drf-序列化(后篇)
目录
1 序列化高级用法之source(了解)
补充: on_delete参数
# on_delete:
1. CASCADE:级联删除,只要删除publish,跟publish关联的book,全都被删除
2. SET_DEFAULT:只要删除publish,跟publish关联的book,的publish字段会变成默认值,一定要配合default使用
3. SET_NULL:只要删除publish,跟publish关联的book,的publish字段会变成空,一定要配合null=True使用
4. models.SET(add):括号中可以放个值,也可以放个函数内存地址,只要删除publish,跟publish关联的book,的publish字段会变成set设的值或执行函数后函数的返回值
5. models.DO_NOTHING:什么都不做,但它需要跟db_constraint=False配合,表示不建立外键约束,创建逻辑外键,不是物理外键
# 不建立物理外键的好处?增删查改数据快
# 缺点:容易出现脏数据
# 实际工作中,都不建立物理外键,都是建立逻辑外键。只要在限制脏数据的录入就行。
| on_delete的值 | 表现 |
|---|---|
| on_delete=None | 删除关联表中的数据时,与models.CASCADE相同 |
| on_delete=models.CASCADE | 删除当前子表数据,与之关联的所有数据全部删除 |
| on_delete=models.DO_NOTHING | 删除当前子表数据, 不进行任何改变 |
| on_delete=models.PROTECT | on_delete=models.DO_NOTHING |
| on_delete=models.SET_NULL | 删除当前子表数据, 关联的数据变为null(前提需要null=True) |
| on_delete=models.SET_DEFAULT | 删除当前子表数据,, 关联的值设置为默认值(前提需要default='默认数据') |
| on_delete=models.SET(执行对象) | 删除关联数据,使用执行对象的返回值 |
source的三种用法
-1 修改前端看到的字段key值---> source指定的必须是对象的属性
book_name = serializers.CharField(source='name')
-2 修改前端看到的value值,---> source指定的必须是对象的方法
表模型中写方法
def sb_name(self):
return self.name + '_sb'
序列化类中
book_name = serializers.CharField(source='sb_name')
-3 可以关联查询(得有关联关系)
publish_name = serializers.CharField(source='publish.name')
代码:
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
# 写的这些字段类的名字,必须是book对象中的属性,所以book_name会报错
# 如果不想报错,使用source指定book对象中的属性
# 第一种用法:放一个对象的属性
book_name = serializers.CharField(source='name') # 给前端看到的是 book_name
# name = serializers.CharField(source='name') # 坑,会报错
name1 = serializers.CharField() # 同一个字段,可以序列化多次,但一般不会写
price = serializers.CharField()
# 第二种用法:放一个对象的方法 book.hhh_name()--->真正的书名_hhh
name = serializers.CharField(source='hhh_name')
# 第三种:关联查询,拿出出版社的名字
publish_name = serializers.CharField(source='publish.name')
2 序列化高级用法之定制字段的两种方式(非常重要)
# 方式一:在序列化类中写
1 写一个字段,对应的字段类是:SerializerMethodField
2 必须对应一个 get_字段名的方法,方法必须接受一个obj,返回什么,这个字段对应的value就是什么
# 方式二:在表模型中写
1 在表模型中写一个方法(可以使用:property,也可以不使用),方法有返回值(字典,字符串,列表)
2 在序列化类中,使用DictField,CharField,ListField
表模型
from django.db import models
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.CharField(max_length=32)
# on_delete:
# CASCADE:级联删除,只要删除publish,跟publish关联的book,全都被删除
# SET_DEFAULT:只要删除publish,跟publish关联的book,的publish字段会变成默认值,一定要配合default使用
# SET_NULL:只要删除publish,跟publish关联的book,的publish字段会变成空,一定要配合null=True使用
# models.SET(add):括号中可以放个值,也可以放个函数内存地址,只要删除publish,跟publish关联的book,的publish字段会变成set设的值或执行函数
# models.DO_NOTHING:什么都不做,但它需要跟db_constraint=False配合,表示不建立外键约束,创建逻辑外键,不是物理外键
# 不建立物理外键的好处?增删查改数据快
#缺点:容易出现脏数据
