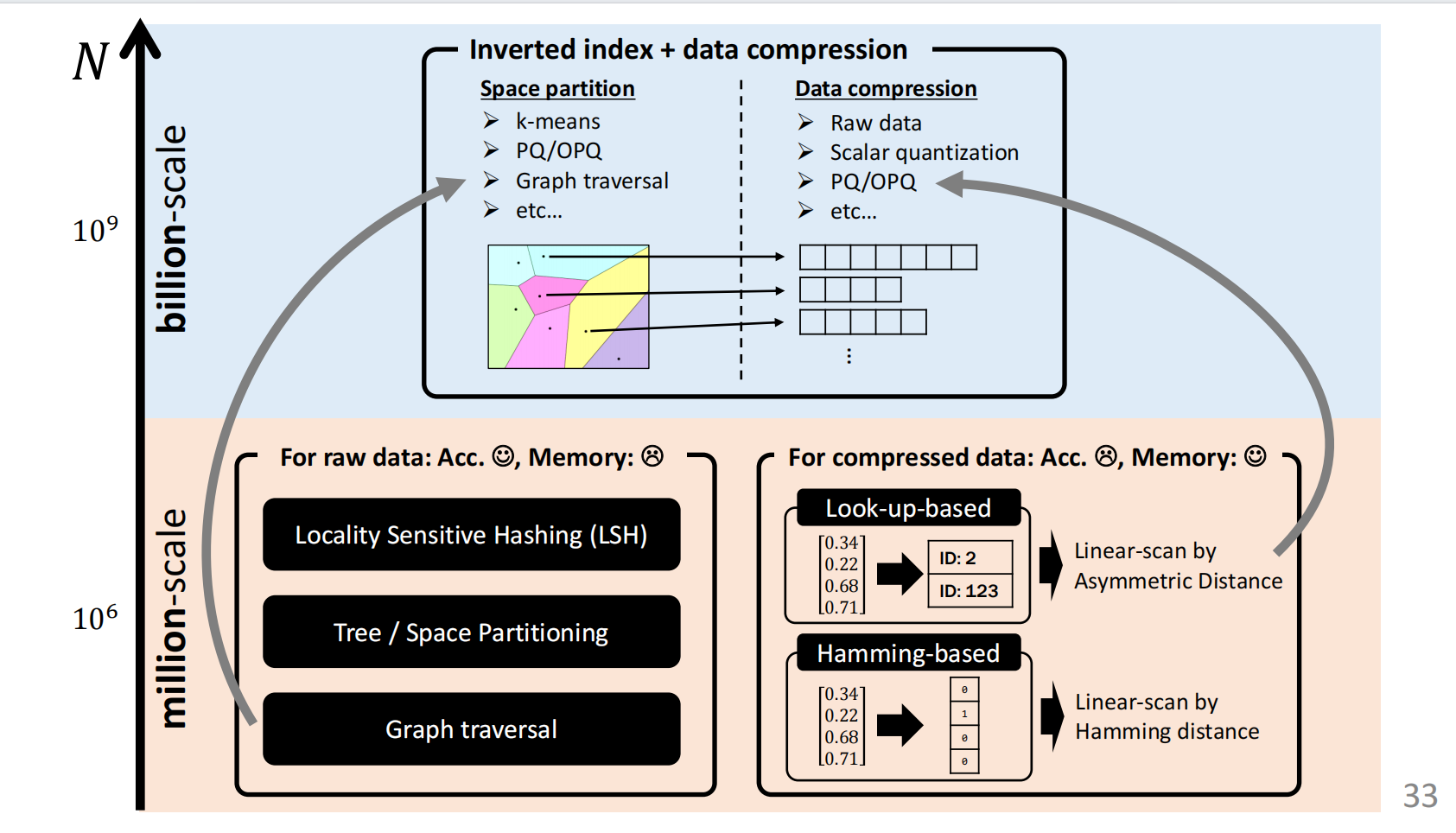
主要划分为millon和billon两个数量级,整体思路也分为空间分割识别和数据压缩两种思路。
哈希的基本思路,也比较简单,如下所示:
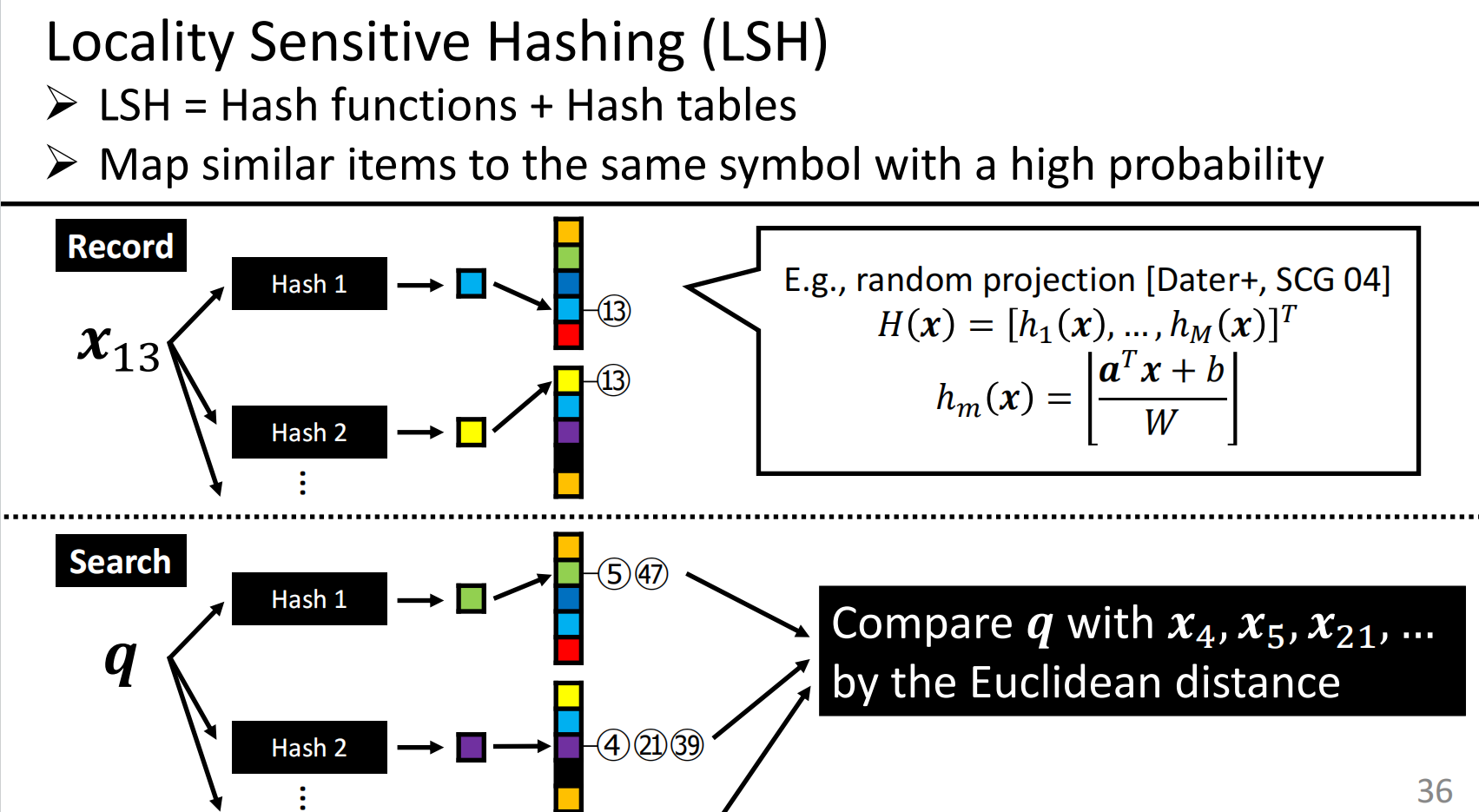
原始数据的存储也需要额外的内存,也需要一些哈希表来提升精度,
