redis集群-Cluser
目录
一 Redis Cluser介绍背景
https://www.cnblogs.com/liuqingzheng/articles/17324393.html
1.1问题
# 存在问题
1 并发量:单机redis qps为10w/s,但是我们可能需要百万级别的并发量
2 数据量:机器内存16g--256g,如果存500g数据呢?
1.2 解决
# 集群解决上述问题
# 解决:加机器,分布式
redis cluster 在2015年的 3.0 版本加入了,满足分布式的需求
二 数据分布(分布式数据库)
2.1 存在问题
假设全量的数据非常大,500g,单机已经无法满足,我们需要进行分区,分到若干个子集中
2.2 分区方式
| 分布方式 | 特点 | 产品 |
|---|---|---|
| 哈希分布 | 数据分散度高,建值分布于业务无关,无法顺序访问,支持批量操作 | 一致性哈希memcache,redis cluster,其他缓存产品 |
| 顺序分布 | 数据分散度易倾斜,建值业务相关,可顺序访问,支持批量操作 | BigTable,HBase |
2.2.1 顺序分区
# 原理:100个数据分到3个节点上 1--33第一个节点;34--66第二个节点;67--100第三个节点(很多关系型数据库使用此种方式)
2.2.2 哈希分区
有3终方式:节点取余分区、一致性哈希分区、虚拟槽分区
节点取余分区
# 原理:hash分区: 节点取余 ,假设3台机器, hash(key)%3,落到不同节点上
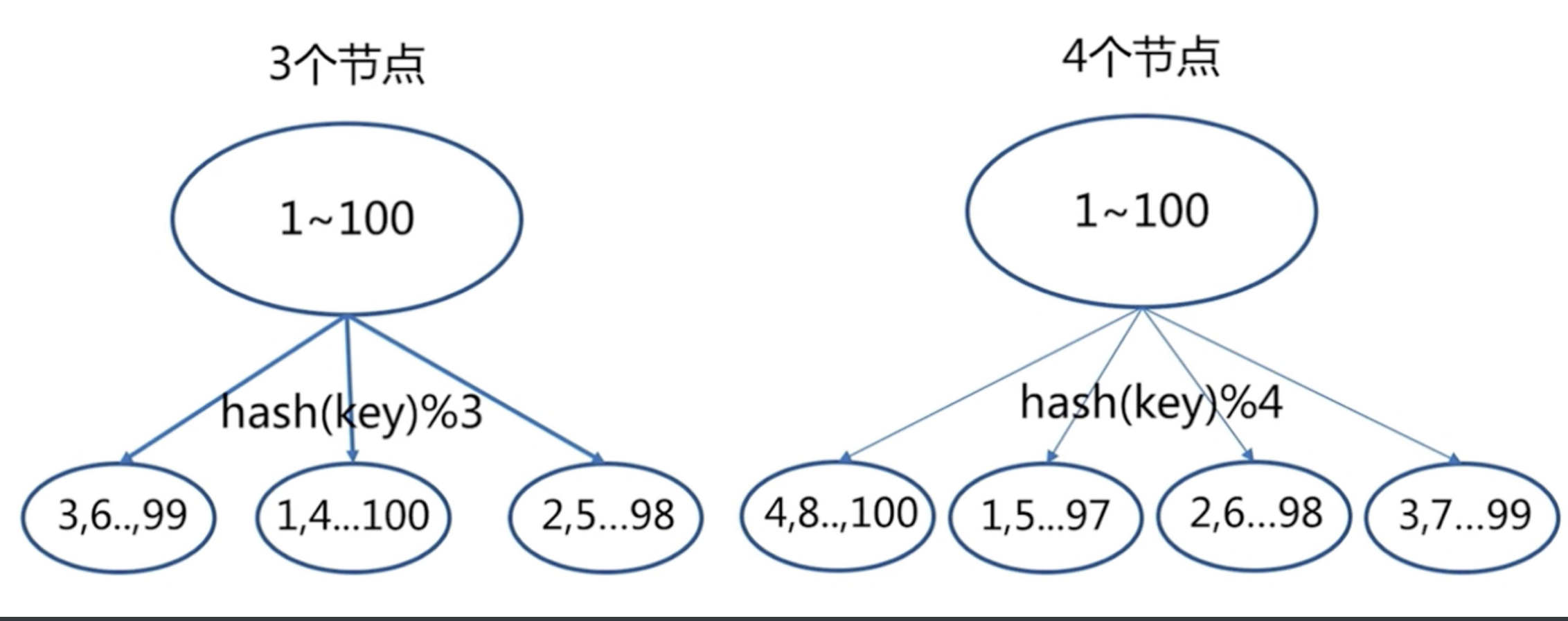
节点扩容,添加一个节点,存在问题,很多数据需要偏移,总偏移量要大于80%