# 实际工作中,都不建立物理外键,都是建立逻辑外键
publish = models.ForeignKey(to='Publish', on_delete=models.DO_NOTHING, null=True,db_constraint=False)
authors = models.ManyToManyField(to='Author')
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
phone = models.CharField(max_length=11)
# 本质就是ForeignKey,但是唯一,多的一方唯一,形成了一对一
author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE)
class AuthorDetail(models.Model):
email = models.CharField(max_length=32)
age = models.IntegerField()
2.1 方式一
序列化类中用SerializerMethodField定制+get_字段名方法
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.CharField()
# 拿出出版社的id和名字和addr,放到一个字典中
# 方式一:SerializerMethodField来定制,如果写了这个,必须配合一个方法get_字段名,这个方法返回什么,这个字段的值就是什么
publish_data = serializers.SerializerMethodField()
def get_publish_data(self, book_obj):
print(book_obj) # 要序列化的book对象
return {'publish_name': book_obj.publish.name, 'publish_addr': book_obj.publish.addr}
# 练习:拿出所有作者的信息--> 多条 [{name:,phone:},{}]
author_data = serializers.SerializerMethodField()
def get_author_data(self, book_obj):
lst = []
for author in book_obj.authors.all():
lst.append({'name': author.name, 'phone': author.phone, 'email': author.author_detail.email})
# 这里数据一定要对应上,录入了几个作者就要录入几个作者详情
# AuthorDetail matching query does not exist.
# 我通过作者查询作者详情,出错是我自己少录入了一个作者详情,整个查询都会报错
return lst
2.2 方式二
序列化类:DictField()/ListField()
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.CharField()
# 方式二:用DictField()/ListField()来定制,
# 必须到表模型中写一个方法,方法名必须跟 自定义的字段名 相同的方法名,这个方法返回什么,这个字段的value就是什么
publish_data = serializers.DictField()
author_data = serializers.ListField()
表模型中:跟自定义的字段名相同的方法名
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.IntegerField()
publish = models.ForeignKey(to='Publish', on_delete=models.SET_NULL, null=True)
authors = models.ManyToManyField(to='Author')
def hhh_name(self):
return self.name + '_hhh'
@property
def publish_data(self):
# print(self) # 当前的book对象
return {'id': self.publish.pk, 'name': self.publish.name, 'addr': self.publish.addr}
def author_data(self):
lst = []
for author in self.authors.all():
lst.append({'name': author.name, 'phone': author.phone, 'email': author.author_detail.email})
return lst
3 多表关联反序列化保存
# 序列化和反序列化,用的同一个序列化类
-序列化的字段有:name,price , publish_detail,author_list
-反序列化字段:name,price ,publish,author
# 如果:
只序列化,加个参数:read_only=True
只反序列化,加个参数:write_only=True
既要序列化,又要反序列化:不需要加参数
3.1 反序列化之保存
视图类
class BookView(APIView):
def post(self, request):
ser = BookSerialzier(data=request.data)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '成功'})
else:
return Response({'code': 100, 'msg': ser.errors})
序列化类
# 序列化类,即做序列化,又做反序列化,还做数据校验
class BookSerializer(serializers.Serializer):