效果并不是很理想。Falconn在此基础上提出了改进,在此不再赘述。
FLANN(Fast Library for ANN)
基于KD树的思想,检索速度快,但是原始数据的存储占用内存大。
Annoy和KD树类似,但是通过随机取点划分空间再检索,需要的参数很少
但是也是需要大规模的内存消耗,速度也比NSW和HNSW更慢。
接下来介绍重量级的方法
Graph traversal最近更为常用的方法,在真实数据百万级别的上效果很好。
首先,通过不断输入节点建立图与图之间的边,基本结构如下所示:
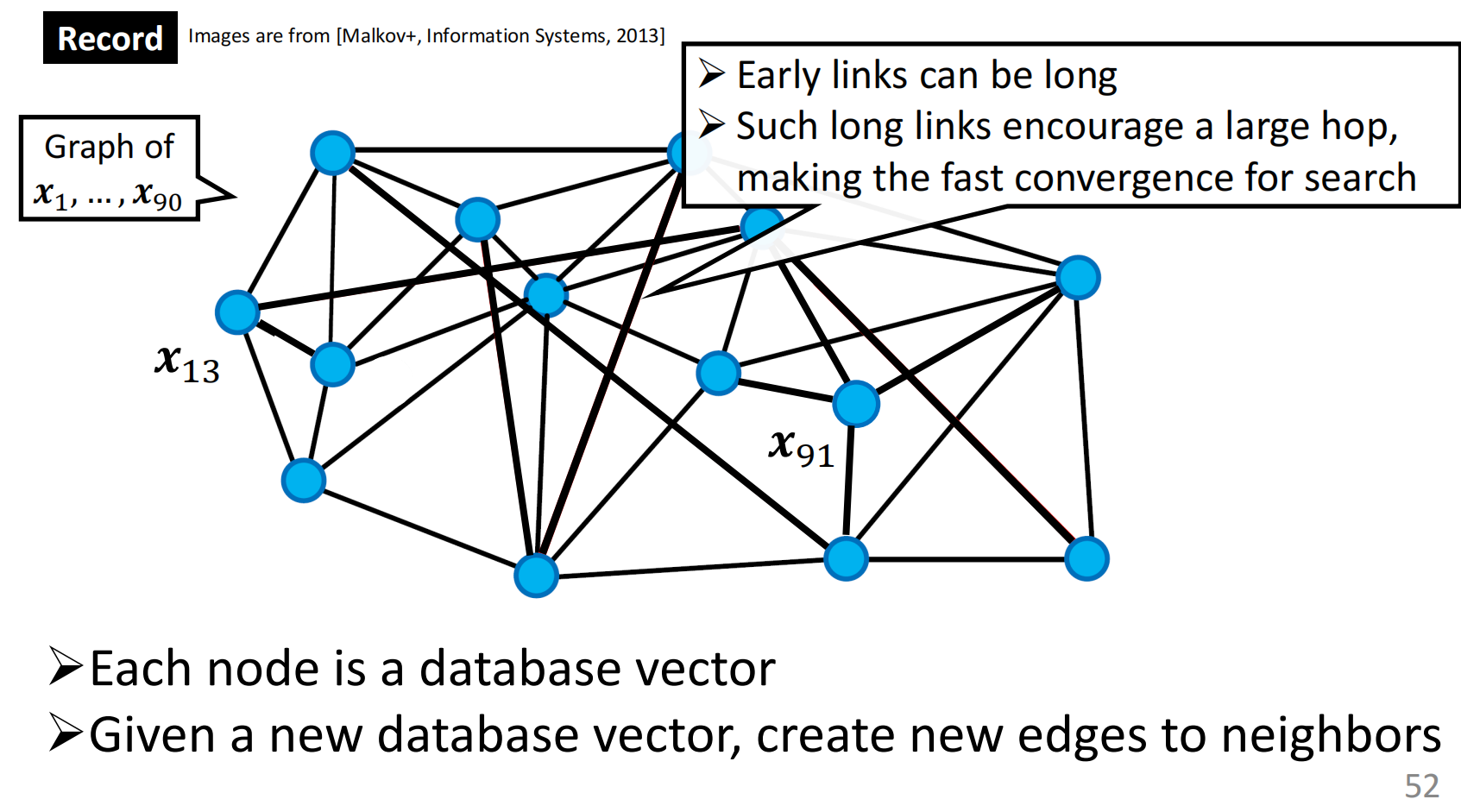
最开始节点之间的边更长,以期支持更为快速的收敛。
同时给定一个询问节点,通过随机游走的贪心的方法,找到最近的节点。
上面就是NSW(Navigable Small World Graphs)的方法。
