
redis高级用法:慢查询、pipline与事务、发布订阅、bitmap位图、HyperLogLog、GEO地理位置
目录
一 高级用法之慢查询
1.1 生命周期
配置一个时间,如果查询时间超过了我们设置的时间,我们就认为这是一个慢查询
配置的慢查询,只在命令执行阶段
客户端超时不一定慢查询,但慢查询是客户端超时的一个可能因素
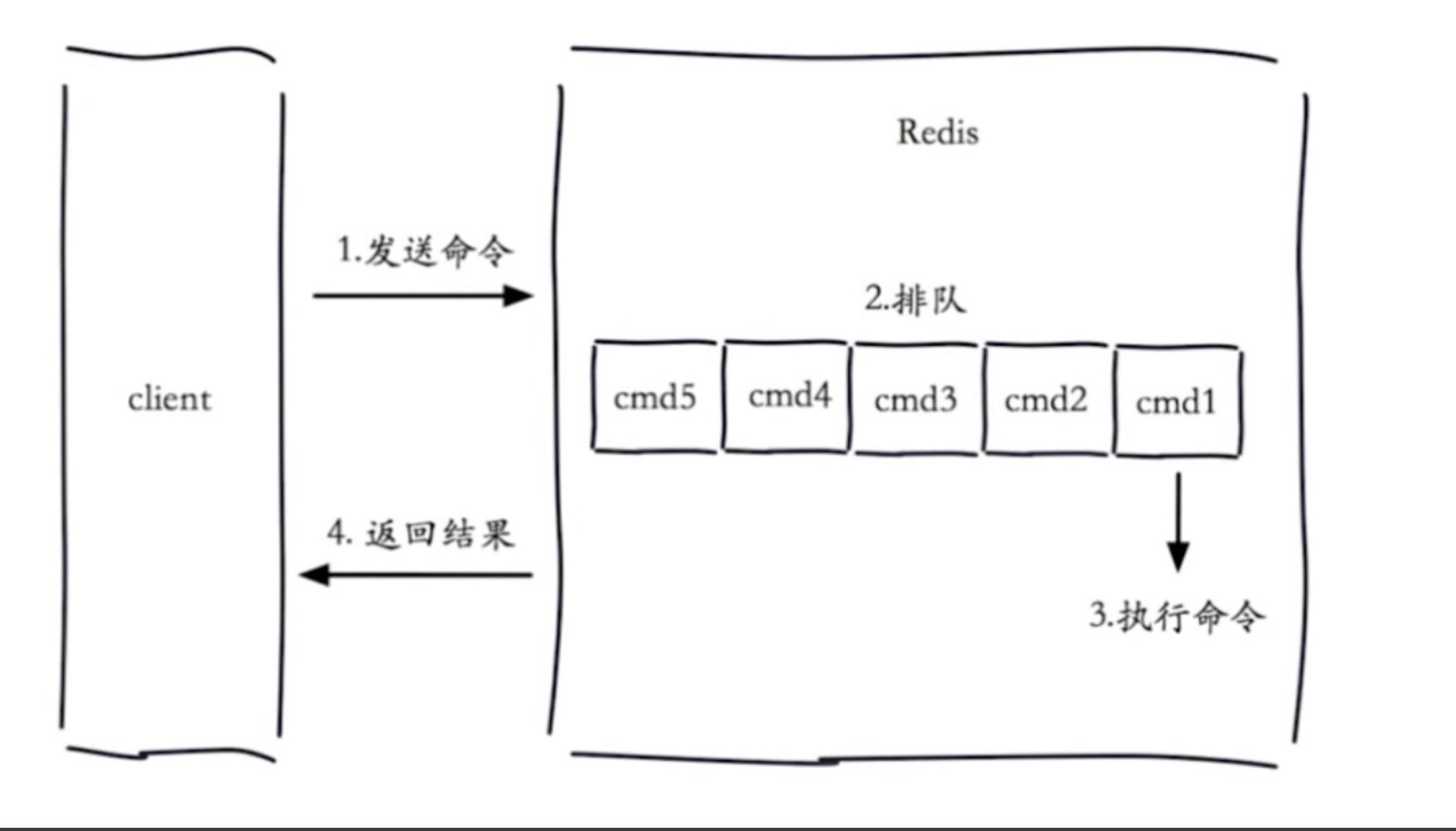
- 慢查询是一个先进先出的队列
- 固定长度
- 保存在内存中
1.2 两个配置
1.2.1 slowlog-log-slower-than
Redis 慢查询日志的时间阈值,单位微妙。
- 值为正数,执行时间大于该值设置的微秒时才记录到慢日志中。默认 10000 微秒。
- 值为负数,禁用慢查询日志。
- 值为 0,所有命令都记录到慢日志中
1.2.2 slowlog-max-len
慢查询日志长度,最小值为零。默认 128
当记录新命令并且当前慢日志已达到最大长度时,最旧的一条记录将被删除。
1.3 设置慢查询
# 慢查询演示
-设置慢查询--->只要超过某个时间的命令--->都会保存起来
# 设置记录所有命令
CONFIG SET slowlog-log-slower-than 0
# 最多记录100条
config set slowlog-max-len 100
# 持久化到本地配置文件
config rewrite
# 就会记录所有命令了
## 1.4 查看慢查询队列
```python