# 即用来做序列化,又用来做反序列化
name = serializers.CharField(max_length=8, min_length=2)
price = serializers.CharField()
# 使用方式二的DictField()/ListField()来自定义字段定制
# 这俩,只用来做序列化,展示给前端的数据
publish_data = serializers.DictField(read_only=True)
author_data = serializers.ListField(read_only=True)
# 这俩,只用来做反序列化,接收前端的数据,Book类中的字段
# 出版社,form显示的是下拉框,前端传过来的数据是出版社id
publish_id = serializers.IntegerField(write_only=True)
# 作者,是多对多关系,用户可能选择多个,form显示的是复选框,前端传过来的也是作者id,是[1,2,3]形式
authors = serializers.ListField(write_only=True)
def create(self, validated_data): # {name:西游记,price:88,publish:1,authors:[1,2]}
# book = Book.objects.create(**validated_data) # 这样会出错,因为上述数据是两张表中的数据
# 执行上述命令的真实情况如下:
# book = Book.objects.create(name=validated_data.get('name'),price=validated_data.get('price'),publish_id=validated_data.get('publish'),authors=validated_data.get('authors'))
# 操作方式1:
# book = Book.objects.create(name=validated_data.get('name'), price=validated_data.get('price'), publish_id=validated_data.get('publish'))
# book.authors.add(*validated_data.get('authors'))
# 操作方式2:
authors = validated_data.pop('authors')
book = Book.objects.create(**validated_data)
book.authors.add(*authors)
return book
3.2 反序列化之修改
视图类
class BookDetailView(APIView):
def put(self, request, pk):
book = Book.objects.filter(pk=pk).first()
ser = BookSerializer(instance=book, data=request.data)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '修改成功', 'data': ser.data})
else:
return Response({'code': 100, 'msg': ser.errors})
序列化类
class BookSerializer(serializers.Serializer):
# 即用来做序列化,又用来做反序列化
name = serializers.CharField(max_length=8, min_length=2)
price = serializers.CharField()
# 使用方式二的DictField()/ListField()来自定义字段定制
# 这俩,只用来做序列化,展示给前端的数据
publish_data = serializers.DictField(read_only=True)
author_data = serializers.ListField(read_only=True)
# 这俩,只用来做反序列化,接收前端的数据,Book类中的字段
# 出版社,form显示的是下拉框,前端传过来的数据是出版社id
publish_id = serializers.IntegerField(write_only=True)
# 作者,是多对多关系,用户可能选择多个,form显示的是复选框,前端传过来的也是作者id,是[1,2,3]形式
# 针对于authors的检验,使用字段的参数是不好检验的,可以使用局部钩子来检验
authors = serializers.ListField(write_only=True)
def update(self, instance, validated_data):
# {"name":"西游记11","price":98,"publish_id":2,"authors":[2]}
authors = validated_data.pop('authors')
for item in validated_data:
setattr(instance, item, validated_data[item])
instance.authors.set(authors)
instance.save()
return instance
4 反序列化字段校验其他
# 视图类中调用:ser.is_valid()---> 触发数据的校验
-4层
-字段自己的:max_length,required。。。
-字段自己的:配合一个函数name = serializers.CharField(max_length=8,validators=[xxx]) # 可以在类的外面定义一个xxx函数,但不常使用
-局部钩子
-全局钩子
5 模型类序列化器:ModelSerializer
# 之前写的序列化类,继承了Serializer,写字段,跟表模型没有必然联系
class XXSerialzier(Serializer)