同时,可以将NSW应用在分层图上,即为HNSW方法
(NMSLIB,Hnswlib,Faiss)均应用了这种方法。
2.2 向量压缩基本方法
将较长的向量压缩为short-code。
压缩后向量距离计算快,并且也可以相近的反映原始向量的距离,就是较好的压缩方法。
先介绍一下最为简单的向量压缩方法,海明码
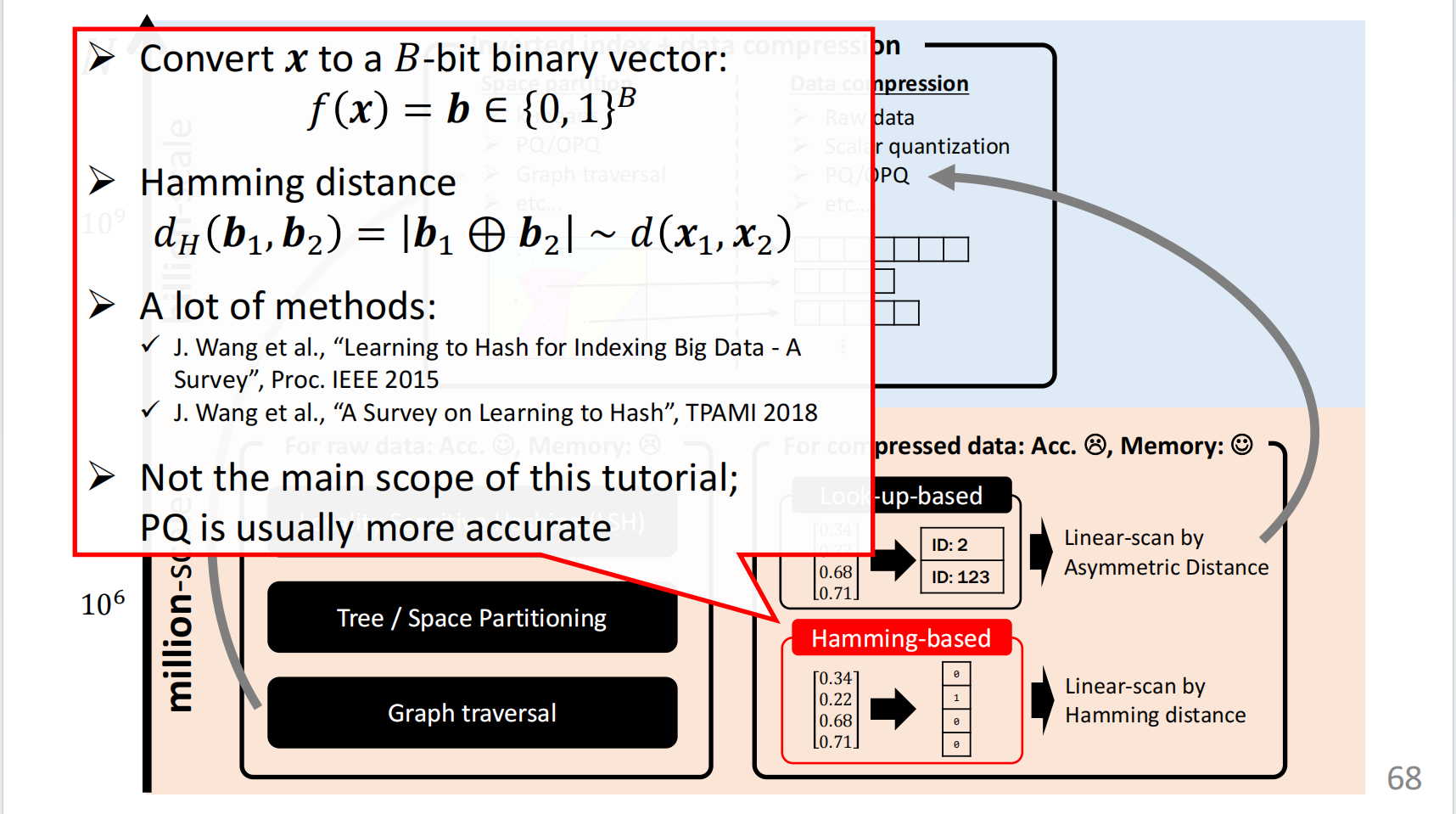