推荐翻倍扩容,由3变成6,数据量迁移为50%,比80%降低
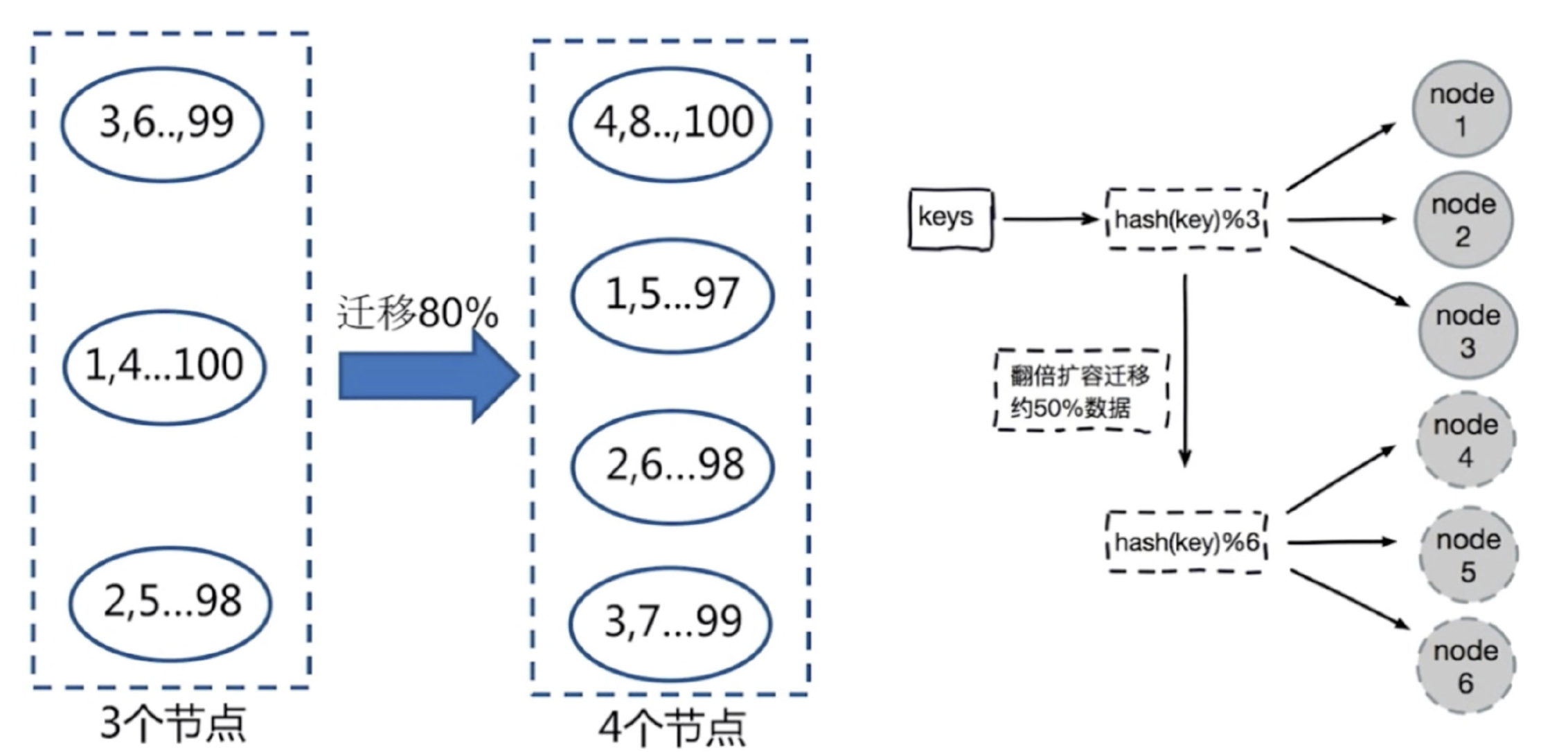
# 总结:
客户端分片,通过hash+取余
节点伸缩,数据节点关系发生变化,导致影响数据迁移过大
迁移数量和添加节点数量有关:建议翻倍扩容
一致性哈希分区
每个节点负责一部分数据,对key进行hash,得到结果在node1和node2之间,就放到node2中,顺时针查找
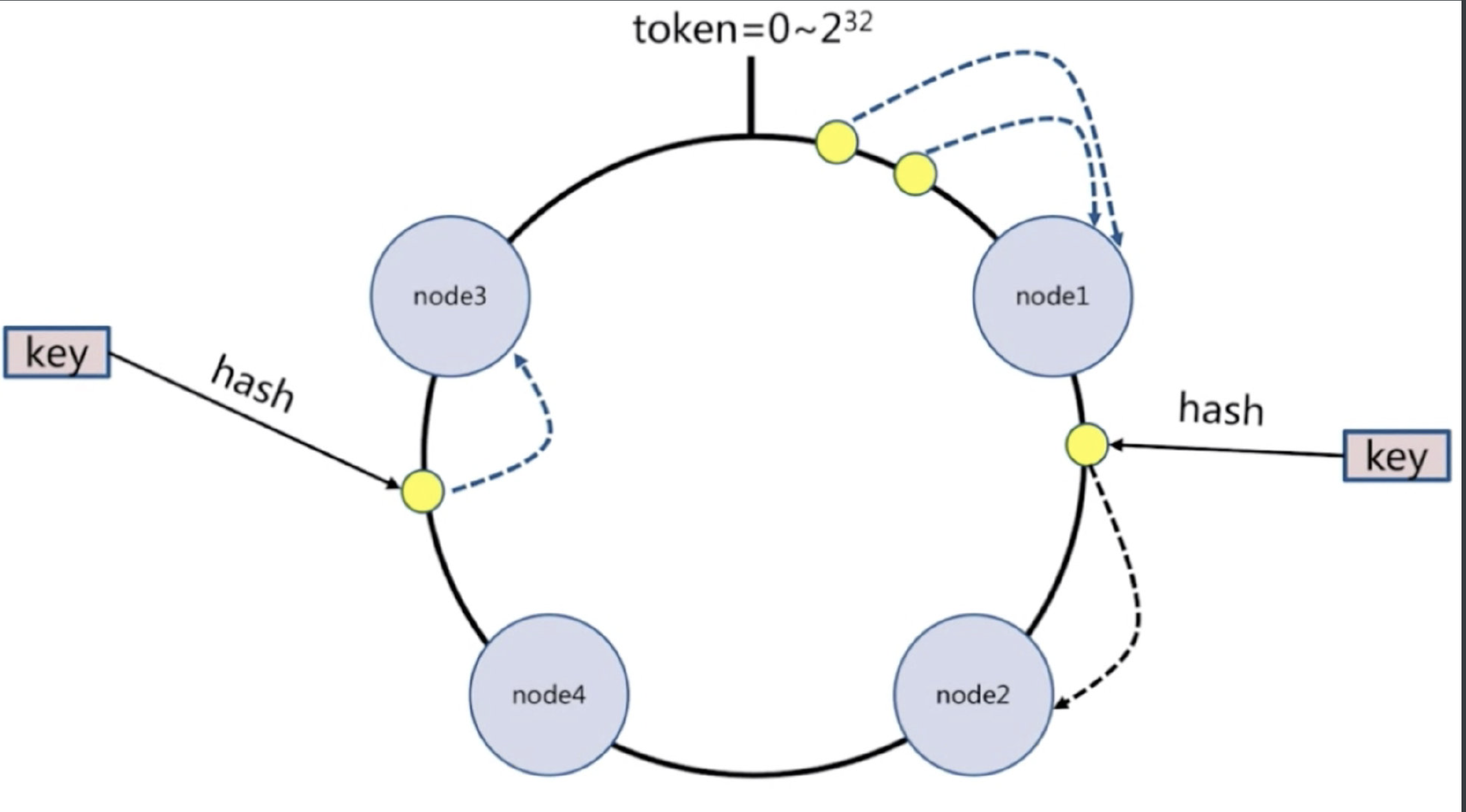
假设添加一个新节点node5,现在只需要迁移一小部分数据,不会影响node3和node4的数据,只会迁移node1和node2的数据
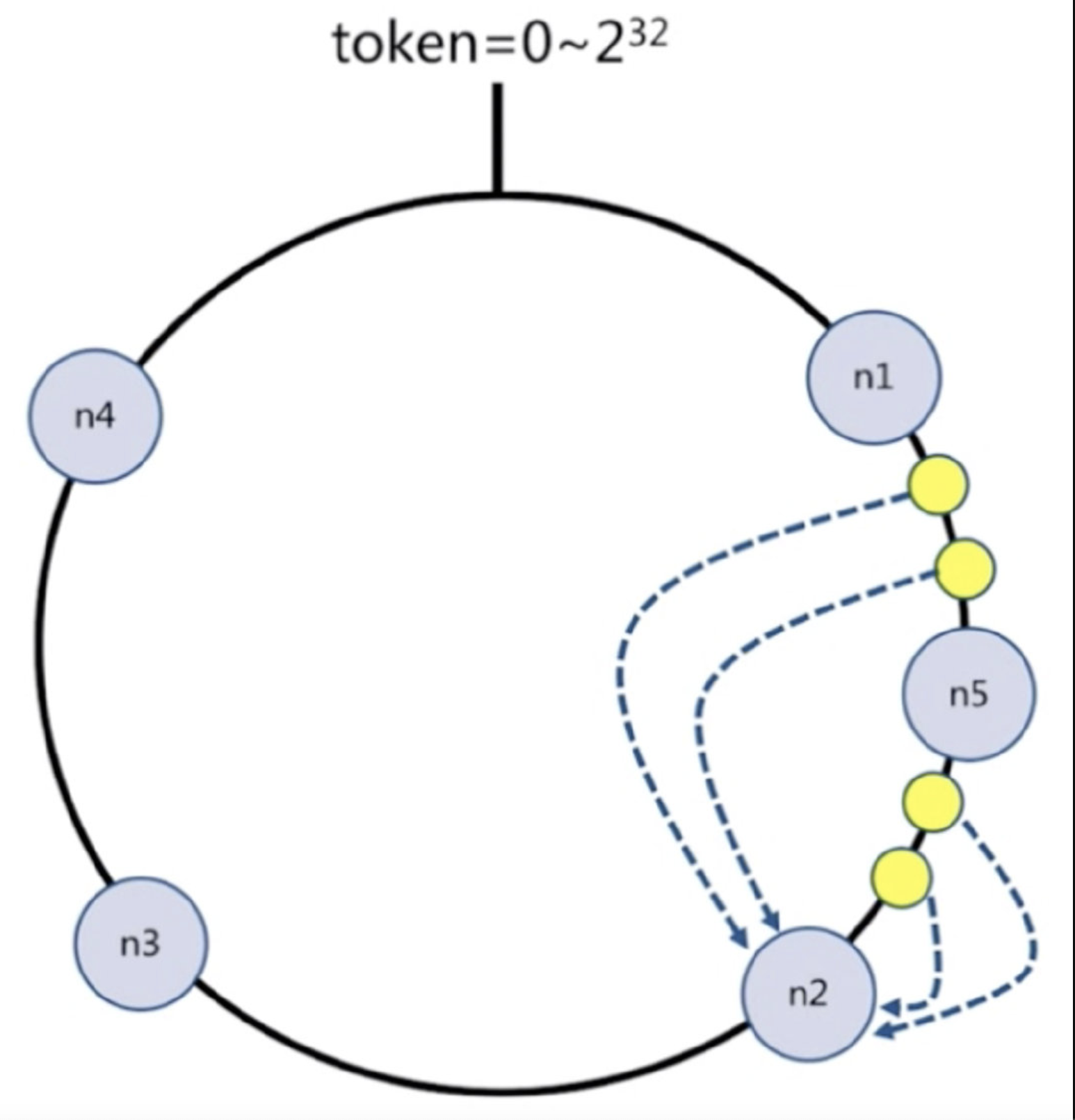
节点比较多的话合适,假设有1000个节点,加一个只要迁移千分之一的数据
#总结:
客户端分片:哈希+顺时针(优化取余)
节点伸缩:只影响临近节点,但是还有数据迁移的情况
伸缩:保证最小迁移数据和无法保证负载均衡(这样总共5个节点,数据就不均匀了),翻倍扩容可以实现负载均衡
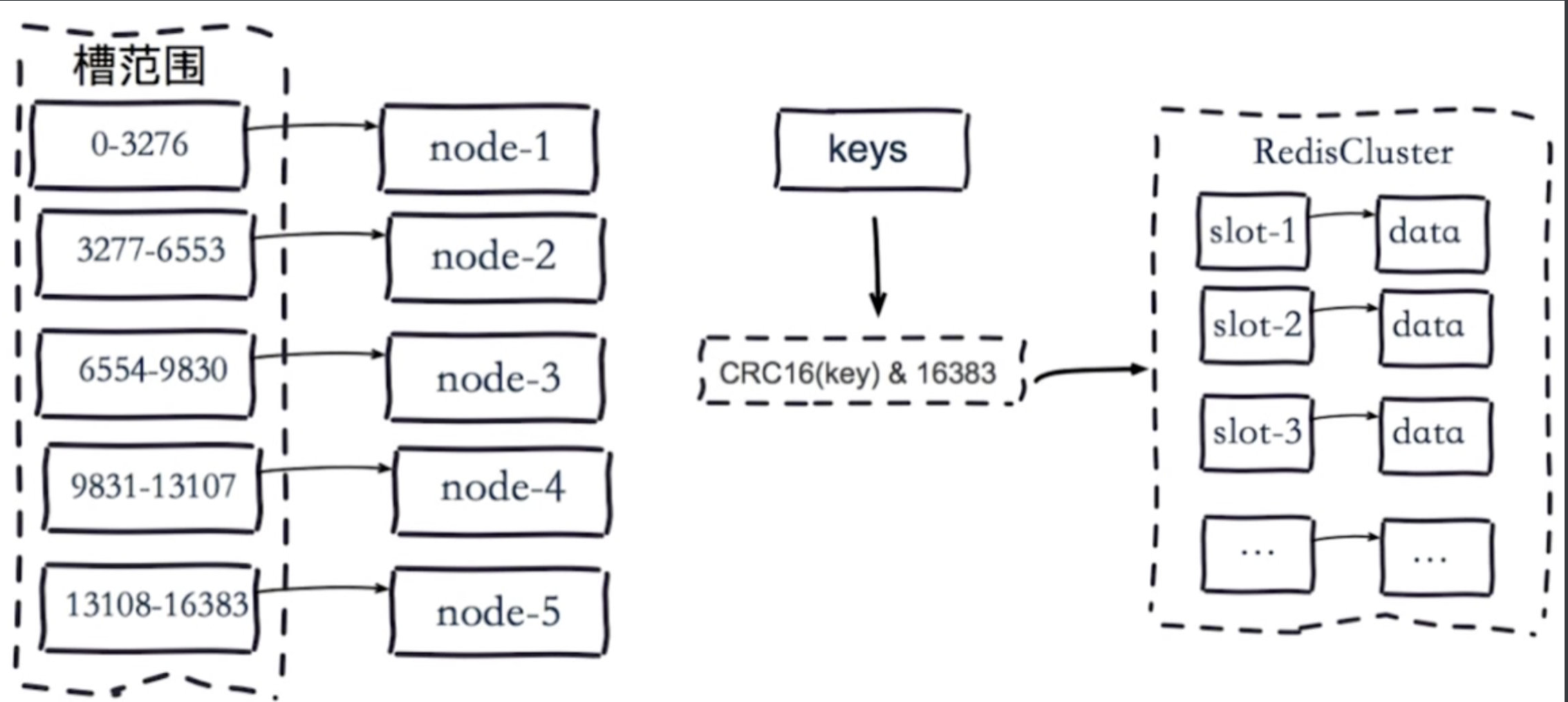
虚拟槽分区
预设虚拟槽:每个槽映射一个数据子集,一般比节点数大
良好的哈希函数:如CRC16
服务端管理节点、槽、数据:如redis cluster(槽的范围0–16383)
5个节点,把16384个槽平均分配到每个节点,客户端会把数据发送给任意一个节点,通过CRC16对key进行哈希对16383进行取余,算出当前key属于哪部分槽,属于哪个节点,每个节点都会记录是不是负责这部分槽,如果是负责的,进行保存,如果槽不在自己范围内,redis cluster是共享消息的模式,它知道哪个节点负责哪些槽,返回结果,让客户端找对应的节点去存