slowlog get [n]
slowlog len #获取慢查询队列长度
slowlog reset #清空慢查询队列
1.5 作用
# 有什么用,如何聊?
-公司好多项目用这一个redis实例
-最近公司发现,redis响应非常慢
-通过排查它的 慢查询-->排查出一些慢命令
-找到对应的执行项目--->位置
-避免再执行这些命令了
二 pipline与事务
2.1 什么是pipeline(管道)
Redis的pipeline(管道)功能在命令行中没有,但redis是支持pipeline的,而且在各个语言版的client中都有相应的实现
将一批命令,批量打包,在redis服务端批量计算(执行),然后把结果批量返回
1次pipeline(n条命令)=1次网络时间+n次命令时间
pipeline期间将“独占”链接,此期间将不能进行非“管道”类型的其他操作,直到pipeline关闭;如果你的pipeline的指令集很庞大,为了不干扰链接中的其他操作,你可以为pipeline操作新建Client链接,让pipeline和其他正常操作分离在2个client中。不过pipeline事实上所能容忍的操作个数,和socket-output缓冲区大小/返回结果的数据尺寸都有很大的关系;同时也意味着每个redis-server同时所能支撑的pipeline链接的个数,也是有限的,这将受限于server的物理内存或网络接口的缓冲能力
Redis 中的管道有什么用?