可将原始向量转化为独热编码,通过异或计算向量间的距离。
接下来的一种方法为PQ法。
通过把向量划分为不同层次的sub-vector,在不同层次上使用k-means聚类,
利用聚类中心去代替原始向量。
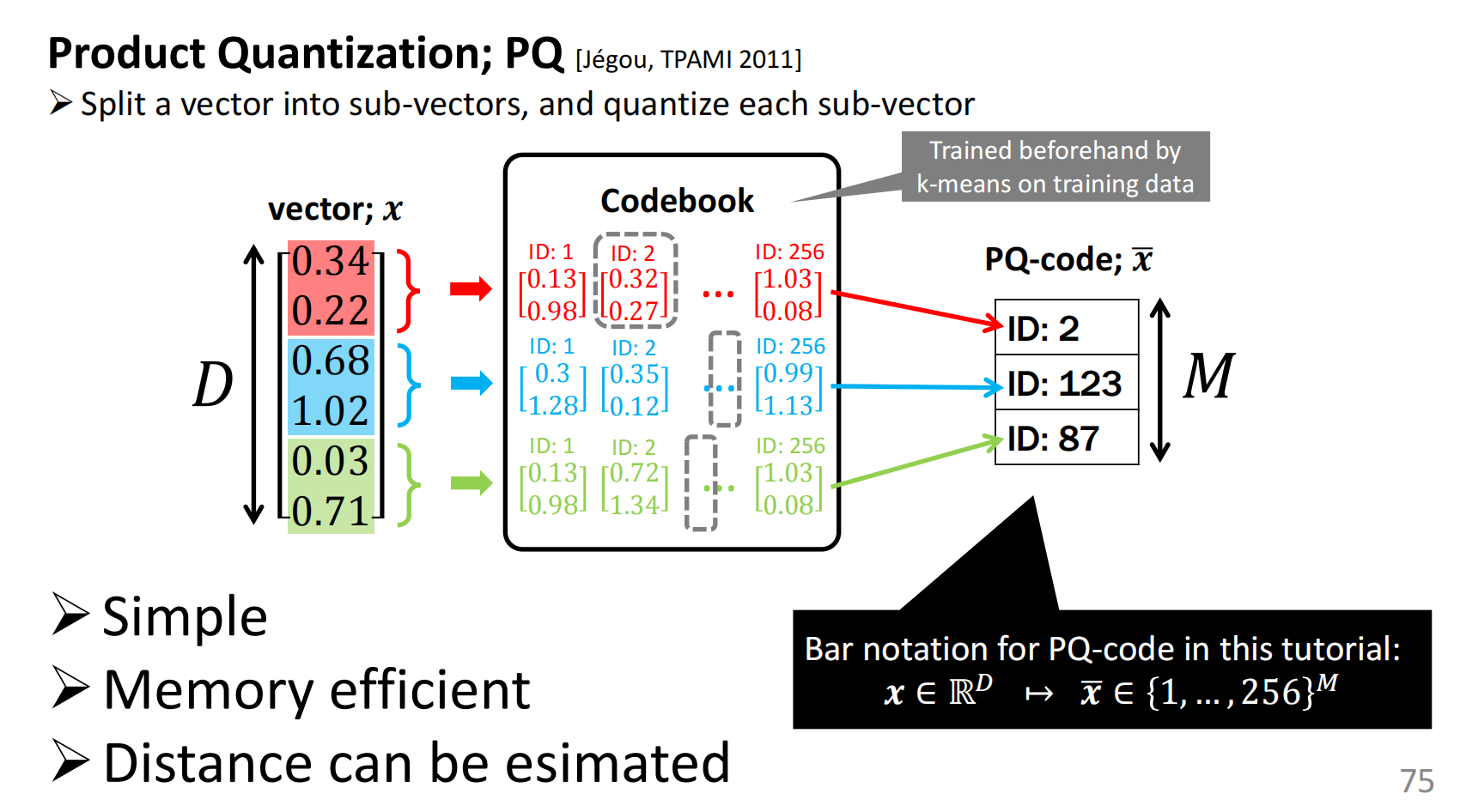
这样可以较大幅度的压缩向量本身所占据的内存空间。