服务端管理节点,槽,关系
三 集群搭建
搭建redis集群 --->6台机器(一主一从:3个节点)--->扩容成:8台机器,4个节点---->再缩容:恢复成6台机器3个节点
# 集群配置
#masterauth 集群搭建时,如果主库设置了密码,需要填写主库的密码
cluster-enabled yes # 开启cluster,丛集,群集
cluster-node-timeout 15000 # 故障转移,超时时间 15s
cluster-config-file nodes-${port}.conf # 自动生成的,cluster节点增加一个自己的配置文件
cluster-require-full-coverage yes # 只要集群中有一个故障了,整个就不对外提供服务了,这个实际不合理,假设有50个节点,一个节点故障了,所有不提供服务了,需要设置成no
# 1 写一个配置文件
vim redis-7000.conf
# 写入
port 7000
daemonize yes
dir "/root/lqz/redis/data/"
logfile "7000.log"
dbfilename "dump-7000.rdb"
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-require-full-coverage yes
# 2 快速造出6个
# 快速生成其他配置
# sed读取文本并进行替换
# sed 's/7000/7001/g' redis-7000.conf > redis-7001.conf 把文本中的7000换成7001,并把新文件命令为7001。
sed 's/7000/7001/g' redis-7000.conf > redis-7001.conf
sed 's/7000/7002/g' redis-7000.conf > redis-7002.conf
sed 's/7000/7003/g' redis-7000.conf > redis-7003.conf
sed 's/7000/7004/g' redis-7000.conf > redis-7004.conf
sed 's/7000/7005/g' redis-7000.conf > redis-7005.conf
# 3 启动起6个节点
./src/redis-server ./redis-7000.conf
./src/redis-server ./redis-7001.conf
./src/redis-server ./redis-7002.conf
./src/redis-server ./redis-7003.conf
./src/redis-server ./redis-7004.conf
./src/redis-server ./redis-7005.conf
ps -ef |grep redis # 查看进程
# 4 查看集群命令(暂时没配好)
cluster nodes
cluster info
# 5 集群不能运行,运行如下命令
./src/redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
#####################命令解释###################