id=serializer.CharField()
name=serializer.CharField()
XXSerialzier既能序列化Book,又能序列化Publish
总结
# 现在学的ModelSerializer,表示跟表模型一一对应,用法跟之前基本类似
1 写序列化类,继承ModelSerializer
2 在序列化类中,再写一个类,必须叫
class Meta:
model=表模型
fields=[] # 要序列化的字段
3 可以重写字段,一定不要放在class Meta类下,要跟class同一级
-定制字段,跟之前讲的一样
4 自定制的字段,一定要在fields中注册一下
5 class Meta: 有个extra_kwargs,为某个字段定制字段参数
6 局部钩子,全局钩子,完全一致
7 大部分情况下,不需要重写 create和update了
代码
class BookSerialzier(serializers.ModelSerializer):
# 第一个好处,不用一个个写字段了,把表模型中得字段映射过来
class Meta:
model = Book # 指定表模型
# fields='__all__' # 把表模型中所有字段都映射过来
fields = ['name', 'price', 'publish_detail', 'author_list', 'publish', 'authors'] # 自定制的字段,一定要在这里注册一下
extra_kwargs = {
'name': {'max_length': 10, 'required': True},
'publish': {'write_only': True},
'authors': {'write_only': True}
}
# 自定制字段:publish_detail author_list 写法有两种,跟之前一模一样
# 序列化使用
publish_detail = serializers.DictField(read_only=True)
author_list = serializers.ListField(read_only=True)
# 反序列化新增
# 全局钩子和局部钩子,跟之前完全一样
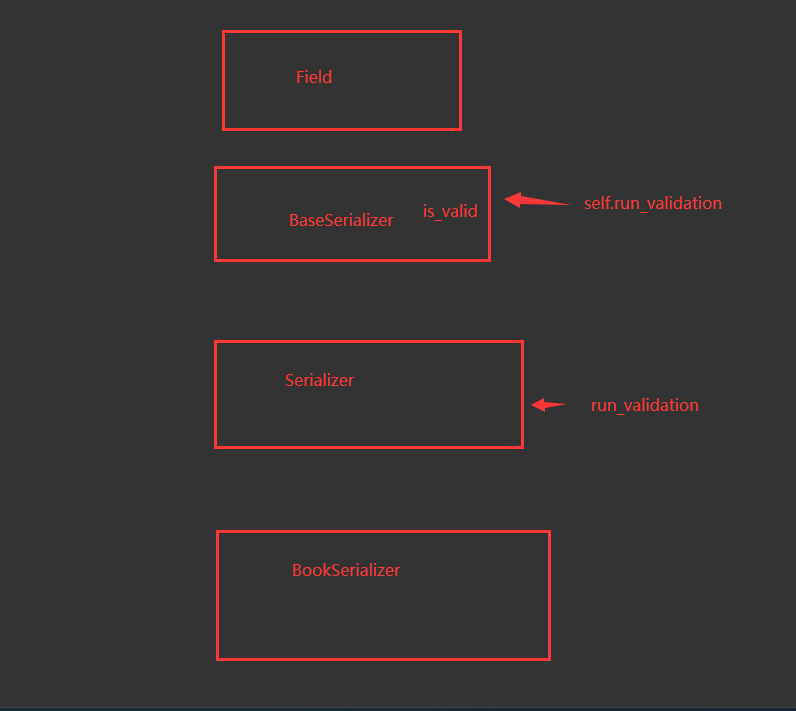
6 反序列化校验源码分析(了解)
# 序列化类的校验功能
-局部钩子:必须 validate_字段名
-全局钩子: validate
# 入口:
-ser.is_valid 才做的校验---> 入口
-BookSerializer ---> 继承了Serializer ---> 继承了BaseSerializer (Base中的is_valid方法) ---> 继承了Field
-BaseSerializer中的is_valid 方法
def is_valid(self, *, raise_exception=False):
# _validated_data是 ser.validated_data
# self中没有_validated_data,只有执行完is_valid后,才会有校验过后的数据
if not hasattr(self, '_validated_data'):
try:
# 核心 ---> 这一句
# 想看它的源代码,按住ctrl+鼠标点击是不对的---> 只能找当前类的父类
#但它真正的执行是,从根上开始找
self._validated_data = self.run_validation(self.initial_data) # *****
# self._validated_data就是经过校验过后的数据字典
except ValidationError as exc:
self._validated_data = {}
self._errors = exc.detail # _errors是错误字典
else:
self._errors = {}
if self._errors and raise_exception:
raise ValidationError(self.errors)
# 返回布尔值
return not bool(self._errors)
# self.run_validation(self.initial_data),不能按住ctrl+鼠标点点击,要从根上开始找
-Serializer的run_validation方法
def run_validation(self, data=empty):
# 局部钩子
# value是经过了局部钩子的字段字典
value = self.to_internal_value(data)
try:
# 全局钩子,所以我们的全局钩子的方法名必须是validate
value = self.validate(value) # BookSerializer中只要你写了写了,优先执行你写的
except (ValidationError, DjangoValidationError) as exc:
raise ValidationError(detail=as_serializer_error(exc))
return value
# self.to_internal_value(data)
-从根上找:是Serializer类中的方法
def to_internal_value(self, data):
for field in fields: # fields序列化类中写的一个个的字段类的对象列表
# 第一个field是name对象,field.field_name字符串 name
# self是谁的对象:序列化类的对象,BookSerializer的对象 validate_name
# 能拿到就给validate_method
validate_method = getattr(self, 'validate_' + field.field_name, None)
try:
# 字段自己的校验规则
validated_value = field.run_validation(primitive_value)