一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应。这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复。
这就是管道(pipelining),是一种几十年来广泛使用的技术。例如许多 POP3 协议已经实现支持这个功能,大大加快了从服务器下载新邮件的过程。
2.2 python客户端实现pipline
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
#创建pipeline
pipe = r.pipeline(transaction=True)
#开启事务
pipe.multi()
pipe.set('name', 'lqz')
#其他代码,可能出异常
pipe.set('role', 'nb')
pipe.execute() # 事务的执行
2.3 与原生操作对比
通过pipeline提交的多次命令,在服务端执行的时候,可能会被拆成多次执行,而mget等操作,是一次性执行的,所以,pipeline执行的命令并非原子性的
2.4 使用建议
1 注意每次pipeline携带的数据量
2 pipeline每次只能作用在一个Redis的节点上
3 M(mset,mget….)操作和pipeline的区别
2.5 原生redis操作操作事务
# 1 mutil 开启事务,放到管道中一次性执行
multi # 开启事务
set name lqz
set age 18
exec
# 2 模拟事务 mutil +watch 模拟事务 乐观锁
# 在开启事务之前,先watch
watch age
multi
decr age
exec
# 另一台机器
multi
decr age
exec # 先执行,上面的执行就会失败(乐观锁,被wathc的事务不会执行成功)
# django+mysql实现乐观锁
# 使用python+redis实现乐观锁
https://www.cnblogs.com/liuqingzheng/p/9997092.html
三 发布订阅
3.1 角色
# 发布者发布了消息,所有的订阅者都可以收到,就是生产者消费者模型(后订阅了,无法获取历史消息)
# 设计模式的:观察者模式
3.2 模型
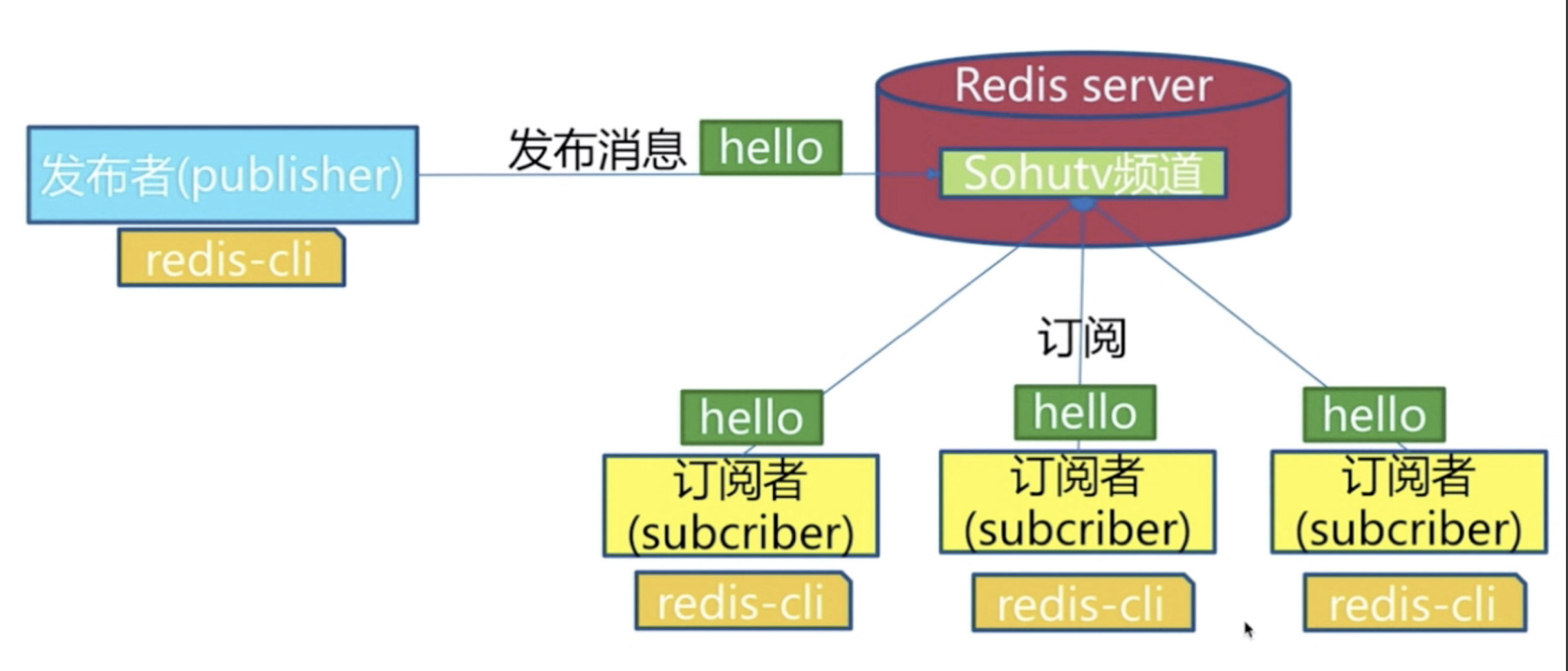
3.3 使用
# 发布消息,向lqz频道发送了hellowrold-->不会有人收到--->没有人订阅
publish lqz "hello world"
# 订阅消息客户端1
subscribe lqz
# 订阅消息客户端2
subscribe lqz
# 发布订阅和消息队列的区别
发布订阅,订阅者都能收到,
消息队列有个抢的过程,只有一个抢到
四 bitmap位图
4.1 位图是什么
位图是一种特殊的散列表。
申请一个大小为1亿、布尔类型(true或者false)的数组。将这1千万个整数作为数组下标,将对应的数组值设置成true。比如,整数5对应下标为5的数组值设置为true,也就是array[5]=true。
查询某个整数K是否在这1千万个整数中的时候,只需将array[K]取出来,看是否等于true。如果等于true,那说明1千万整数中包含这个整数K;相反,就表示不包含这个整数K。
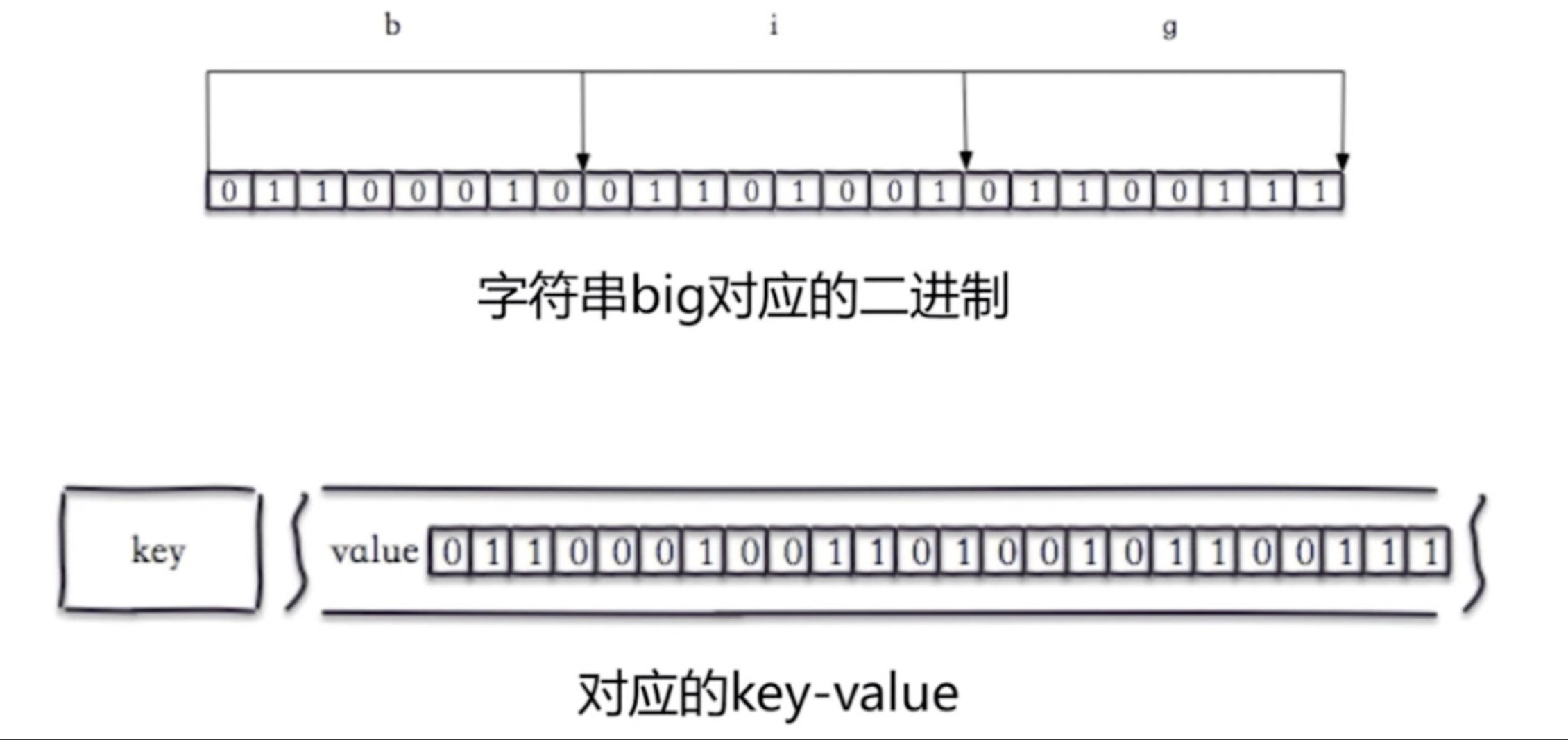
不过,很多语言中提供的布尔类型,大小是1个字节的,并不能节省太多内存空间。实际上,表示true和false,只需要一个二进制位(bit)就可以了。
下面是字符串big对应的二进制(b是98)