./src/redis-cli --cluster
create # 创建集群命令
--cluster-replicas 1 # 每个主节点,有一个从节点,代表--replicas 1
127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
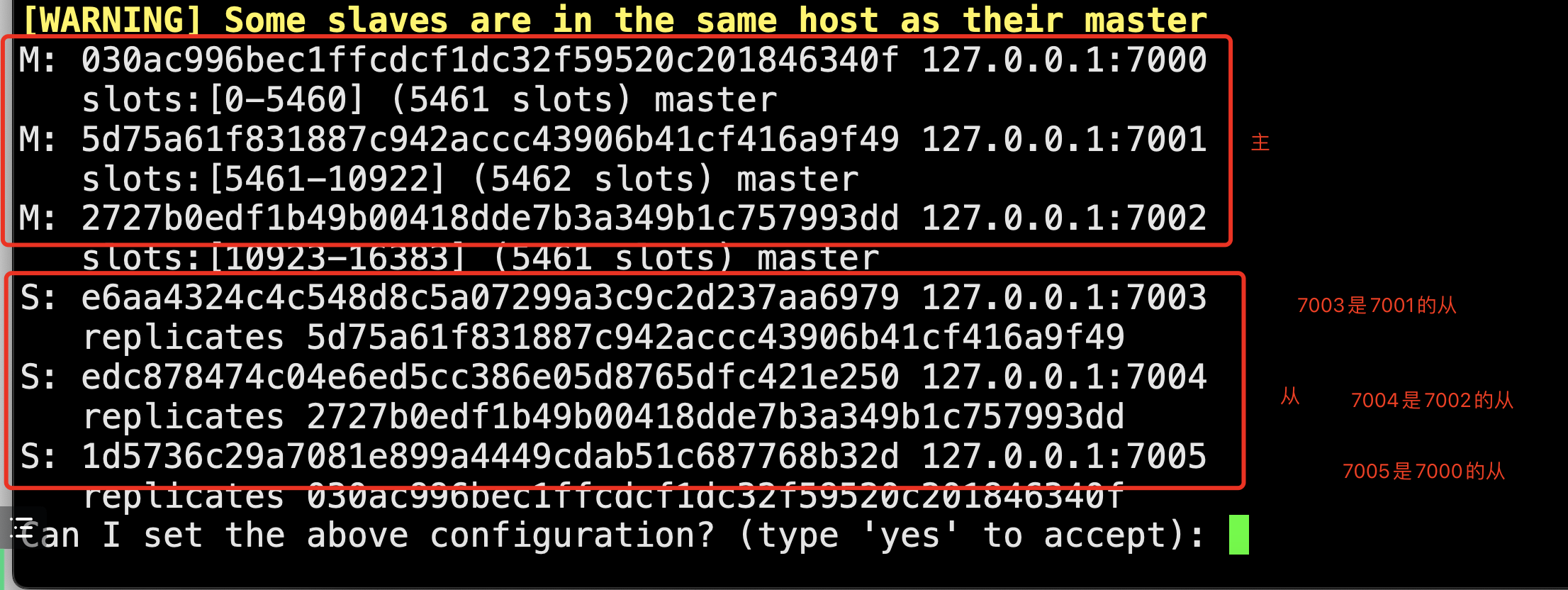
# # 集群自动分配主从关系 7000、7001、7002为主(M) 7003、7004、7005为从(S),
# 分好主库的槽了
7000M {0...5461}
7001M {5462...10922}
7002M {10923...16383}
################################################
# 6 演示,连接一个数据库
./src/redis-cli -c -p 7005
# 只能查看本节点中的数据,其他库中的数据,需要连接好所在的数据库才能查看,这种方式不好,需要使用集群模式连接
# -c,集群模式连接
./src/redis-cli -c -p 7005 # 自动找到不同节点,去操作数据(查值,放值)
# 7 故障转移
-把主库,7000停止--->7005从库--->升级为主库
-再启动7000,7000就变成了从库
ps aux |grep redis
kill -9 24537 # 杀死进程,shutdown是关闭进程,是需要进入进程中的
ps aux |grep redis
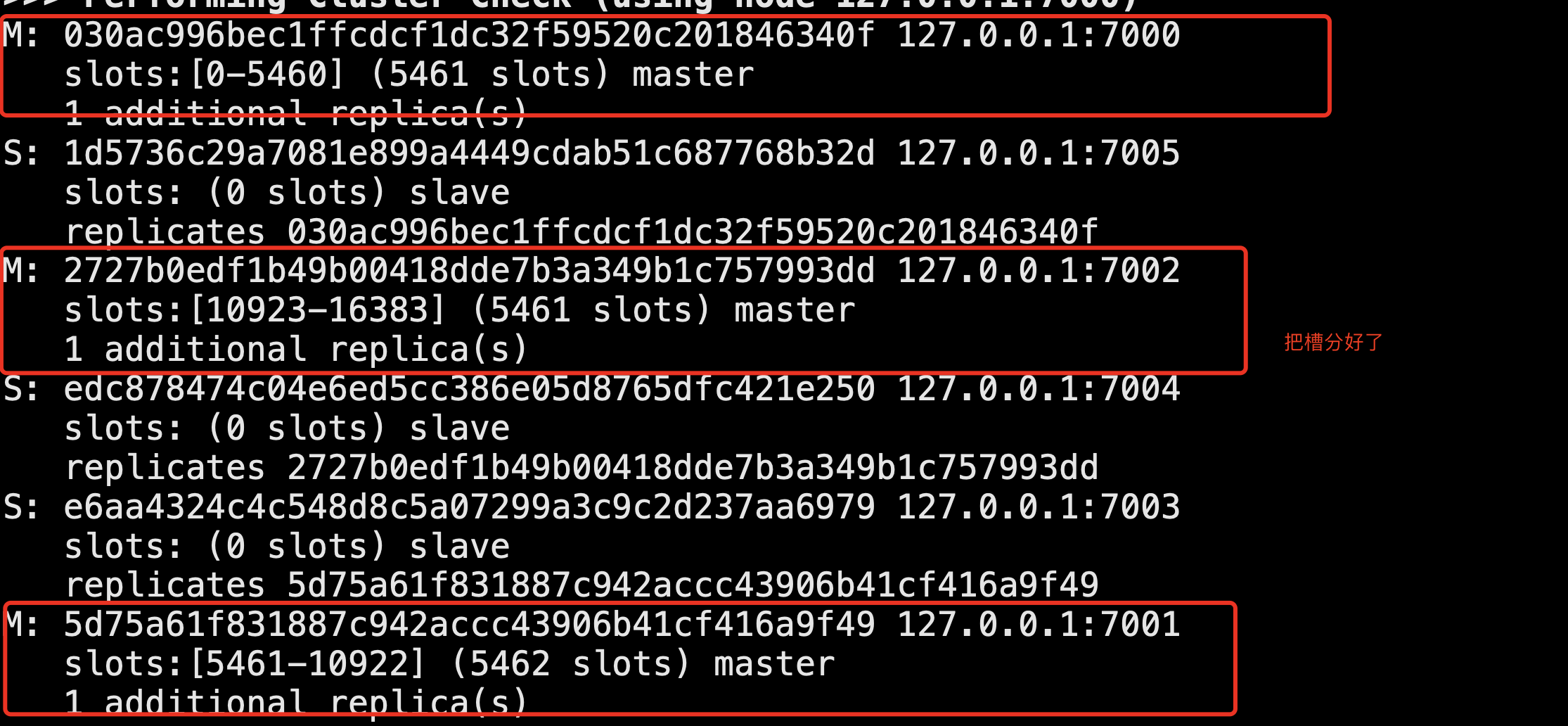