if validate_method is not None: # 如果validate_method有值(函数的内存地址)
# 局部钩子
# 就会加括号执行自己序列化类的这个validate_字段名方法,并把经过校验的字段传入进去(这就是为什么局部钩子一定要写个参数的原因)。返回给validated_value
validated_value = validate_method(validated_value)
except ValidationError as exc:
# 字段有异常,就会把{异常字段:异常详细}放到errors中
errors[field.field_name] = exc.detail
except DjangoValidationError as exc:
errors[field.field_name] = get_error_detail(exc)
except SkipField:
pass
else: # try中正常执行后,执行else,try有错误不会执行else
set_value(ret, field.source_attrs, validated_value)
if errors:
raise ValidationError(errors)
return ret # 校验过后的数据字典
# 总结:
-ser.is_valid ---> 走局部钩子的代码 ---> 是通过反射获取BookSerializer中写的局部钩子函数,如果写了,就会执行 ---> 走全局钩子代码 ---> self.validate(value)--->只要序列化类中写了,优先走自己的。
-ser.is_valid()进入 ---> 此时的self没有被校验过后的数据 ---> 走self.run_validation(self.initial_data)在Serializer类中 ---> 局部钩子的代码self.to_internal_value(data) ---> 在Serializer类中 ---> 是通过反射获取BookSerializer中写的局部钩子函数,先赋值给validate_method变量 --->走字段自己的检测 ---> 通过了,执行局部钩子并把检测后的字段当参数传入 ---> 走全局钩子代码 ---> self.validate(value)--->只要序列化类中写了,优先走自己的 ---> 最终,run_validation返回经过了所有检测的字段字典。is_valid返回布尔值。
写在类中得方法,只要写了,就会执行,不写就不执行。这种理念叫做面向切面编程(AOP)。例如:
- 在程序的前期,中期,后期插入一些代码来执行
- 装饰器:实现aop的一种方式
- 钩子函数:实现aop的一种方式
还有一种编程理念是:面向对象编程(OOP)
7 序列化组件源码部分分析
many参数的作用
# 序列化类实例化的对象有不同情况,目前只是这两种,后期可以自己定义
-如果传了many=True,序列化多条----> 得到的对象不是BookSerializer对象,而是ListSerialzier的对象中套了一个个的BookSerializer对象
-如果传了many=False,序列化单条---> 得到的对象就是BookSerializer的对象
-类实例化得到对象,是谁控制的?
__new__,是创建一个空对象
__init__是往里面赋值
-1 源码:BaseSerializer类中的__new__魔法方法
def __new__(cls, *args, **kwargs):
# 弹出many对应的值,没有many就返回False
if kwargs.pop('many', False):
return cls.many_init(*args, **kwargs)
return super().__new__(cls, *args, **kwargs)
-2 BaseSerializer类中的many_init方法
@classmethod
def many_init(cls, *args, **kwargs):
meta = getattr(cls, 'Meta', None)
# meta中没有list_serializer_class这个,就会产生ListSerializer
"""
在你的序列化类中就可以直接写个'list_serializer_class'指定Serializer类,这个可以做多条的反序列化
我们现在的反序列化只能修改或者更新一条
想要实现批量修改的方法:
方式一:for循环一个一个做修改
方式二:写个'list_serializer_class',批量修改
"""
list_serializer_class = getattr(meta, 'list_serializer_class', ListSerializer)
# ListSerializer加括号执行
# 就会是ListSerialzier的对象
return list_serializer_class(*args, **list_kwargs)
复习:pop的应用:
dict = {'a': 1, 'b': 2, 'c': 3}
res = dict.pop('a')
print(res) # 1
# res1 = dict.pop('d') # 没有这个key,会报错
res = dict.pop('d', False)
# 没有d,就输出第二个值
print(res) # False
# 字典中pop()的使用
1.括号中只有一个值,是字典的key,存在,弹出对应的value值。不存在,报错
2.括号中有两个值,第一个是字典的key,key存在,弹出对应的value值。key不存在,弹出第二个元素。
# 拓展
1.cpython解释器的源码:github中直接搜索cpython就行
2.django中的所有第三方模块都在contribe中,比如auth,session,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号