4.2 相关命令
# 操作 比特位
set hello big #放入key为hello 值为big的字符串
getbit hello 0 #取位图的第0个位置,返回0
getbit hello 1 #取位图的第1个位置,返回1 如上图
# 设置比特位
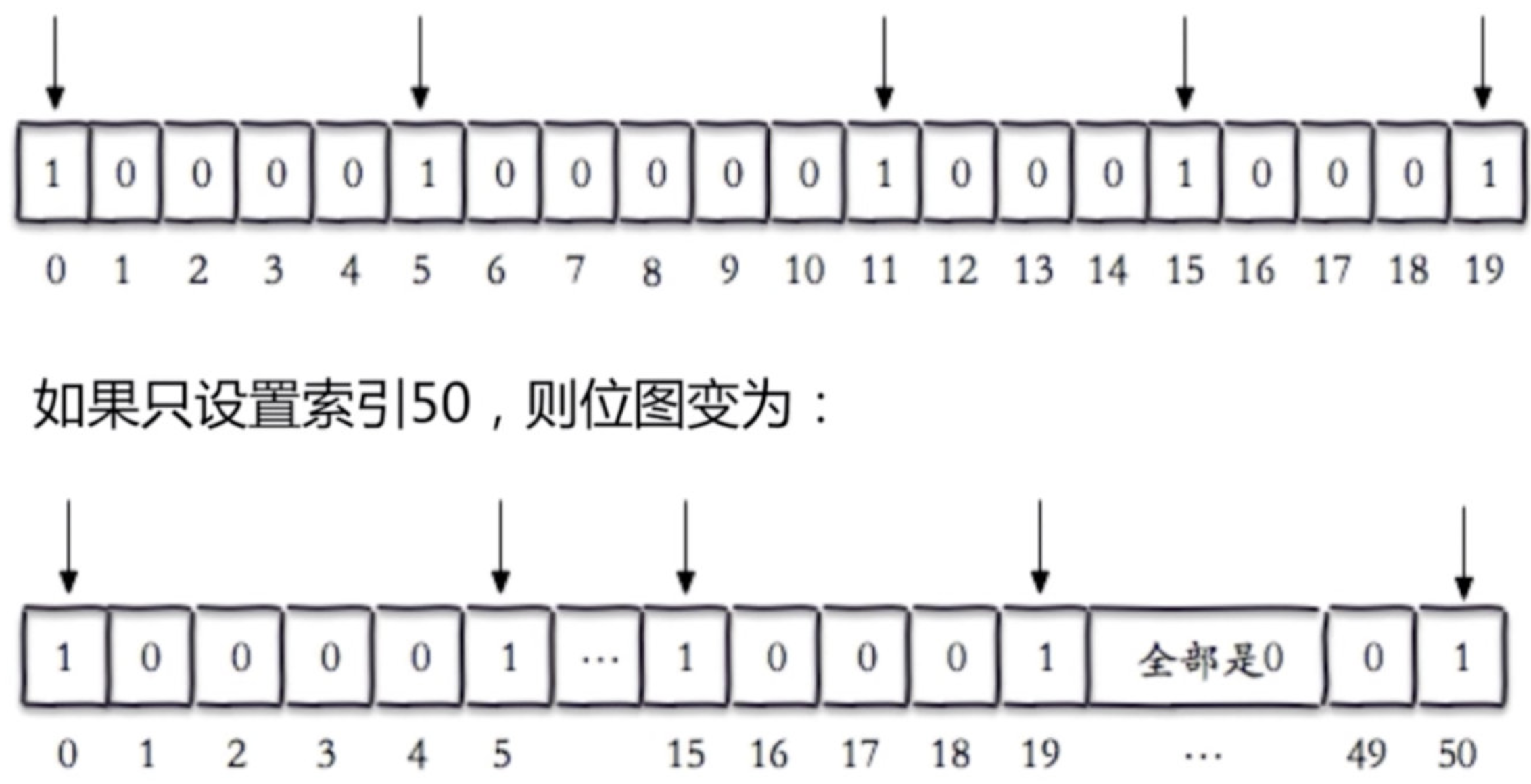
etbit hello 7 1 #把hello的第7个位置设为1 这样,big就变成了cig
# 获取指定字节范围内,有几个1
bitcount key 0 3 # 数字指的是字节
4.3 独立用户统计
-假设有1亿用户,假设5千万活跃--->统计日活
-使用集合:大约需要200m
-使用bitmap位图:大约需要12m内存
-如果活跃用户量少,不适合用bitmap
| 数据类型 | 每个userid占用空间 | 需要存储用户量 | 全部内存量 |
|---|---|---|---|
| set | 32位(假设userid是整形,占32位) | 5千万 | 32位*5千万=200MB |
| bitmap | 1位 | 1亿 | 1位*1亿=12.5MB |
# 面试题:
redis的key值最大多少 512M
redis的string 类型vaule值最大多少 512M
五 HyperLogLog
5.1 介绍
基于HyperLogLog算法:极小的空间完成独立数量统计
本质还是字符串
5.2 三个命令
# 基于HyperLogLog算法:极小的空间完成独立数量统计,去重
# 布隆过滤器
# 具体操作
pfadd uuids "uuid1" "uuid2" "uuid3" "uuid4" # 增加值
pfcount uuids # 统计个数
# 数据不能删除单个
# 跟集合很像,但是占的内存空间很小
百万级别独立用户统计,百万条数据只占15k