cluster nodes # 7000 fail,7005 master,此时还是可以对外提供服务,因为整个数据是完整的
./srcc/redis-sever ./redis-7000.conf # 把7000启动起来
cluster slave
四 python 操作集群
# rediscluster
# pip3.9 install redis-py-cluster
from rediscluster import RedisCluster
startup_nodes = [{"host":"127.0.0.1", "port": "7000"},{"host":"127.0.0.1", "port": "7001"},{"host":"127.0.0.1", "port": "7002"}]
# conn = RedisCluster(startup_nodes=startup_nodes,decode_responses=True)
conn = RedisCluster(startup_nodes=startup_nodes)
conn.set("foo", "bar")
print(conn.get("foo"))
五 集群伸缩
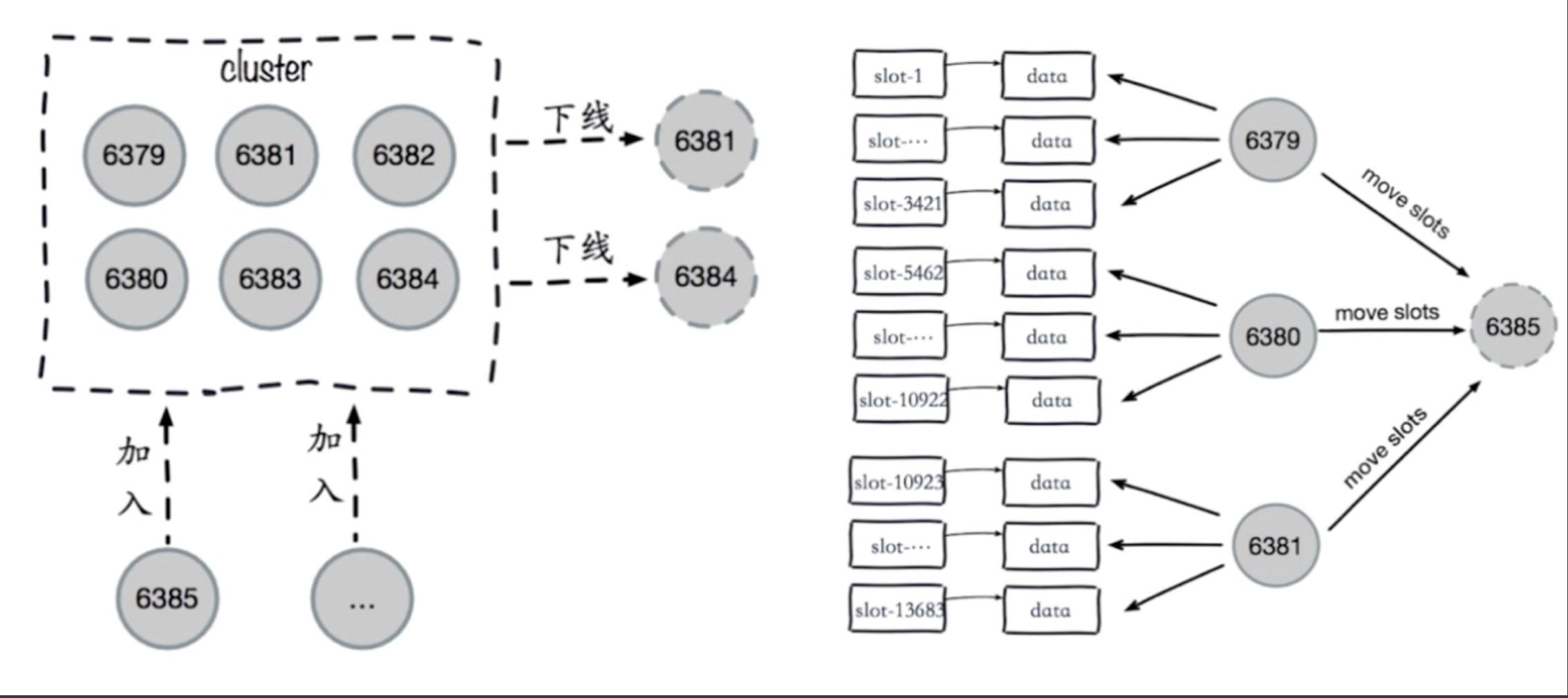
5.1 伸缩原理
# 加入节点,删除节点:槽和数据在节点之间的移动
5.2 集群扩容
# 6台机器,3个节点集群
# 8台机器,4个节点集群
# 1 准备两台机器
sed 's/7000/7006/g' redis-7000.conf > redis-7006.conf
sed 's/7000/7007/g' redis-7000.conf > redis-7007.conf