之后,可以通过线性扫描和查表的方法计算向量之间的距离,整体的过程如下所示:

Deep PQ,是PQ算法的改进,通过引入CNN和loss损失函数实现分类。
海明码和PQ的对比结果如下:
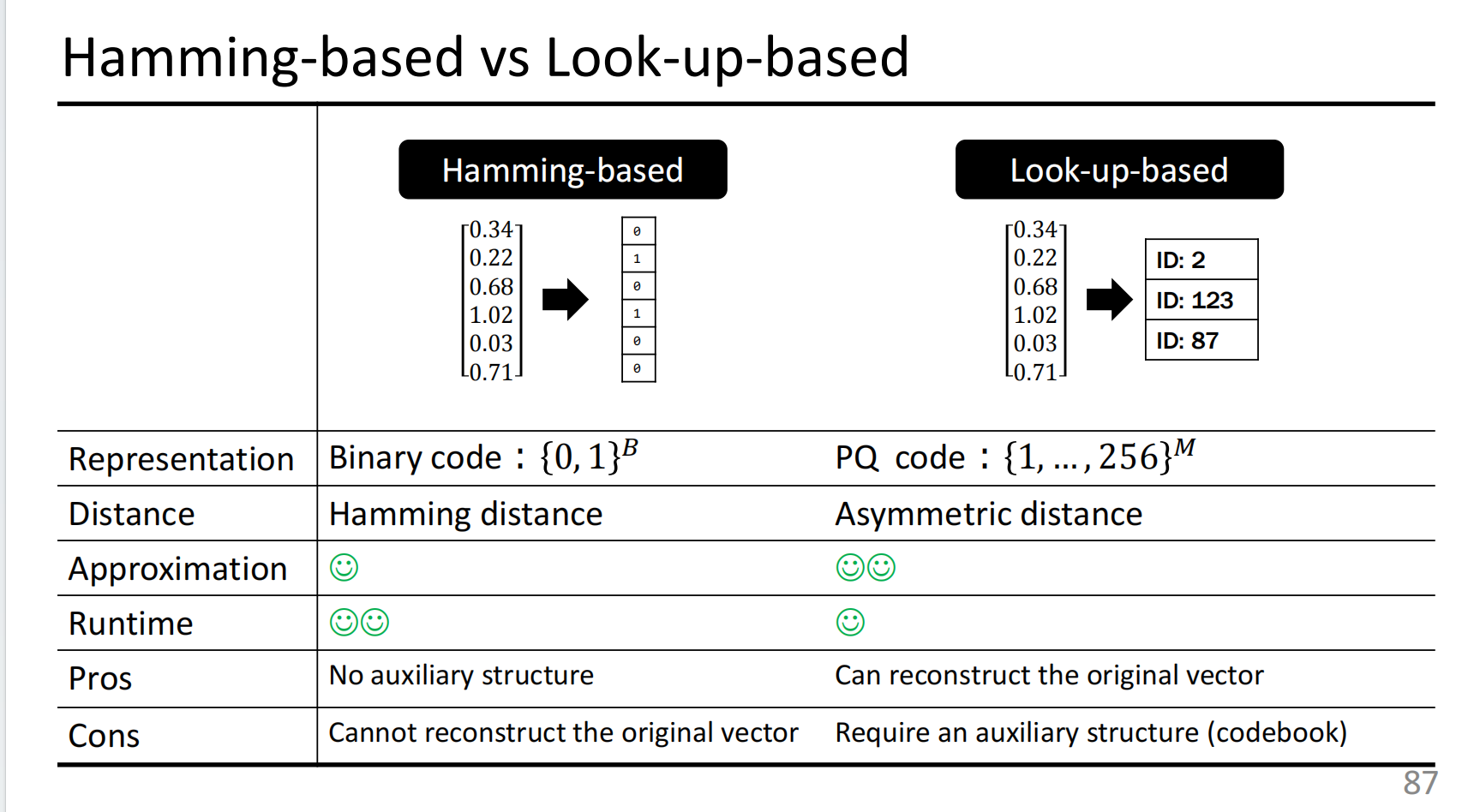
容易发现海明码计算速度快,但是难以重构原始向量,
PQ计算速度更慢一些,但是更好的保存了原始的数据。
如何应用到上亿级别的数据呢?