错误率 0.81%
无法取出单条数据,只能统计个数
# 作用:
-爬虫去重
-黑白名单
-垃圾邮件过滤
-独立用户统计
-有个用户登录,就把用户id放到HyperLogLog中
-最后只需要统计一下 个数 就能统计出今天的活跃人数
六 GEO地理位置信息
6.1 介绍
GEO(地理信息定位):存储经纬度,计算两地距离,范围等
# 类似于
-附近的人,餐馆,医院
-附近5km内的 xx
-我距离某个好友的距离
# 经纬度哪里来?
-前端(app,web),都是可以申请,获得经纬度的-->是前端做
-前端拿到--->调用我们的一个接口--->把经纬度传入--->存起来-->redis的geo中
-我要统计我附近5公里以内的好友
-需要我的经纬度
-我所有好友的经纬度,已经在 redis的geo中存好了
6.2 案例
geoadd cities:locations 116.28 39.55 beijing
geoadd cities:locations 117.12 39.08 tianjin
geoadd cities:locations 114.29 38.02 shijiazhuang
geoadd cities:locations 118.01 39.38 tangshan
geoadd cities:locations 115.29 38.51 baoding
# 计算两个地理位置的距离
geodist cities:locations beijing tianjin km
# 计算北京方圆 150km内的城市
georadiusbymember cities:locations beijing 90 km
# geo本质时zset类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号