# 2 启动两台机器
./src/redis-server ./redis-7006.conf
./src/redis-server ./redis-7007.conf
# 查看集群配置,此时只有6个机器
cluster nodes
cluster info
# 3 两台机器加入到集群中去
./src/redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000
./src/redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7000
# 4 让7007复制7006
# 从redis客户端 -p 7007 cluster replicate 7006的id # replicate复制
./src/redis-cli -p 7007 cluster replicate e592233d38520ebd125de849ea69da3fe9482ac1
# 5 迁移槽
./src/redis-cli --cluster reshard 127.0.0.1:7000
# 希望迁移多少个槽:4096
# 希望那个id是接收的:7006的id
# 传入source id :all
# yes
# 6 查看集群状态
cluster nodes
5.3 集群缩容
# 第一步:下线迁槽
# 把7006机器的槽平均分成3份,迁移给剩下的3个机器
# --cluster-slots [分配slot大小] # slot槽
# 把7006的1366个槽迁移到7000上
redis-cli --cluster reshard --cluster-from 7006的id --cluster-to 7000的id --cluster-slots 1365 127.0.0.1:7000
yes
# 7006的1366 迁移给7001
redis-cli --cluster reshard --cluster-from baf261f2e6cb2b0359d25420b3ddc3d1b8d3bb5a --cluster-to 9cb2a9b8c2e7b63347a9787896803c0954e65b40 --cluster-slots 1366 127.0.0.1:7001
yes
# 7006的1366 迁移给7002
redis-cli --cluster reshard --cluster-from baf261f2e6cb2b0359d25420b3ddc3d1b8d3bb5a --cluster-to d3aea3d0b4cf90f58252cf3bcd89530943f52d36 --cluster-slots 1366 127.0.0.1:7002
yes
#第二步:下线节点 忘记节点,关闭节点
./src/redis-cli --cluster del-node 127.0.0.1:7000 要下线的7007id # 先下从,再下主,因为先下主会触发故障转移
./src/redis-cli --cluster del-node 127.0.0.1:7000 要下线的7006id
# 缩容就完成了,查看集群状态
cluster nodes
# 第三步:关掉其中一个主,另一个从立马变成主顶上, 重启停止的主,发现变成了从

 浙公网安备 33010602011771号
浙公网安备 33010602011771号