首先通过聚类的方法,将空间分割为不同的部分。
之后通过将每个点和距离其最近的残差标准化为PQ编码,记录ID+PQ(res)
整体构造的做法如下所示:
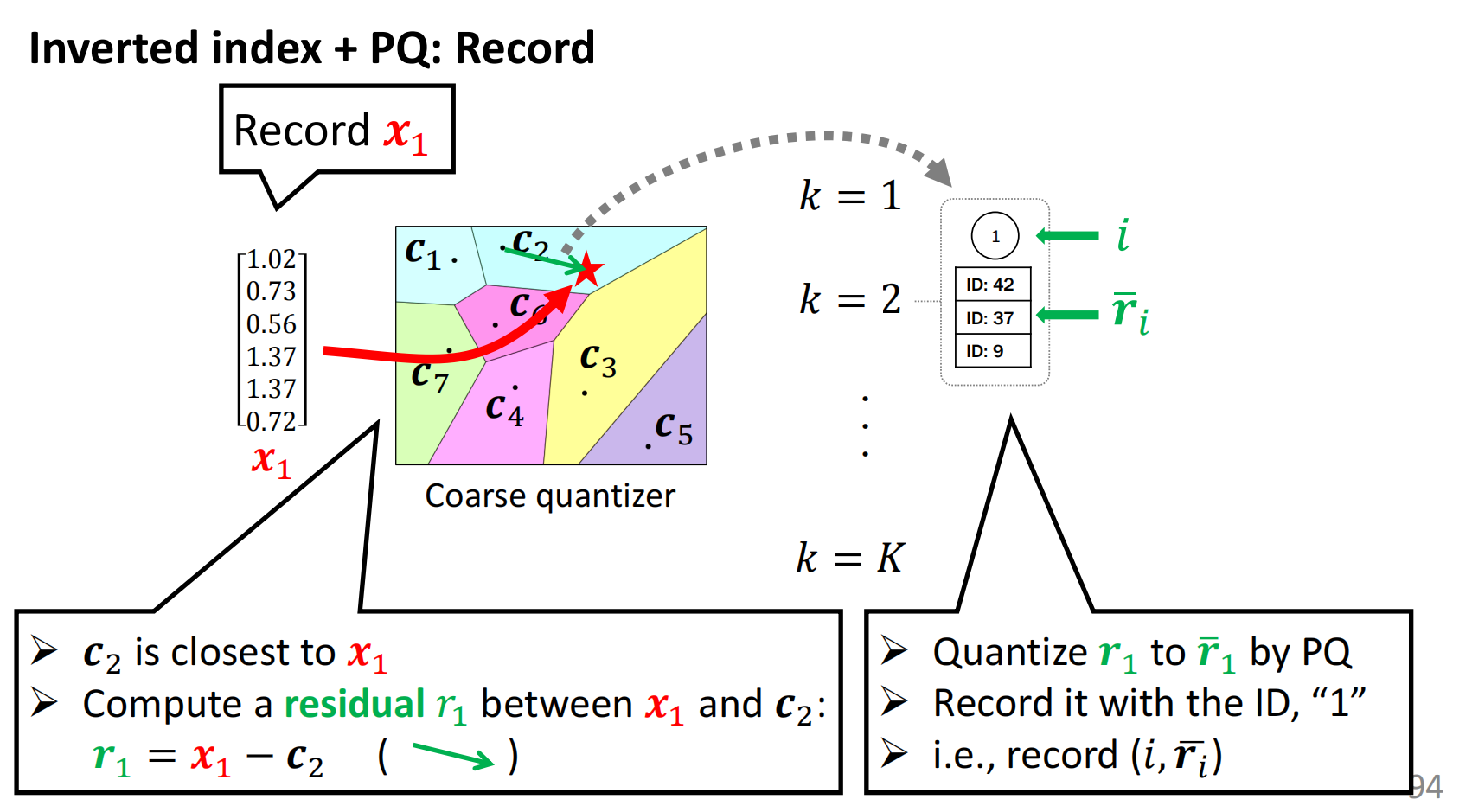
最后查找的时候,就在对应的区域里面找最近的\(r_i\)即可(还是应用了上述PQ法,不过对象换为了\(r_i\))
之后,PQ编码和HSNW结合,可以用在向量检索上面。
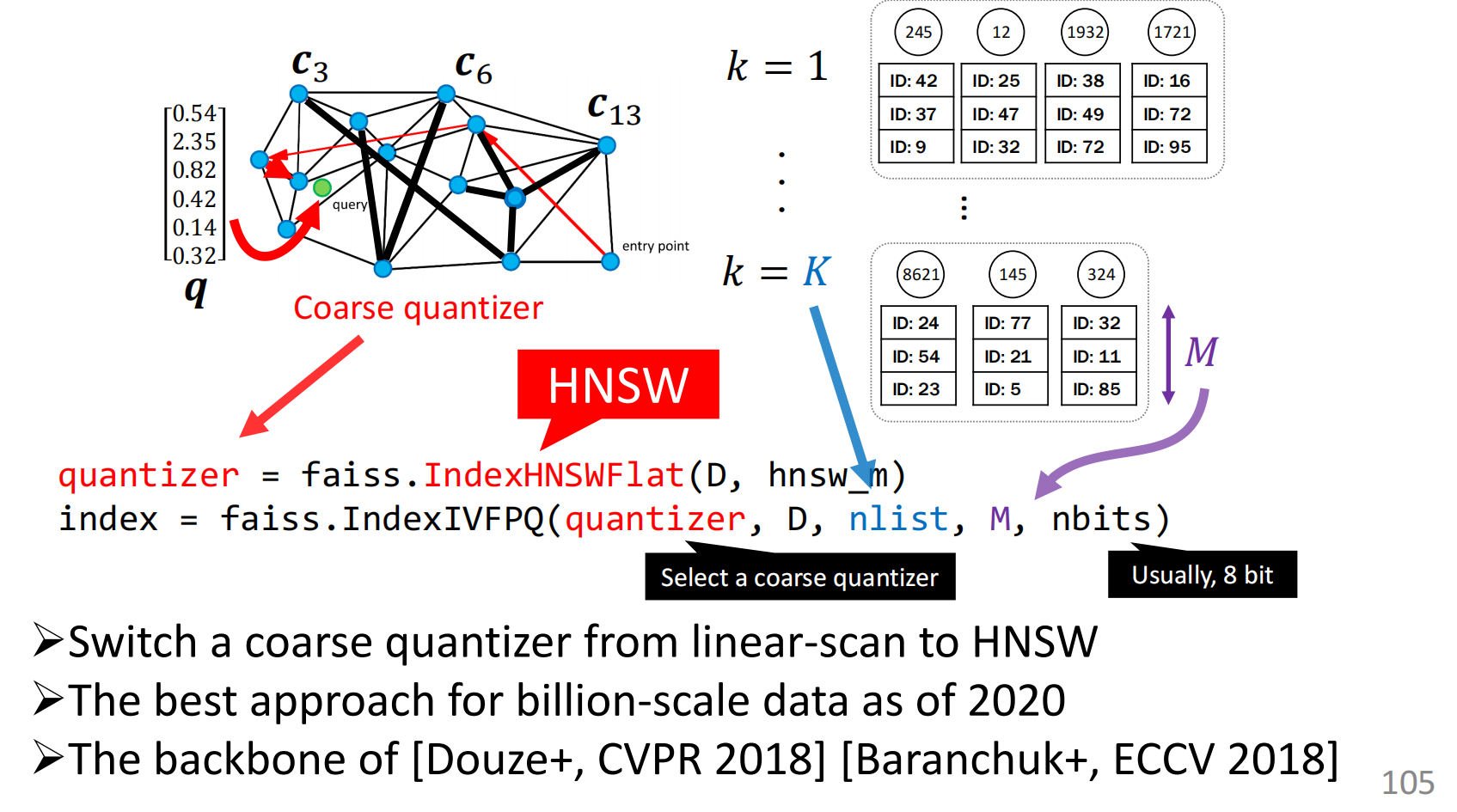
上面的方法(还是说)非常适合于上亿级别的向量检索。
当然,ANN目前也存在一定的问题,比如:
没有数学背景、可解释性差、数据集少等问题,仍待改善。
小结一下
本篇文章除了向量检索最基本的方法,
小规模的SIMD,矩阵乘,以及很早之前的哈希,KD树等方法。
重点讲了向量压缩的方法(PQ和海明码)以及优缺点的对比,
同时,也介绍了HNSW方法求解最近向量,都比较简易,但也很实用。
同时通过Inverted index + PQ改进等方法实现向量检索在上亿级别数据上的应用。
本文来自博客园,作者:zjz2333,转载请注明原文链接:https://www.cnblogs.com/zjz2333/p/17698068.html
